


极市导读
本文提出了 DC-AE 1.5 框架,通过引入结构化隐空间和增强扩散训练两大关键技术,在保持高生成质量的同时,大幅加快扩散模型收敛速度,并显著提升高分辨率生成效率。实验表明,该方法在 ImageNet 等数据集上实现了更快训练吞吐率与更优图像质量的双重突破。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 DC-AE 1.5:结构化 Latent 空间加速扩散模型收敛 (来自 NVIDIA)
1.1 DC-AE 1.5 研究背景
1.2 分析:不同 channel 下 Latent Space 的稀疏问题
1.3 结构化潜在空间
1.4 增强的扩散模型训练技术:加速收敛
1.5 实验设置
1.6 实验结果
太长不看版
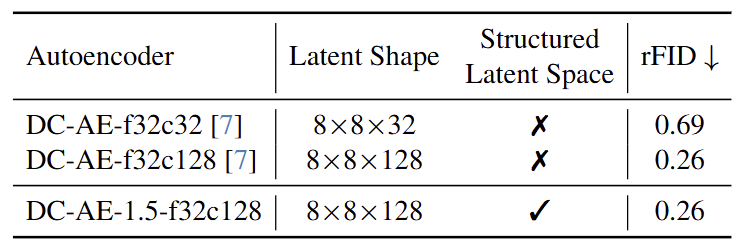
Deep Compression Autoencoder 需要很多 latent channel 维持重建能力,但会损害生成。DC-AE 1.5 应对这问题。
DC-AE 1.5 是用于高分辨率扩散模型的 Deep Compression Autoencoder。对于 Autoencoder 来说,增加其 channel 数对于提升重建质量很有效。但是,带来的消极影响是使得扩散模型收敛更慢,导致生成质量变差 (尽管重建质量变好)。这个问题就限制了 Latent 扩散模型的上界,也不利于高空间压缩比 Autoencoder 的使用。
本文提了两个技术来应对这个挑战:
-
结构化 Latent Space: 在 Latent 特征强加一种结构,让更前面的 latent channel 捕捉目标结构,更后面的 latent channel 捕捉图像细节。 -
一种增强的扩散模型训练技术: 对 object latent channel 使用额外的扩散训练目标,来加速收敛。
有了这些技术,DC-AE 1.5 比 DC-AE 提供了更快的收敛和更好的扩散缩放结果。在 ImageNet 512×512 上,DC-AE-1.5-f64c128 比 DC-AE-f32c32 提供了更好的图像生成质量,同时速度提高了 4 倍。
1 DC-AE 1.5:结构化 Latent 空间加速扩散模型收敛
论文名称:DC-AE 1.5: Accelerating Diffusion Model Convergence with Structured Latent Space (ICCV 2025)
论文地址:
https://arxiv.org/pdf/2508.00413
项目主页:
https://github.com/dc-ai-projects/DC-Gen
1.1 DC-AE 1.5 研究背景
潜在扩散模型 (Latent Diffusion Model, LDM)[1]已经成为高分辨率图像合成的主流范式。它利用 Autoencoder 将大小为 的图像投影到形状 的压缩 Latent 表征,降低了扩散模型的计算成本。扩散模型的输出在推理时被馈送到 Autoencoder,从 Latent 表征重建图像。
