


极市导读
西湖大学 AGI Lab 推出 Detail++,在无需训练的前提下,通过“分层子提示 + 渐进注入 + 注意力共享”策略,显著提升复杂 Prompt 场景下的图文一致性与细节还原,重塑高保真文生图新范式。>>加入极市CV技术交流群,走在计算机视觉的最前沿
复杂Prompt下的生成结果:

引言
文本到图像(T2I)生成技术近年来发展迅猛,凭借 Stable Diffusion、Flux 等模型,用户只需一句自然语言即可生成高质量图像。然而,当遇到多主体、多属性或复杂风格的长 prompt 时,主流模型往往会出现以下困境:
-
语义溢出:不同主体之间属性相互干扰,生成预期以外的结果; -
属性错配:颜色、质地、配饰等细节经常被错误地绑定到非目标对象; -
风格混合:多个风格描述同时作用时,模型难以保持元素及其特征的正确分离。
为解决上述问题,西湖大学 AGI Lab 团队提出了 Detail++:一种无需训练的精细化文生图框架。Detail++ 的核心在于借鉴人类画家“先整体勾勒、再逐步刻画”的创作灵感,首先将复杂的原生 prompt 分层拆解为由粗到细的子 prompt,并在所有生成分支中共享 U‑Net 自注意力图以维持全局布局;随后通过交叉注意力掩码技术,将各层子 prompt 的新增细节精准注入到对应区域。最后,为确保交叉注意力掩码进一步准确,我们在测试阶段引入质心对齐损失,对去噪过程进行优化,从而在无需任何模型重训练的情况下,实现对复杂文本指令的高保真生成。
相较于现有方法,Detail++ 具有以下核心优势:
-
更高的细节一致性:能有效避免属性溢出、错配与风格混合,使生成结果与复杂指令高度贴合; -
更多样的对齐能力:支持多主体、多属性、多风格的复杂场景,通过并行分支协作实现灵活、可控的细节注入; -
更低的资源开销:整个流程无需模型微调,仅依赖测试时的注意力共享与优化,可在单卡环境下高效运行。


-
论文标题:Detail++: Progressive Detail Injection for Training-Free Semantic Binding in Text-to-Image Generation -
论文链接:https://arxiv.org/abs/2507.17853 -
项目地址:https://detail-plus-plus.github.io/ -
Github:https://github.com/clf28/Detail-plus-plus -
Huggingface: https://huggingface.co/spaces/Westlake-AGI-Lab/Detail-plus-plus
研究背景与挑战
在复杂提示驱动的文本到图像生成任务中,多主体、多属性与多风格的精细化绑定一直是核心难题。现有工作大致可分为三种思路,但它们在“精度”“效率”“实用性”三者之间各有局限。
-
基于模型微调的方法 —— 此类方式往往需要耗费大量算力与训练时间,而且一旦基线模型升级,就必须重新微调才能保持性能;
-
基于布局指引的方法 —— 此类方法往往需要借助用户提供或大模型推理得到的布局标注来提高绑定的精准性,增加了推理时的复杂度;
-
基于测试时优化的方法 —— 此类方法完全依赖去噪推理过程中插入迭代优化或注意力正则化步骤,属性绑定具有很大局限性。
Detail++ 正是在此背景下提出,基于分层子提示与自注意力图共享的方式,实现了对复杂提示的高保真、低开销生成。
方法概述
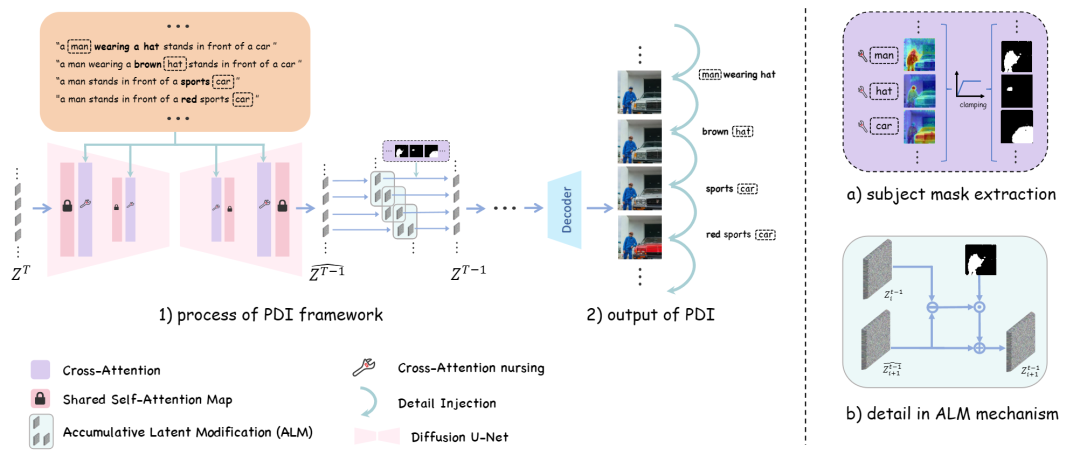
贡献一:渐进式细节注入
Detail++ 借鉴艺术家“先整体勾勒、再逐步刻画”的创作思路,将复杂 prompt 自动分解为一系列由粗到细的子 prompt,并在所有分枝并行的基础上,统一共享 U-Net 的自注意力图以保持全局布局一致;随后,利用交叉注意力掩码在每个分支中逐步、有针对性地注入新增细节,并通过累积潜变量修改策略仅在目标区域应用新属性,避免跨主体干扰。此步骤分为三小步:
-
提示分解
首先,使用语言模型(如 spaCy)将原始复杂提示 分解为从最简到最全的一系列子提示 ,其中 去除所有修饰词,只保留主体与基本行为,后续每个 则相对于 依次添加一个新的细节修饰,并记录其对应的主体为 。这样,PDI 能够以“由粗到细”的方式,逐步构建复杂场景。

