


极市导读
武汉大学联合字节跳动推出首个多模态视觉匹配基准 MMVMBench,系统揭示现有大模型在“识别同一个物体”任务中的能力短板,并提出新方法 CoLVA,大幅提升GPT-4o等主流MLLM在视觉匹配任务中的准确率。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

Project Page:https://zhouyiks.github.io/projects/CoLVA/
Github:https://github.com/zhouyiks/CoLVA
Benchmark:https://github.com/open-compass/VLMEvalKit
E-mail:zhouyik@whu.edu.cn
亮点总结:
首次建立了面向多模态大语言模型(MLLM)视觉匹配任务的评测基准MMVMBench。
构建了高质量的MMVM数据集,包含22万组带有推理文本的视觉匹配问答对。
揭示了当前MLLMs存在的视觉匹配能力缺陷,并提供了一种简单但有效的方法来提高模型的视觉匹配能力。
本文提出评测的方法已经集成到了Open-Compass的官方测评中(https://github.com/open-compass/VLMEvalKit)。

1. 研究背景和动机
1.研究背景
近年来,多模态大语言模型在视觉感知、图文推理、图像问答和视觉定位等任务中取得了显著进展,得益于Qwen等大语言模型以及SigLIP等视觉编码器的发展。这些模型可以处理图像与文本之间的复杂交互,广泛应用于图像理解、视频分析、图文对话等场景。然而,视觉匹配(Visual Correspondence) 这一关键能力却鲜有被系统性研究。视觉匹配,即在不同图像中匹配“同一个物体”,是很多下游任务的基础,如目标跟踪、特征匹配和三维重建等。尽管MLLMs已经具备对物体外观和位置的识别能力(caption & grounding),但其在处理视觉匹配任务时仍显不足。以当前强大的MLLM GPT-4o为例,即便面对一些简单的视觉匹配问题,也常常出现明显错误。比如,图1中第一行的第三个案例查询目标(第一张图中青色轮廓标记)是一头黑色的牛,身体上有白色数字编号“1”,相对于另一头牛位于右侧;在第二张图中“1”号牛位于左侧,GPT-4o对该目标匹配错误。完成这个案例的视觉匹配可利用的最显著信息就是牛的编号,但是GPT-4o似乎没有捕捉到这一信息。图1中展示的更多的案例说明这类模型在“理解目标跨图像的一致性”方面存在本质缺陷。
2.研究动机
基于上述现象,我们的研究动机如下:
缺乏评估工具与数据集:当前没有系统性的benchmark来评估MLLMs在视觉匹配任务中的表现。因此,迫切需要构建一个专门面向视觉匹配的、具有挑战性的评估基准。
缺乏高质量监督数据:尽管MLLM具备一定的感知能力,但缺乏“如何使用这些感知信息进行匹配”的训练数据,导致它们无法有效执行该任务。也就是说,模型并不知道“看到了某些特征”之后应如何在图像间建立对应关系。
现有视觉编码器粒度不足:多数MLLM使用CLIP作为视觉编码器,但CLIP等主干缺乏对细粒度差异的建模能力,这限制了模型识别相似但不完全相同目标的能力。
为了解决上述出现的这些问题,我们:
-
构建了一个多图像视觉匹配评估基准(MMVMBench),覆盖15个开源视频数据集与网络视频,共1510个人工标注的样本;
-
提出一种自动标注流水线,构建22万条带有推理过程的匹配监督数据(MMVM Dataset);
-
并基于此提出了CoLVA方法,结合对象级对比学习与指令增强,显著提升了模型的视觉匹配能力
现在可以在https://github.com/open-compass/VLMEvalKit中方便地评估你的MLLMs的视觉匹配能力。
2. MMVM Dataset & Benchmark