Autoencoder 的重建性能很重要,因其对整个图像生成的 Pipeline 设置了一个性能上限。提高 Autoencoder 重建质量的常用方法是增加其 Latent channel[2]。例如,图 1 显示了具有不同 Latent channel 的 Autoencoder 的 rFID。可以看到,如果从 c16 切换到 c128,rFID 始终随着潜在通道数的增加而提高,从 1.60 下降到 0.26。
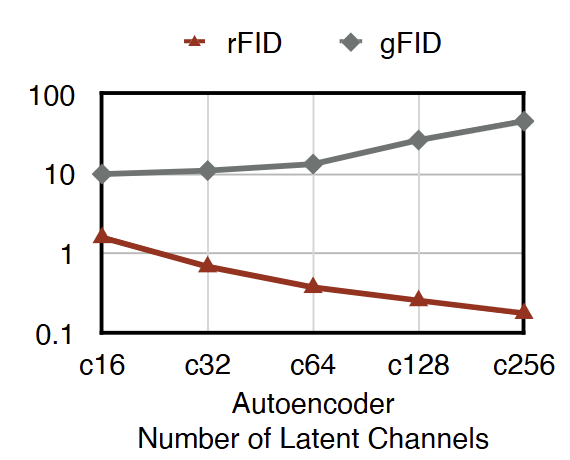
增加 Latent channel 数对于 Deep Compression Autoencoder[3]尤其重要,Deep Compression Autoencoder 通过增加 Autoencoder 的空间压缩比来加速 LDM,如图 2 所示。在高空间压缩比(例如 f64)下,深度压缩自动编码器必须使用较大的潜在通道数(例如 c128)来保持令人满意的重建质量。
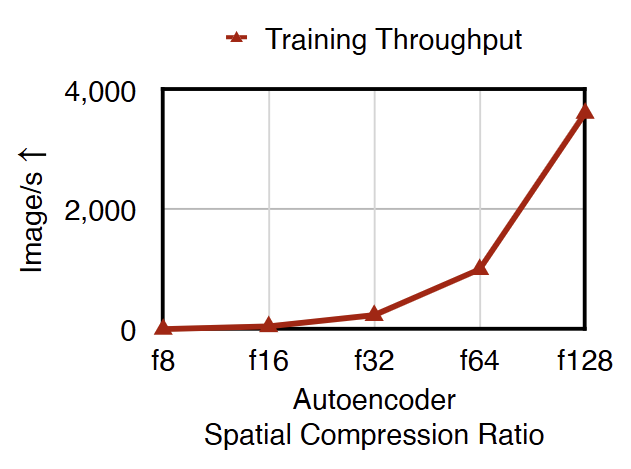
然而,使用较大的潜在通道数会显着减慢扩散模型的收敛性,导致 gFID 结果更差。例如,图 1 展示了具有不同潜在通道数的 DiT-XL gFID 结果。虽然 Autoencoder 的 rFID 不断提高,但 gFID 不断恶化。这个问题不仅限制了 LDM 的质量上限,而且限制了它的效率,因为它阻碍了使用具有高空间压缩比 (例如,f64) 的 Autoencoder。
1.2 分析:不同 channel 下 Latent Space 的稀疏问题
本文提出了 DC-AE 1.5,引入了两个关键创新来解决上述挑战。首先,作者分析了 Autoencoder 在不同 Latent channel 数下的 Latent Space。
作者可视化了不同的 Latent channel (c32, c64, c128 和 c256) 的 DC-AE-f32[3]的 Latent Space,分析为什么扩散模型在使用较大的 Latent channel 数时存在收敛速度慢的问题。
在图 3(a) 中,作者可视化了 Latent Space 的 channel-wise 平均特征的可视化。假设 latent 表征的维度是 ,作者计算 channel-wise 平均特征的方法是:
torch.mean(latent, dim=2)
可以看到,当 Latent channel 数从 c32 增加到 c256 的时,关于 Object 结构的信息变得更加稀疏。从完整的潜在空间可视化 (图 4) 中,作者发现这种现象是因为 f32c256 Autoencoder 包含:
-
许多 Latent channel 来捕获图像细节。 -
少数 Latent channel 负责捕获 Object 结构。