-
布局共享
在各分支并行生成过程中,Detail++ 利用 U-Net 中自注意力图所承载的空间布局信息,仅在最初的若干去噪步骤缓存并复用第一分支的自注意力图,以确保所有子提示生成时保持相同的整体构图。这一步既保留了基础场景的一致性,又避免了各分支间的布局冲突。
-
累积潜变量修改
对于每一个子提示分支,Detail++ 从对应的交叉注意力图中提取二值化的主体区域掩码 ,用以区分新增修饰词的目标区域。然后,在每个去噪时刻,只将带有新细节的潜在表示差值按掩码 注入至相应区域,其余位置则保持原始潜变量不变,从而避免跨主体干扰,确保细节精准到位。
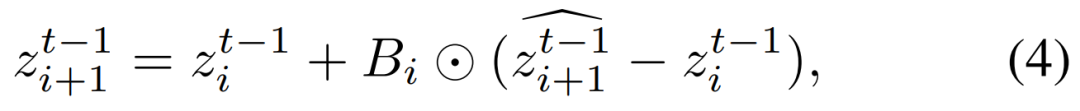
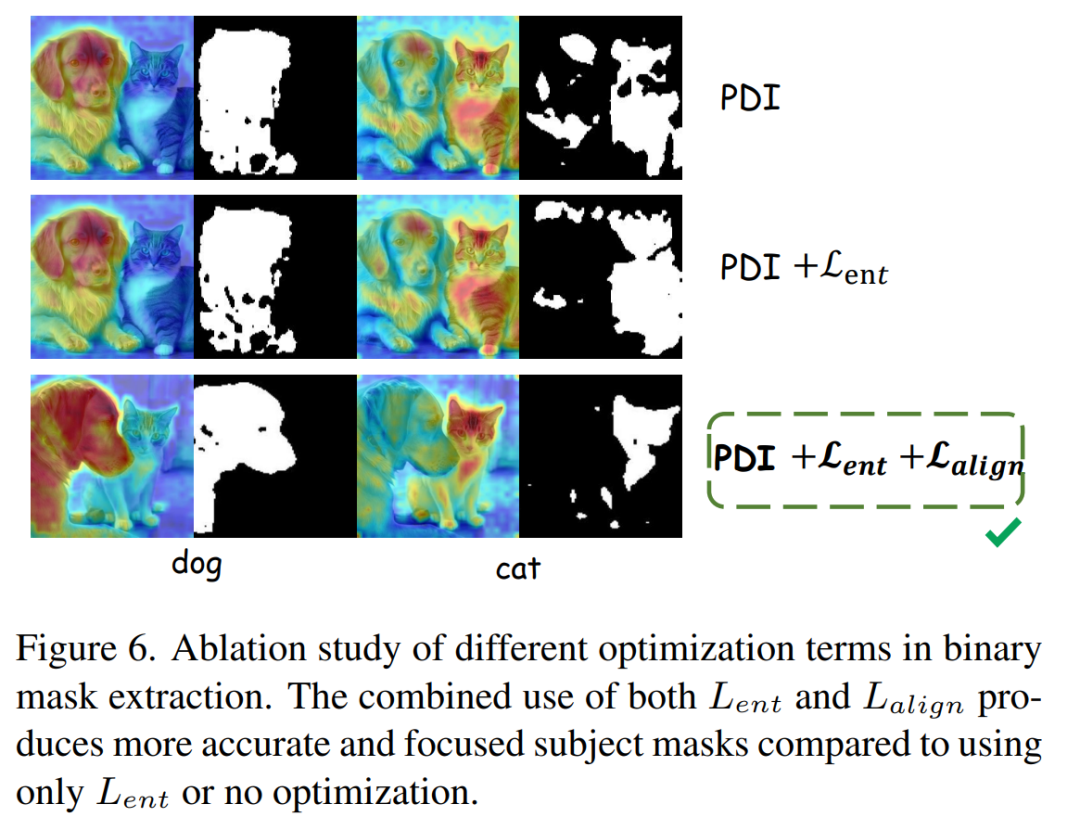
贡献二:质心对齐损失
在测试阶段,我们观察到现有交叉注意力图易产生分散激活,导致属性注入范围越界。为此,Detail++ 引入了一种质心对齐损失,在每个扩散步骤对当前潜变量施加梯度优化,最小化对应主体的交叉注意力图质心与其显著点之间的欧氏距离,从而收敛出更加聚焦的注意力分布,显著提升属性绑定精度,并生成准确的二值掩码,彻底解决属性错配问题。
实验亮点:不仅仅支持颜色的精准匹配,更支持多个物品、材质、甚至风格描述的精确生成。

