


极市导读
本文提出“时间无关统一编码器”Loopfree:用 1 步 Encoder 并行驱动 4 步 Decoder,实现单步推理即可达到多步扩散模型的画质与多样性,兼顾速度和质量,为实时文本生图带来新范式。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文地址:https://arxiv.org/pdf/2505.21960
代码链接:https://github.com/sen-mao/Loopfree
Background
生成任务最近2年已经获得了蓬勃的发展,尤其是基于扩散模型的开源图像和视频模型,包括图像生成模型StableDiffusion和视频生成模型CogVideoX。然而,这些模型的推理往往都需要几十步,这使得基于扩散模型的很多任务都是离线的,大大限制了扩散模型的使用。

扩散模型之所以需要几十步的推理步数,是因为其是一个逐渐加噪去噪的过程,如图所示,从右到左的训练过程是前向加噪过程,从左到右的采样过程是逐渐去噪过程,从高斯噪声逐渐去噪生成干净的图像,原始的扩散模型采用1000步的DDPM策略去噪。虽然后来提出非马尔可夫的DDIM采样策略,将采样步数降到50步,但这个过程仍然非常耗时,成为主要的效率瓶颈。


比如StableDiffusion生成一张512的图,采用DDPM 1000步采样需要37.6s,采用DDIM 50步采样也需要2.5s,50步生成一个视频则需要352s。

而相比于GANs,只需要一步采样,生成一张512图像仅需要0.02s。所以作者也同样希望Diffusion像GANs一样,用尽量少的步数进行采样,生成图像,甚至希望1步生成图像。