作者发现,当使用大量 Latent channel 时,Latent Space 存在稀疏问题,如图 3(a) 所示。它分配大部分 Latent channel 来捕获图像细节 (命名为:Detail Latent Channel),而捕获 Object 结构的 Latent channel (命名为:Object Latent Channel) 在整个 Latent Space 中变得稀疏。这种稀疏问题使得扩散模型更难学习对象结构,导致收敛速度慢的问题。


这个现象也是合理的,因为捕获更多的图像细节对于实现良好的重建质量至关重要。
但是,因为扩散模型对所有 latent channel 一视同仁,因此其很难区分整体 Object 结构和高频细节,使其无法有效地学习 Object 结构。
比如,作者在图 3(b) 中可视化了具有不同 Autoencoder (DC-AE-f32c32 → DCAE-f32c256) 的 DiT-XL 的图像生成结果。可以看到,随着 latent channel 数量的增加,扩散模型逐渐失去对结构相干性的控制,Object 结构存在严重的失真。相比之下,图像细节仍然很好。
基于这些发现,作者推测 Autoencoder 的 Latent Space 在 latent channel 很多时存在 Object 信息稀疏问题,如图 3 (a) 所示。这个稀疏问题使得扩散模型无法有效地学习 Object 结构,导致收敛缓慢。
1.3 结构化潜在空间
受研究结果的启发,本文提出了结构化潜在空间 (Structured Latent Space) 来帮助扩散模型将 Object Latent Channel 与 Detail Latent Channel 区分开来,以缓解稀疏性问题。它引入了一种基于训练的方法来对 Latent Space 施加特定结构:前面的 Latent channel 专注于捕获 Object 结构,而后面的 Latent channel 专注于捕获图像细节。

如图 5 所示,传统 Autoencoder 的 Latent Space 在 latent channel 维度没有结构,作者在 Latent Space 上设计和添加了一个 channel-wise 的结构。
具体来说,DC-AE 1.5 可以从部分 latent channel 重建图像 (例如,来自 c128 的前 16/32/64 个 channel)。例如,如图 5 所示,它首先专注于从前 16 个 latent channel 重建 Object 结构,并在包含更多 latent channel 时逐渐细化图像细节。相比之下,当给定部分 latent channel 时,传统的 Autoencoder (例如 DC-AE[3]) 不能很好地重建 Object 结构。
