


极市导读
地平线联合清华、北大、南大等单位提出了一种新型自动驾驶世界模型——Epona,新的世界模型框架融合了扩散模型与自回归模型的优势,实现了在单一框架下同时支持分钟级长视频生成、轨迹控制生成和实时运动规划。论文已被 ICCV 2025 录用。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
-
⭐ 论文标题:Epona: Autoregressive Diffusion World Model for Autonomous Driving -
📄 论文地址:https://arxiv.org/abs/2506.24113 -
🌐 项目主页:https://kevin-thu.github.io/Epona/ -
💻 GitHub地址:https://github.com/Kevin-thu/Epona/

🚗 世界模型的“架构之争”与现实瓶颈
随着生成模型在视频、图像和控制等领域的突破,世界模型逐渐成为智能体感知和决策的关键工具。在自动驾驶场景中,它的作用尤为重要:通过预测未来环境状态,世界模型有望提升轨迹规划的前瞻性,弱化对昂贵感知与标注系统的依赖,推动端到端自动驾驶向实用迈进。
但目前的世界模型架构仍呈现出“两极分化”:
-
一类以 视频扩散模型(如 GAIA-2、Vista)为代表,生成画面质量高,但只支持固定长度视频,无法灵活推理或控制; -
另一类采用 自回归 Transformer 模型(如 GAIA-1、DrivingWorld),能够逐步预测长序列并支持轨迹控制,但在图像质量与误差积累方面存在明显短板。
这些方案往往只能满足单一侧重点,难以在真实驾驶任务中统一兼顾“画面真实感”、“决策控制性”与“长时序一致性”。Epona 正是针对这一痛点,尝试打破当前世界模型的结构性限制。
🔧 Epona 的核心思想:融合建模,结构解耦
Epona的设计从根本上重新定义了自动驾驶世界模型的构建方式:将生成任务划分为轨迹预测与图像生成两条路径,并在时序与空间维度上进行解耦建模,从而实现灵活性与可控性的统一。
具体来说,Epona输入历史图像序列和轨迹控制,输出包括未来若干步的轨迹,以及下一帧图像画面。为支持这一过程,模型中引入了三个关键设计:
1️⃣ 解耦时空建模,分钟级长视频可扩展生成
通过使用多模态时空 Transformer 编码历史轨迹与图像序列,Epona获得时序潜变量;随后利用基于该潜变量的条件扩散生成模块(DiT),逐帧生成未来图像与轨迹。
该结构摆脱了视频扩散模型的固定长度限制,支持任意长度的长时序视频生成。在 NuPlan 数据集上,Epona可连续生成600帧(2分钟)以上的高分辨率驾驶视频,为同类模型中罕见。
2️⃣ 轨迹与图像生成分离,可控模拟与实时推理兼容
Epona采用两个独立的扩散分支:
-
TrajDiT 用于生成未来轨迹序列; -
VisDiT 根据控制输入生成下一帧图像。
这种结构带来了灵活的使用方式:
-
输入轨迹→输出视频,可用于可控可视化模拟; -
仅启用轨迹预测模块→实现20Hz实时规划能力,无需渲染图像,即可辅助实际控制。
3️⃣ 引入 Chain-of-Forward 训练,缓解自回归误差积累问题
在长序列自回归生成中,误差积累常常导致生成效果退化。为应对这一挑战,Epona提出Chain-of-Forward(CoF)策略:训练过程中周期性使用模型自身预测结果作为下一步输入,从而逼近推理阶段的分布,提升模型稳定性。
该策略与近期 Self Forcing 方法思路不谋而合,但Self Forcing仍基于固定帧数的视频扩散模型调整,Epona基于逐帧自回归重新设计,进一步摆脱了固定视频长度的限制。
📊 实验亮点:统一建模带来多项指标提升
Epona 在 NuPlan 和 nuScenes 两个自动驾驶场景数据集上进行端到端训练,模型参数约 2.5B,图像分辨率为 512×1024。推理阶段支持单卡运行,图像生成速度约为 2s/帧,轨迹预测可实时运行。