Analysis
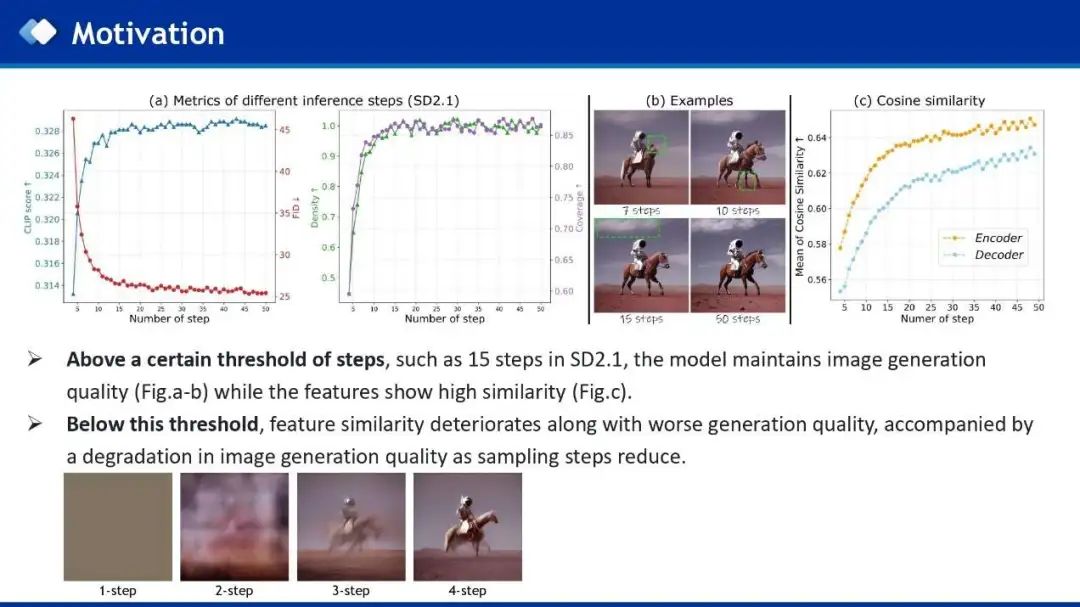
作者首先对StableDiffusion不同的采样步数进行分析,分析不同采样步数对生成结果的性能影响以及规律。作者发现:
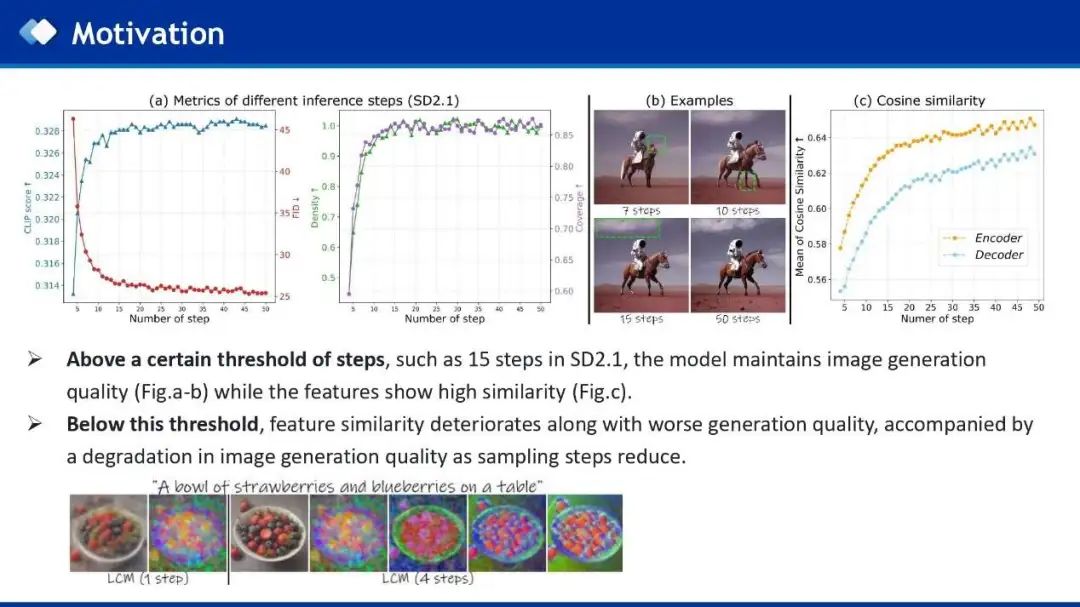
作者同样在已有的少步蒸馏模型上观察到这一规律,1步生成主要关注物体结构,当步数增加到4步时,会更多的关注图像纹理细节,生成更好的结果。
Method
基于以上分析的启发,作者使用了一种新颖的设计,1步Encoder和多步Decoder(也就是时间无关统一编码器架构),因为多步Decoder可以并行处理,从而实现了1步推理。由于多步Decoder能够捕获更丰富的语义信息,所以生成质量与多步DM保持一致。具体来说,因为最近主流的少步模型一般都是4步模型,所以作者采用1步Encoder和4步并行Decoder,来实现一步推理。
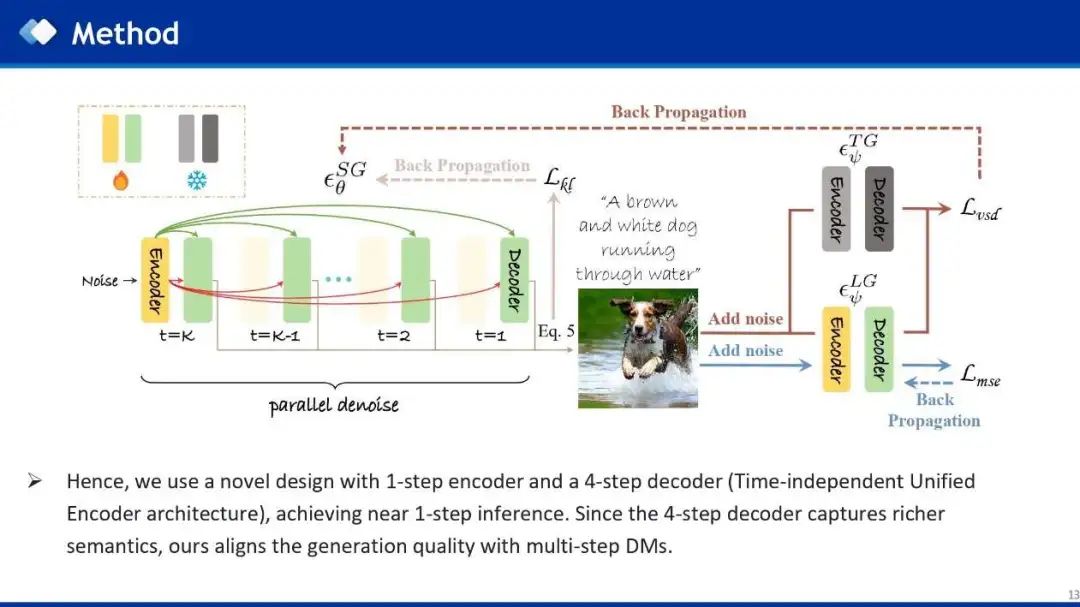
与现有的一步蒸馏模型相比,所提出的时间无关统一编码器架构具有以下优势:
-
现有的1-step蒸馏模型已经打破了扩散模型的denoise过程,直接从Noise生成图像,退化成了参数量更大的GANs,所以会面临一系列问题,比如生成质量和多样性问题。相比于1-step模型,时间无关统一编码器架构仍然遵循多步扩散模型的denoise采样策略,也就是多步去噪,所以可以继承原始多步模型更多的采样能力和特性。 -