如图 6 和 7 所示,作者可视化了 DC-AE 和 DC-AE 1.5 之间的完整 Latent Space 比较。可以看到,DC-AE 1.5 的 Latent Space 中的 Object Latent Channel 和 Detail Latent Channel 出现了明显的分离,前面的 channel 作为 Object Latent Channel,前面的 channel 作为 Detail Latent Channel,但是这在 DC-AE 的 Latent Space 中是不存在的。


图 4 展示了本文 Autoencoder 训练策略来实现所需的 channel-wise latent space 结构。
设计的直觉是基于这样一个事实,即:当 Latent channel 数较小时,Autoencoder 的 Latent Space 自然更关注 Object 结构。因此,使用额外目标来增强原始 Autoencoder 训练目标,额外目标是:从部分 latent channel 重建输入图像。
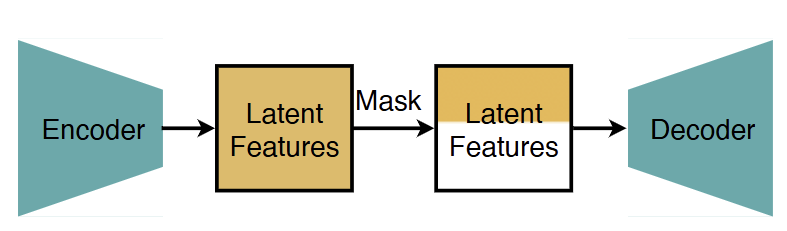
具体做法
Autoencoder 通过 Encoder ,将输入图像 映射到潜在特征 。通过 Decoder ,从 latent 特征预测图像 。
训练损失 用于监督 Autoencoder 的训练,它是 L1 Loss、Perceptual Loss 和 GAN Loss 的加权平均值。
当只选择 Latent Space 的前几个通道时,需要这个 Autoencoder 还能够重建图像。在实践中,通过在每个训练步骤中随机采样 latent channel 数( )来实现这一点,并生成掩码:
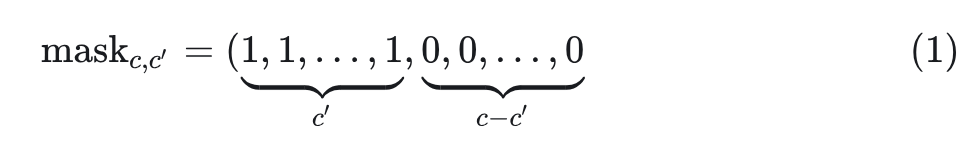
然后,作者使用修改后的损失 来更新 Autoencoder。
通过这种训练策略,Autoencoder 获得了这样的能力:在给定任何 Latent channel 数 的情况下重建图像,其 Latent Space 自然具有我们所需的通道结构。而且,这种训练策略对 Autoencoder 的重建质量影响是不大的。
如图 9 所示,为 DC-AE 和 DC-AE 1.5 之间的 rFID 比较。 DC-AE 1.5 在相同设置下实现了与 DC-AE 相同的 rFID,同时具有额外的 Latent Space 结构。
1.4 增强的扩散模型训练技术:加速收敛
其次,基于 Structured Latent Space,我们提出了增强扩散训练来解决收敛速度慢的问题。它引入了 Object Latent channel 的额外扩散训练目标,以加快扩散模型捕获 Object 结构的速度。
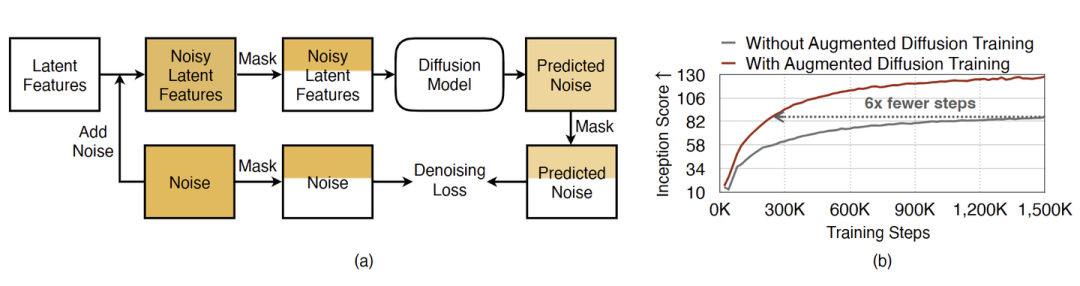
给定结构化的潜在空间,下一步是利用这种结构来加速扩散模型对 Object 结构的学习效率,以获得更好的收敛性。作者通过增强的扩散训练技术来实现这一点,如图 10 (a) 所示。增强的扩散训练技术的核心思想是:在 Object Latent Channel 上使用额外的目标显式增强扩散训练。
