
 极市干货
极市干货

ICCV 2025 AFOG:当注意力机制成“内鬼”,巧妙瓦解目标检测Transformer

佐治亚理工团队提出AFOG,一种基于可学习注意力机制的对抗性攻击方法,成功提升大型目标检测Transformer模型攻击成功率最高达83%,同时扰动更小、更难察觉。
ICCV’25|ImageNet上实现 4 倍训练吞吐率!DC-AE 1.5:结构化 Latent 空间加速扩散模型收敛

5
框架,通过引入
结构化隐空间
和
增强扩散训练
两大关键技术,在保持高生成质量的同时,大幅加快扩
CVPR’25|一步推理高质量图像!用于蒸馏单步文生图扩散模型的时间无关统一编码器架构

本文提出时间无关统一编码器Loopfree,通过1步Encoder和4步Decoder实现单步推理的多步生成性能。克服了扩散模型所需几十步推理的问题,提高效率的同时保持高质量结果。
ICCV 2025 打造首个多模态视觉匹配数据集与评测基准,填补MLLM多模态视频匹配能力评测的空白

推出首个多模态视觉匹配基准 MMVMBench,系统揭示现有大模型在“识别同一个物体”任务中的能力短
尝试终结Attention Sink起因的讨论
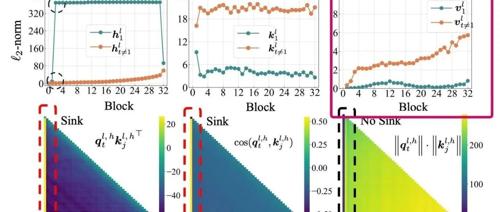
文章提出Transformer中的Attention Sink现象源于模型需要Context Aware的Identity Layer,即注意力块需在某些情况下保持恒等变换。该假设通过首个token的value接近0、深层解码更明显、非归一化注意力和门控机制消除sink等多个实验证据支持,并解释了这一现象的原因。
西湖 AGI Lab 发布 Detail++:多分支细节注入重塑复杂 Prompt 文生图体验

西湖大学 AGI Lab 推出 Detail++,无需训练即可显著提升复杂 Prompt 场景下的图文一致性与细节还原。通过分层子提示、渐进注入和注意力共享策略,Detail++ 能够有效避免属性溢出、错配及风格混合问题。
ICCV 2025 地平线联合多所高校提出 Epona:首个融合自回归与扩散的自动驾驶世界模型

地平线提出Epona,融合扩散与自回归模型,在单一框架下实现分钟级长视频生成、轨迹控制生成和实时运动规划。
模型权重、训练代码、数据集完全开源!BLIP3‑o:CLIP + Flow Matching,理解生成一条龙服务

解与生成两项功能在同一框架内统一支持。它采用了基于
CLIP 特征的 Diffusion Trans