现有的多步模型的推理效率远低于一步模型。相比于多步模型,本文的方法生成质量与多步模型对齐,而推理时间接近1步模型。
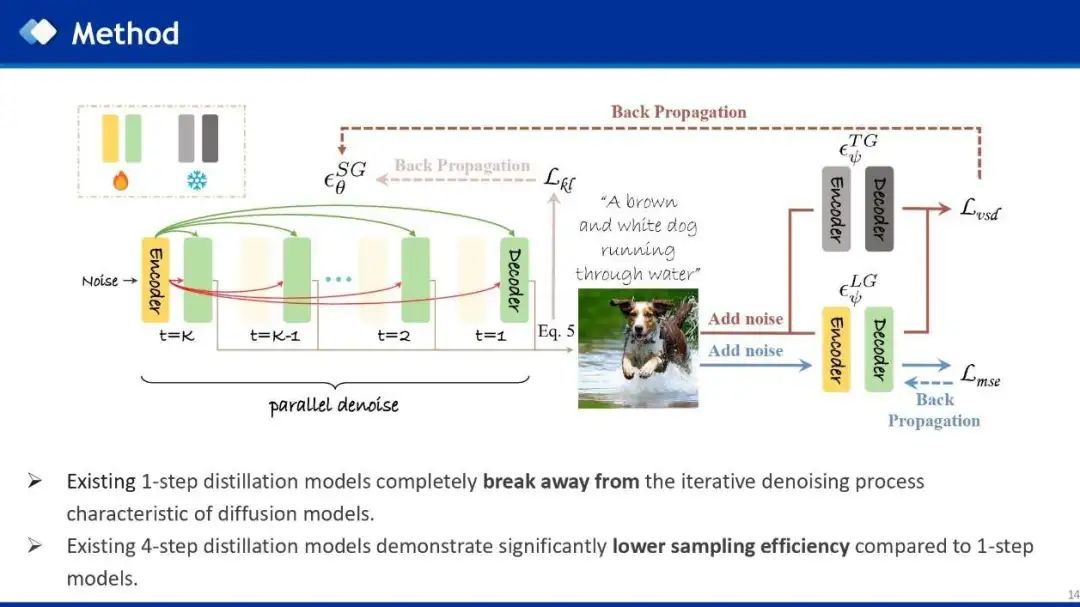
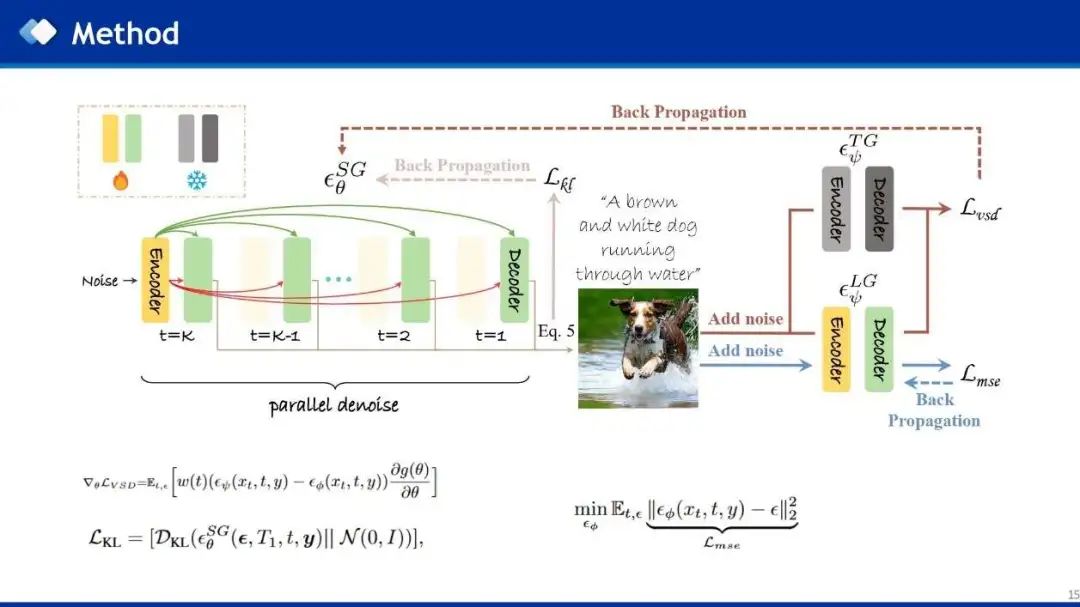
作者使用VSD loss进行蒸馏,只需要文本数据,而不需要真实图像。Student模型首先接收noise和文本提示作为条件输入,生成图像,然后使用一个可学习的多步LoRA-Teacher,结合diffusion loss来学习student的分布,然后使用vsd loss来将Frozen的多步Teacher和LoRA-Teacher的分布差异利用梯度反向传播给student模型,进而让student来学习多步Teacher模型的生成能力。此外,作者还使用KL loss来使student的预测噪声接近高斯,符合扩散模型预测噪声的先验条件。
Experiments
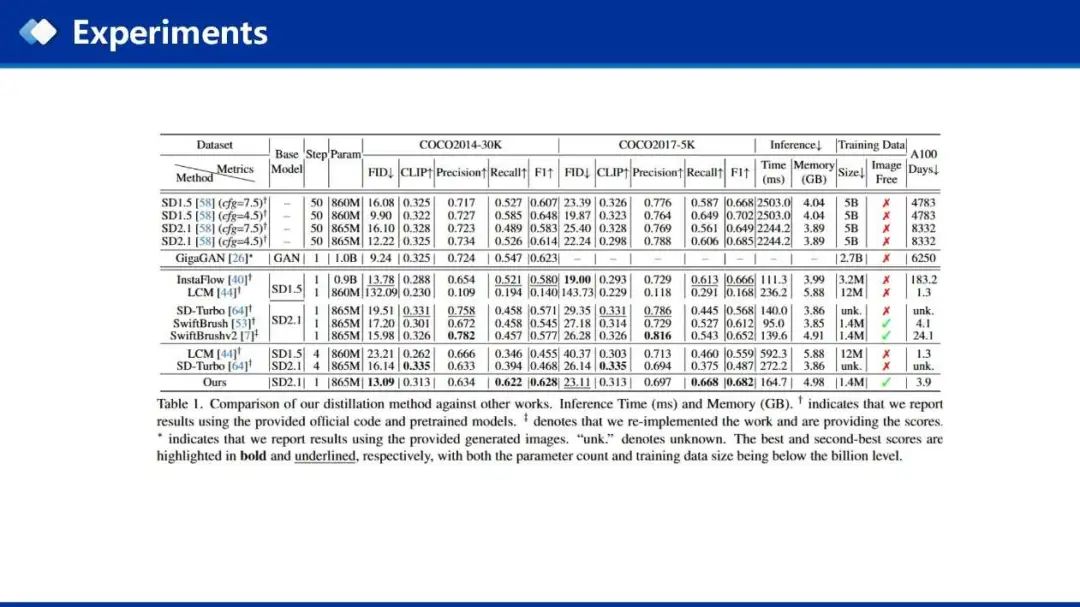
已有一步蒸馏模型在生成质量和多样性上存在问题,比如InstaFlow,LCM和SwiftBrush生成质量较差,SD-Turbo使用了Billions级别的文本图像数据集,可以生成高质量的图像,但缺乏多样性。与现有的一步模型相比,本文的方法在生成质量和多样性达到了平衡,更接近多步模型的性能。