比如,考虑一个 Latent Diffusion Model 。给定 latent 特征 以及对应的带噪音的 latent 特征 ,去噪损失函数可以定义为: 。
在扩散模型的每个训练步骤中,随机采样一个 latent channel number ,并且利用式1中定义的对应的掩码 ,来修改 Diffusion 训练损失:
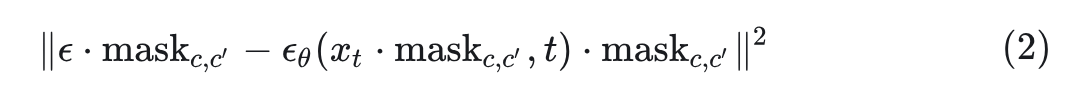
图 10 (b) 说明了在 ImageNet 256×256 上使用和不使用增强扩散训练的 UViT-H 训练曲线,可以看到,展示出了 6 倍更快的收敛,而且最终图像生成质量也更好了。
1.5 实验设置
作者使用 Pytorch 在 NVIDIA H100 GPU 上实现和训练模型。使用 FSDP 和 bf16 训练来减少训练时间和训练内存成本。最大的模型 (USiT-3B) 在 16 个 NVIDIA H100 GPU 上完成训练大约需要 5 天。
对于 Autoencoder 训练,作者遵循 DC-AE 中提出的相同训练策略,包括低分辨率全训练阶段、高分辨率潜在适应阶段和局部细化阶段。此外,还将 channel 结构添加到 Latent Space 中。本文的 Autoencoder 支持用 中的任何 latent channel 数进行重建,其中, c 是最大的 latent channel 数。
作者遵循与官方实现相同的训练设置,只将所有 DiT 和 SiT 模型的训练 Batch Size 从 256 增加到 1024,以增加 GPU 利用率。在实验中考虑了 4 个设置,包括 DiT[4]、UViT[5]、SiT[6]和 USiT[7]。除了现有的扩散模型外,我们还构建了一个更大版本的 USiT 来进行扩散模型缩放实验,深度为 56,隐藏维度为 2048,头部为 32。作者将此模型称为 USiT-3B。
1.6 实验结果
1) 加速扩散模型收敛
作者在相同的设置下将 DC-AE 1.5 与 DC-AE 进行比较 (ImageNet 256×256 的 f32c128 和 ImageNet 512×512 的 f64c128),以评估 DC-AE 1.5 的有效性。
图 11 总结了 ImageNet 256×256 上的 class-conditional image generation 结果。DC-AE-1.5-f32c128 不仅比 DC-AE-f32c128 收敛得更快,而且由于收敛性的提高,也会导致更好的图像生成质量。在所有设置下,它始终提供比 DC-AE-f32c128 更好的 gFID 和 Inception 分数。例如,在 UViT-H 上,它将 gFID 从 17.38 提高到 10.82,Inception 分数从 78.42 提高到 109.23。
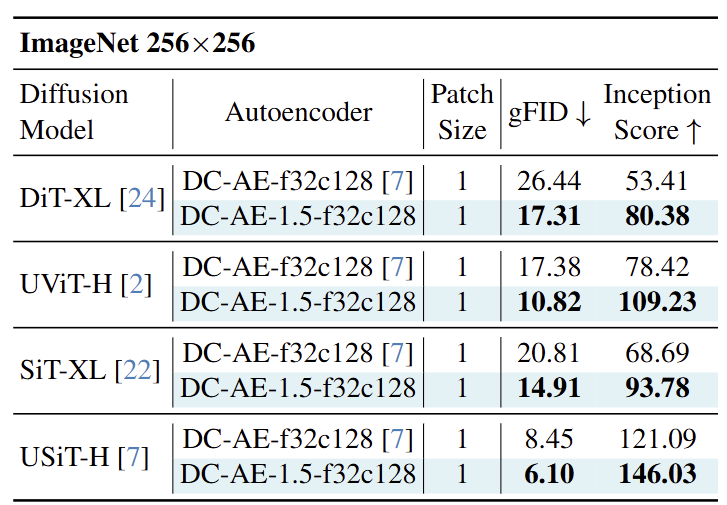