在缺乏公开评估基准和高质量监督数据的背景下,研究团队提出并构建了MMVM Dataset & Benchmark,这是首个专门评估多模态大模型视觉匹配能力的数据集,系统性填补了MLLM视觉匹配能力的评测与训练空白。
团队从15个公开的视频分割与多视图跟踪数据集中采样,结合720条来自互联网的真实视频片段,最终构建了1510条人工精标的多图像匹配任务作为评估基准(Benchmark),见图2。每个任务包含多个图像、一个查询物体、若干候选目标,模型需从中判断“是否为同一物体”。这些样本覆盖了8种典型的匹配线索(如颜色、大小、相对位置、LOGO、绑定关系等),全面考察MLLM的跨图像匹配能力。
该基准显示,当前所有主流MLLM(包括GPT-4o、Claude 3、Qwen2-VL 等)在该任务中的表现普遍不佳,准确率均未超过50%,暴露出其在“视觉匹配”上的明显短板,也凸显了MMVMBench的重要性和挑战性。
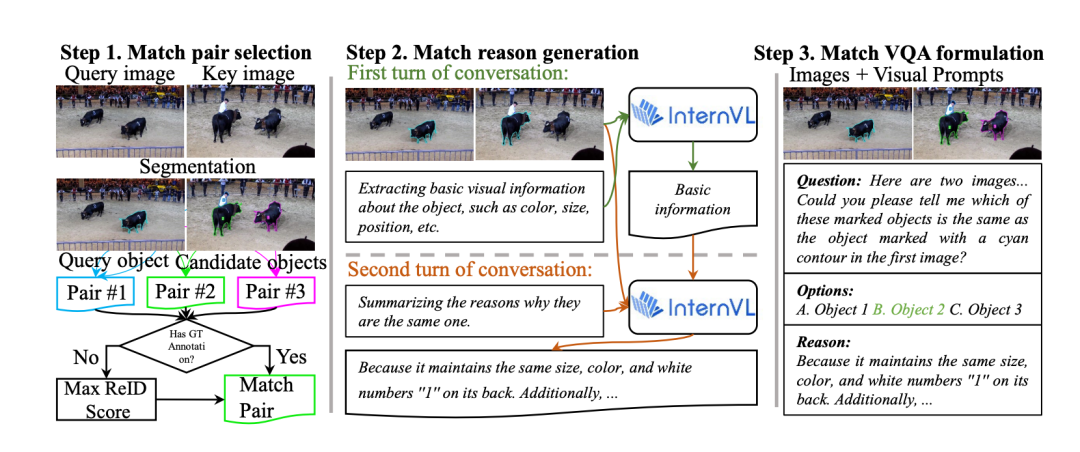
同时,我们还设计了一套自动化标注流水线,构建了包含22万条匹配QA对话数据的训练集(MMVM Dataset),见图三。这套流程分为三步:
匹配对选择:基于现有掩码标注和Re-ID算法构建查询-候选配对;
理由生成:利用强模型(如InternVL2-76B)自动生成匹配理由,包括颜色、姿态、编号等视觉线索;
多轮对话格式构建:将匹配任务组织成“选择-解释”两轮对话,使其更贴近真实多模态交互。
3. 方法设计
为解决当前多模态大模型在视觉匹配任务中存在的根本性缺陷,研究团队提出了全新方法 CoLVA(Contrastive Learning for Visual Alignment),专为提升MLLM的视觉匹配能力而设计。该方法在结构上引入两项关键技术创新,结合新的预训练与指令格式,显著突破了现有模型视觉匹配能力的上限。
1.识别问题根源,设计针对性技术路径
团队通过PCA分析(见图4)和定量实验证明,现有MLLM存在两大核心瓶颈:
-
缺乏与视觉对应任务对齐的数据监督——模型虽能识别颜色/位置等低阶属性,但不知如何用它们判断是否“为同一物体”;
-
视觉编码粒度不足——现有主干如CLIP难以捕捉区分度高的视觉细节,候选物体特征高度相似,导致模型难以精准对齐。