在相同尺度的训练数据集设定下,本文的方法在COCO2014和COCO2017两个数据集上的指标上取得了目前最好的结果
作者在四个数据集上评测模型的多样性,主要使用Density和Coverage来进行评测,在多个数据集上均取得了综合最好的性能。
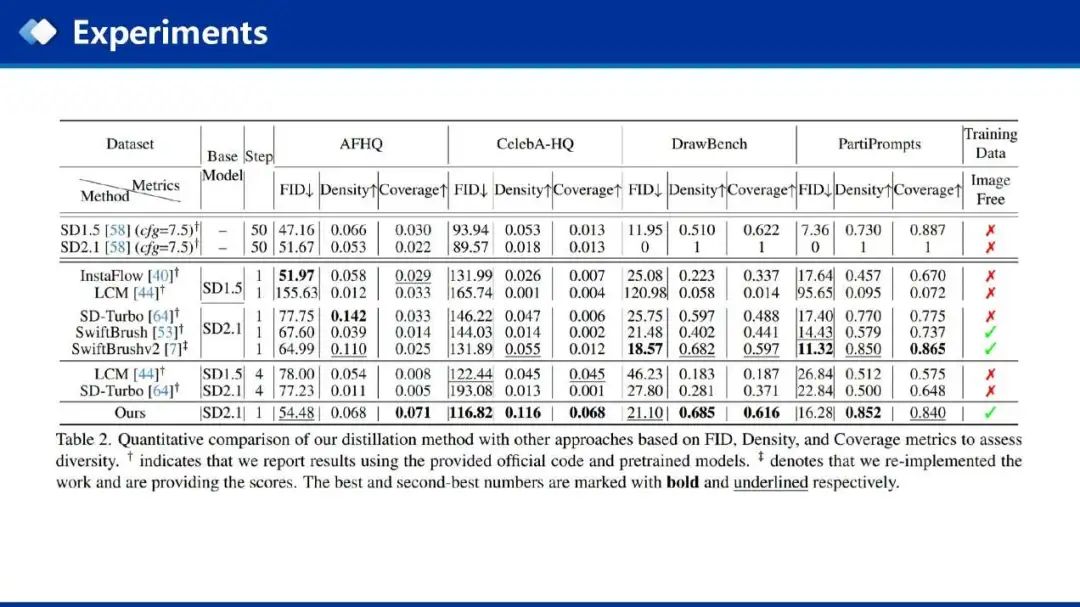
对于SD-Turbo的多样性,因为其在蒸馏时使用了SDS loss,SDS loss为每一个prompt学习了分布的均值,所以会导致多样性问题,而SwiftBrushv2由SDTurbo预训练模型初始化,所以会继承其多样性问题。而本文的生成结果更接近多步教师模型的质量和多样性。