✅ 分钟级视频生成能力
在与 Vista 和 NVIDIA Cosmos 等模型的对比中,Epona 展示出更强的视频长度与稳定性能力:
✅ 轨迹可控视频生成
可接受外部轨迹输入并生成视觉模拟结果,支持驾驶控制与偏好定制:
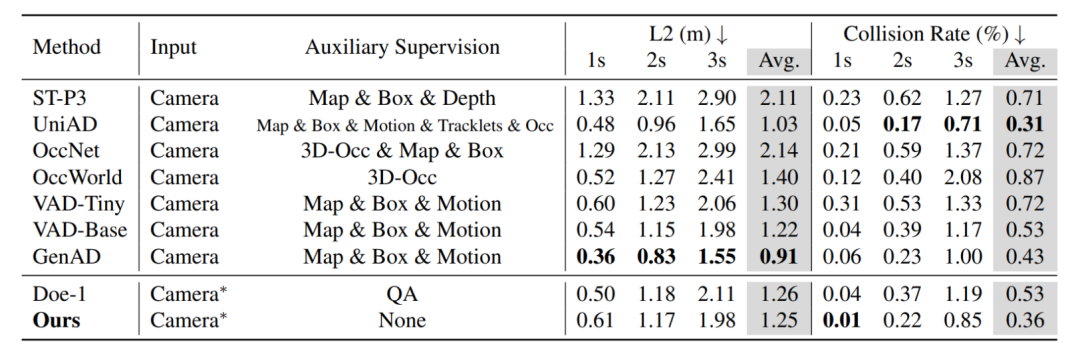
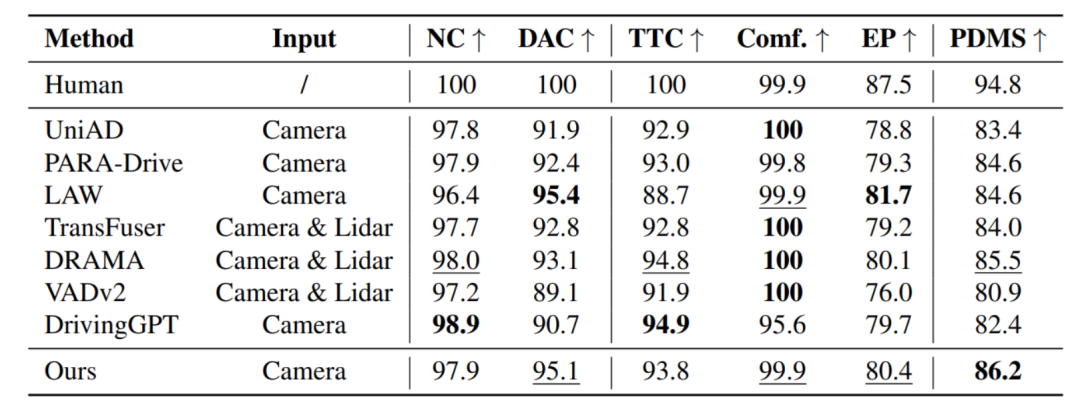
✅ 轨迹预测结果
在 nuScenes 与 NAVSIM 上的端到端轨迹预测任务中,Epona达到了与专门的运动规划网络相当的精度:
🧠 与相关工作的差异与衔接
近年来,“AR+Diffusion” 成为生成模型设计的新趋势。Epona的设计与以下几类方法有所区分:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
🔚 总结
Epona 提供了一种结构上融合自回归推理与扩散生成的新型世界模型方案,支持分钟级可控视频生成、实时轨迹规划与统一多模态建模,为自动驾驶智能体的感知与决策融合提供了可能路径。
尽管当前模型在物理建模、细节一致性方面仍有优化空间,但其框架设计为未来引入三维结构建模、交互建模等机制奠定了良好基础。
参考文献[1] GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
[2] Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
[3] GAIA-1: A Generative World Model for Autonomous Driving
[4] DrivingWorld: Constructing World Model for Autonomous Driving via Video GPT
[5] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
[6] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
[7] NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
[8] nuScenes: A multimodal dataset for autonomous driving
[9] Cosmos World Foundation Model Platform for Physical AI
[10] NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking
[11] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
[12] JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
[13] Emerging Properties in Unified Multimodal Pretraining
[14] Autoregressive Image Generation without Vector Quantization
[15] Autoregressive Video Generation without Vector Quantization
[16] VideoMAR: Autoregressive Video Generatio with Continuous Tokens
[17] From Slow Bidirectional to Fast Autoregressive Video Diffusion Models
[18] Vid2World: Crafting Video Diffusion Models to Interactive World Models
(文:极市干货)