2.提出CoLVA方法,从根本上提升MLLM视觉匹配能力
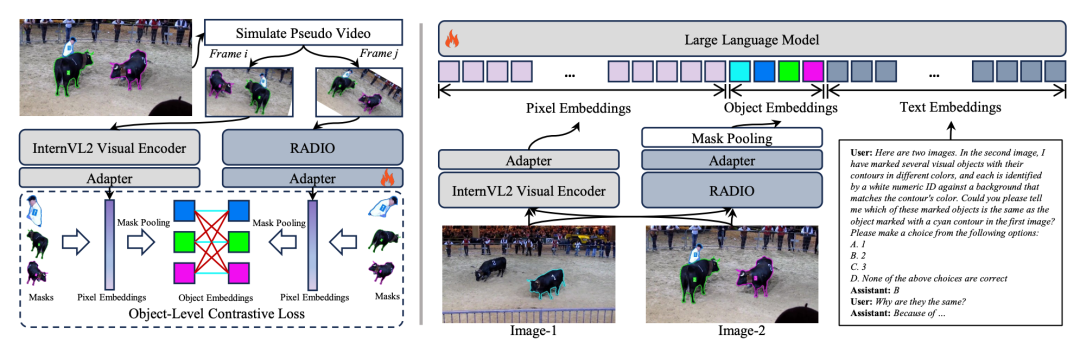
面对当前多模态大模型在视觉匹配任务上的系统性短板,研究团队提出了创新方法CoLVA(Contrastive Learning for Visual Alignment),以两个核心技术设计为支撑,从特征表达与训练机制双层面入手,显著提升MLLM对“同一物体”的理解与判断能力,见图5。
CoLVA的核心创新在于:
1️⃣ 对象级对比学习(Object-level Contrastive Learning, OCL)
CoLVA引入了一个精细视觉专家(RADIO),并与MLLM自身的视觉编码器形成对比学习框架。不同于传统图文对比学习,CoLVA将对象级语义特征作为对齐目标,使得模型能够学会区分外观极为相似的物体,提升辨别能力。
此外,为解决RADIO与主干视觉模型特征空间不一致的问题,CoLVA专门设计了预训练阶段,通过对比学习实现RADIO特征与MLLM语义空间的精确对齐,进一步增强细粒度视觉建模能力。
2️⃣ 指令增强策略(Instruction Augmentation, IA)
传统图文模型很难在标注图像中精准定位目标信息。CoLVA在微调阶段引入两种指令格式混合训练机制,包括:
常规“图像+文本描述”指令;
以及“对象级特征+文本”组合输入,支持梯度直接回传至对象视觉特征,显著提高模型在多目标精细识别中的训练效率与表现力。
3️⃣ 兼容与通用性
CoLVA被设计为通用插件式训练范式,可无缝集成至多个主流MLLM架构中,如 InternVL2、Qwen2VL、LLaVA 等,且在各类基线模型中均取得了大幅提升。例如,使用CoLVA后,InternVL2-4B在MMVMBench上准确率从17.62%跃升至45.83%,Qwen2VL-2B从15.69%跃升至47.48%,提升幅度极为显著。
4. 实验结果
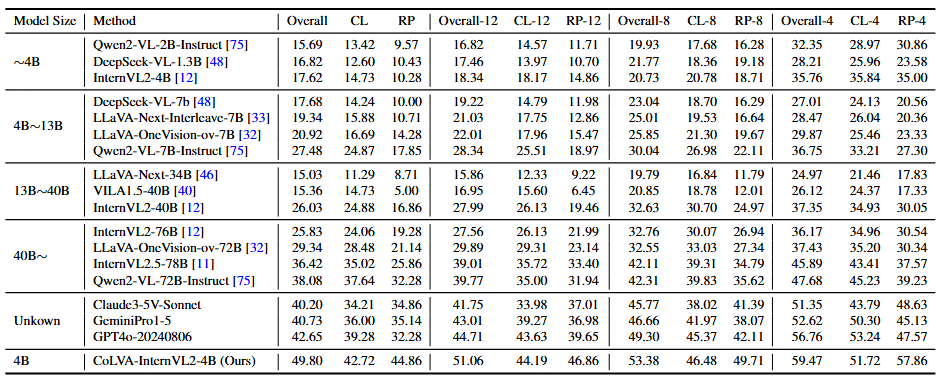
表格 1 MMVMBench评测结果。CL表示Color,RP表示Relative Position,是两种最主要的匹配线索。我们在这里报告在4种不同设置下的整体精度,CL精度和RP精度。这4种设置即4个候选目标,8个候选目标,12个候选目标以及全部目标。
表格 2 CoLVA对MLLM的单图VQA能力的影响。