图 12 报告了 ImageNet 512×512 上的 class-conditional image generation 结果。结果与 ImageNet 256×256 上的结果一致。在所有情况下,DC-AE-1.5-f64c128 都优于 DC-AE-f64c128。这些结果再次证明了 DC-AE 1.5 在加速扩散模型收敛和提高 Autoencoder 图像生成质量方面的有效性。其中,我们目标使用很大的 latent channel 数 (例如 c128)。
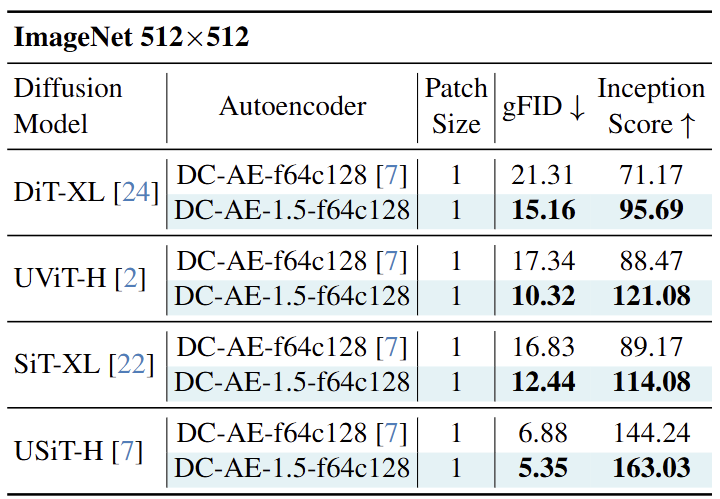
2) 改进扩散模型缩放曲线
现在可以使用 DC-AE 1.5 解决收敛速度慢的问题之后,那就有另一个想法是:通过使用具有更高 latent channel 数的 Autoencoder 来提高 LDM 的质量上限,以实现更好的图像重建质量。为了证明这一点,作者在 ImageNet 256×256 上使用 USiT 进行扩散模型缩放实验,并把结果报告在图 13 中。
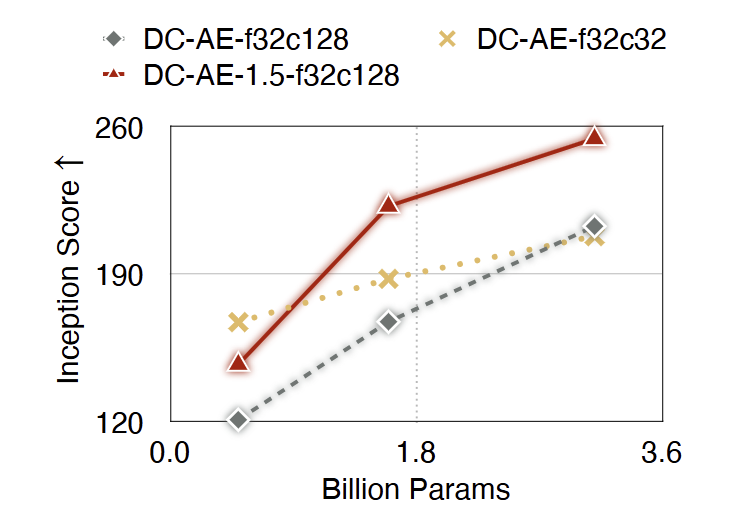
使用 DC-AE-f32c32,可以看到,由于 Autoencoder 的重建质量有限,缩放扩散模型的 Inception Score 的改进出现了饱和。相比之下,使用 DCAE-f32c128 缩放扩散模型带来了更显著的改进。但是,由于收敛缓慢,它的生成质量仍然不如 DC-AE-f32c32,直到模型被缩放到了 USiT-3B。
使用 DC-AE-1.5-f32c128,通过加速收敛,提升了缩放曲线。DC-AE-1.5-f32c128 在 USiT-2B 和 USiT-3B 上可实现比 DC-AEf32c32 更好的 Inception Score。
与 ImageNet 512×512 上最先进的图像生成模型的比较
除了提高 LDM 的质量上界之外,另一个令人兴奋的方向是:通过增加空间压缩率来提高效率,例如从 f32c32 到 f64c128。 DC-AE 1.5 对于 f64c128 这个设置来讲,对其图像生成结果有帮助,使其收敛更快。
作者在 ImageNet 512×512 上使用 DC-AE-1.5-f64c128 训练 USiT 模型 (USiT-2B),并将结果与最先进的扩散模型和自回归图像生成模型进行比较,如图 14 所示。
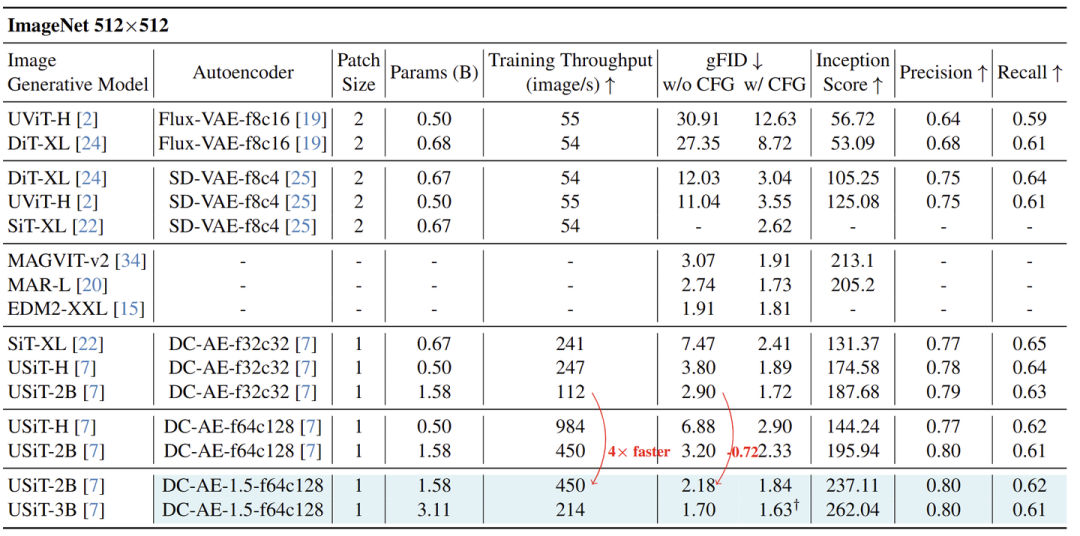
可以看到,使用 DC-AE1.5-f64c128,USiT-2B 以卓越的效率实现了具有竞争力的图像生成质量。在不使用 CFG 的情况下,它实现了 2.18 的 gFID,237.11 的 Inception Score,显著优于 DC-AE-f32c32+USiT-2B。更重要的是,它提供了比 DC-AE-f32c32+USiT2B 更高的 4 倍的训练吞吐量。图 17 展示了图像生成示例,与其他在 ImageNet 上训练的生成模型相比,显示出具有竞争力的视觉质量。