此外,作者还发现,当蒸馏得到4步的预训练模型时,可以使用不同的步数进行采样,最然会带来轻微的伪影,但这就能够很方便的基于4步预训练模型,微调到其他步数,获得更好的性能。

Take Aways
-
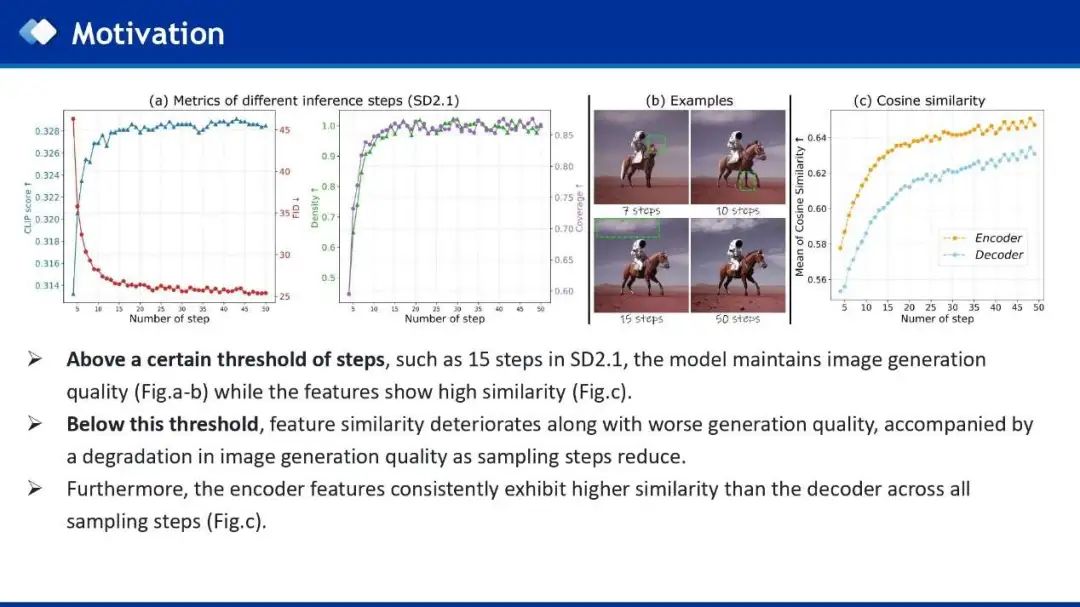
首先,作者通过分析,发现在多步扩散模型中,在一定步长阈值以下(例如,15步),图像生成质量会随着采样步长减少迅速下降。 -
在任意步长设置中,encoder特征始终表现出比decoder特征更高的相似性,所以decoder总是比encoder更重要。 -
基于以上分析,作者提出1步Encoder和4步Decoder的时间无关统一编码器架构,实现1步推理,多步生成性能。

(文:极市干货)