表格 3 CoLVA对MLLM的多图VQA能力的影响。

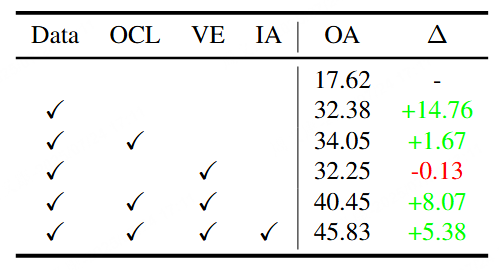
表格 4 CoLVA方法和MMVM数据有效性的消融实验。
表格 5 CoLVA方法在多种MLLMs上的有效性实验。
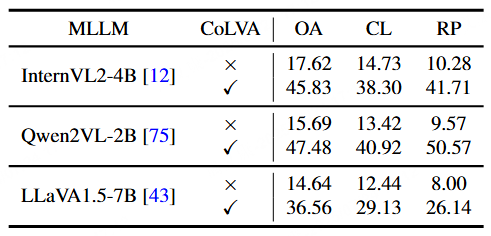
为验证所提出的MMVM数据与CoLVA方法的有效性,研究团队在多个主流多模态大模型上开展了系统性的实验评估。结果表明,CoLVA不仅显著提升视觉匹配能力,同时具备良好的泛化性与通用性,在多个关键任务上刷新性能记录。
1.MMVM Benchmark 实验结果:全面超越现有模型
在包含1510个真实视觉匹配样本的MMVMBench上,研究团队评估了30多个主流MLLM(涵盖开源与闭源模型),部分结果见表1,结果显示:
-
当前最强闭源模型GPT-4o准确率仅为**42.65%**,全部模型均未突破50%;
-
集成了CoLVA的InternVL2-4B模型准确率达到**49.80%,超越GPT-4o达7.15%,超越最强开源模型Qwen2-VL-72B达11.72%**,实现新SOTA;
-
CoLVA在主要匹配线索(颜色CL、相对位置RP)上的准确率也明显领先。
2.通用VQA能力无损,甚至进一步提升
CoLVA不仅强化了视觉匹配能力,而且在多个通用视觉问答(VQA)基准上表现稳定,甚至部分指标有所提升, 见表2和表3:
-
在MMBench、MME、POPE、BLINK、NaturalBench等多个VQA基准上,CoLVA模型表现与原始模型基本一致或略有增强;
-
说明CoLVA是一种有增益且不削弱原始的模型理解能力补强机制。
3.消融实验与泛化性分析:方法有效且稳健
进一步的消融实验验证了CoLVA中各个组件的独立价值,见表4:
-
单独使用MMVM数据可将准确率从17.62%提升至32.38%;
-
增加对象级对比学习(OCL)与精细视觉专家(VE)后进一步提升至40.45%;
-
最终加入指令增强(IA)后达成最佳结果45.83%,整体提升28.21个百分点;
CoLVA还可灵活集成至多种MLLM架构(如Qwen2VL-2B、LLaVA1.5-7B等),在所有模型中均带来大幅性能提升,验证其广泛可迁移性与通用性,见表5。
5. 结论和未来工作
展望未来:从基准出发,推动MLLM走向真正“看懂”世界
研究团队指出,当前多模态大模型(MLLM)虽然在图文对齐、描述生成等任务中表现出色,但在视觉感知的根基能力上仍不完善。本研究不仅首次提出并系统评估了“视觉匹配”这一被忽视的重要能力,也借助MMVMBench明确揭示出:即使是GPT-4o这类最先进模型,在匹配两个图像中同一物体时,仍频繁出错,准确率不足50%。
这一发现具有重要意义:它提醒整个多模态研究社区,在继续追求大模型“会说话”“能理解”的同时,更应注重其“看得准”的基本功训练。为此,研究团队将MMVMBench定位为未来MLLM模型不可或缺的能力评测维度之一,类似于VQA任务在早期对图文理解的驱动作用。
展望未来,研究团队提出两大关键方向:
-
更密集、更细致的视觉感知能力
模型应能理解更复杂的视觉细节,如远处物体、细长结构、物体部件等,从而支撑更可靠的匹配与理解。 -
更具区分性的视觉推理能力
模型需能够进行实例级对比与逻辑判断,不仅要看到“相似”,更要理解“不同”,实现真正的视觉对齐与语义推理闭环。
最终目标是帮助MLLM真正具备“看清楚、认得出、说得明白”的完整多模态智能能力。
(文:极市干货)