消融实验
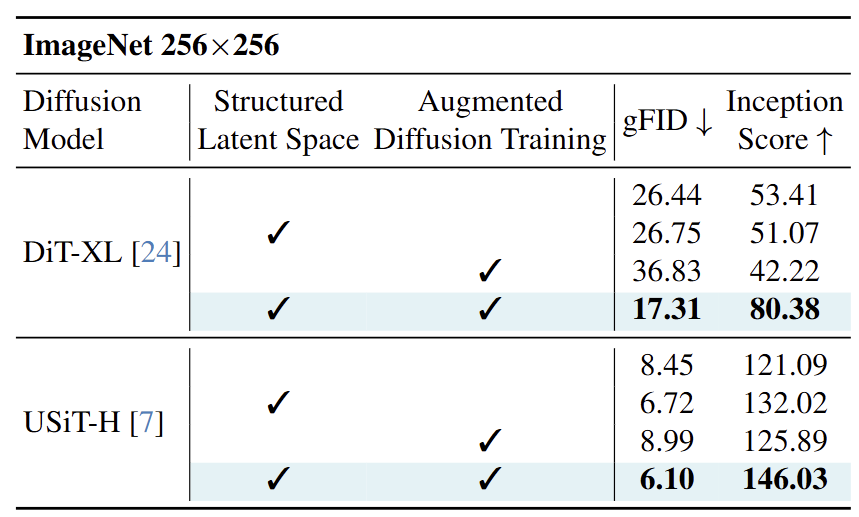
作者进行了 Component-wise 的消融实验,来验证 DC-AE 两个关键设计,即:Structured Latent Space 和增强的扩散训练策略的有效性。
结果如下图 15 所示。可以看到,Structured Latent Space 和增强的扩散训练策略对于提高图像生成质量至关重要。例如,对 DiT-XL,单独添加 Structured Latent Space 或者增强的扩散训练策略甚至会损害结果。相比之下,将他们结合起来会得到明显的改进,将 gFID 从 26.44 降低到 17.31,并将 Inception Score 从 53.41 增加到 80.38。因此,作者建议可以同时使用这两种技术。
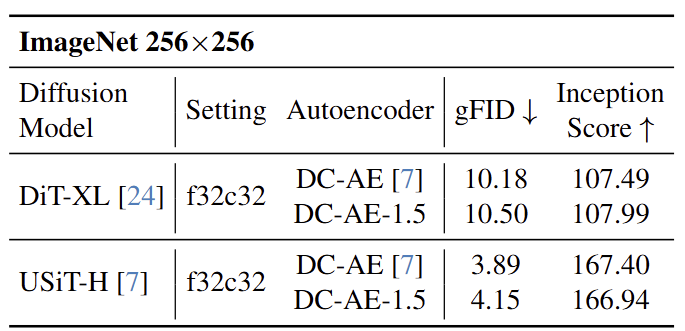
f32c32 设置下与 DC-AE 的比较
虽然 DC-AE 1.5 主要用于 Latent Channel 数较大 (例如 c128) 的 Autoencoder 设置,但仍然可以将其应用于具有 Latent Channel 数较小 (例如 c32) 的设置。下图 16 总结了 f32c32 下 DC-AE 1.5 和 DC-AE 之间的比较。可以发现,DC-AE-f32c32 的性能略好于 DC-AE-1.5-f32c32。作者推测这是因为 f32c32 没有 Latent Space 的稀疏问题。因此,不需要添加 Structured Latent Space 和增强的扩散训练策略。基于这一发现,作者建议在 latent channel 数较大 (例如 c128) 时使用 DC-AE 1.5,而在 latent channel 数较小 (例如 c32) 时使用 DC-AE。

参考
-
High-resolution image synthesis with latent diffusion models -
Scaling rectified flow transformers for high-resolution image synthesis -
Deep compression autoencoder for efficient high-resolution diffusion models -
Scalable diffusion models with transformers -
All are worth words: A vit backbone for diffusion models -
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers -
Deep compression autoencoder for efficient high-resolution diffusion models
(文:极市干货)