对比多种类型 SOTA 的精确化文生图方法(如 ToME,Attention Regulation,ELLA 等),Detail++ 在对象形变幅度、视觉细节与图文匹配度方面均表现突出,综合主观与客观评测指标均居领先水平。
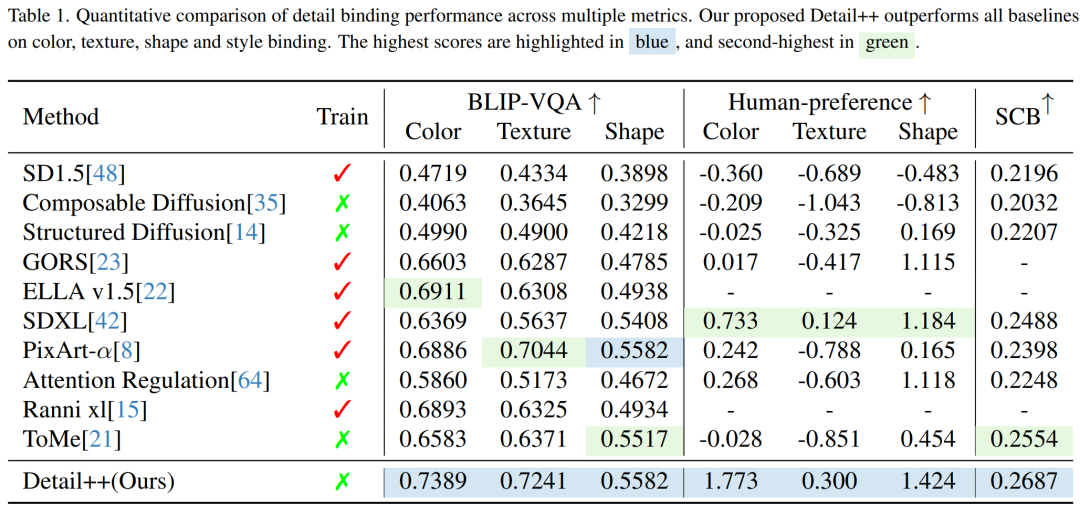
在定量结果中,Detail++在各项指标上均实现了 SOTA 表现,尤其在我们新提出的风格绑定基准测试中最为突出。Detail++不仅超越了现有的精确化文生图方法,也在风格绑定方面填补了空白。
结语
通过 Detail++,我们展示了在无需任何额外训练的前提下,如何高效且精确地应对复杂文本指令下的多主体、多属性与多风格场景。Detail++ 的出现,为未来大规模、实时化的精确化文生图应用开辟了全新路径,让生成模型既能兼具灵活性与可控性,又保持了对计算资源的高效利用,尽力推动 AIGC 领域在创作自由度与用户体验上的进一步突破。
(文:极市干货)