


极市导读
BLIP3‑o 实现了视觉理解与生成两项功能在同一框架内统一支持。它采用了基于 CLIP 特征的 Diffusion Transformer + Flow Matching 的生成模块,并结合 先完成理解任务、再进行图像生成的顺序式训练策略,在视觉理解与生成多个主流基准上均达到了当下最先进水平。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
完全开源的生成理解统一模型:架构,训练,数据集。
本文探索了理解生成统一模型 (Unified Multimodal Models) 的最优模型架构和训练配方。本文研究了几个关键的问题:
图像应该怎么表征?使用 VAE 还是 CLIP-Diffusion 作为 Autoencoder。
训练目标该如何设计?使用 MSE Loss 还是 Flow Matching Loss?
统一模型的顺序预训练策略该怎么做?是联合训练,还是先在图像理解上进行训练,再在图像生成上训练?
本文开发的 BLIP3-o 是一套最先进的统一多模态模型,在图像理解和生成任务的大多数 Benchmark 中都取得了卓越的性能。本文还做了一个高质量的指令微调数据集 BLIP3o-60k。

下面是对本文的详细介绍。
本文目录
1 BLIP3-o:完全开源的生成理解统一模型:架构,训练,数据集
(来自 Salesforce)
1 BLIP3-o 论文解读
1.1 BLIP3-o 简述
1.2 为什么要构建理解生成统一模型
1.3 图像表征路线:VAE Autoencoder 还是 CLIP-Diffusion Autoencoder ?
1.4 图像 Latent 表征建模路线:MSE Loss 还是 Flow Matching?
1.5 训练策略:联合训练还是顺序训练?
1.6 BLIP3-o 模型
1.7 实验结果
1 BLIP3-o:完全开源的生成理解统一模型:架构,训练,数据集
论文名称:BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Dataset
论文地址:
https://www.arxiv.org/pdf/2505.09568
代码链接:
https://github.com/JiuhaiChen/BLIP3o
模型:
https://huggingface.co/BLIP3o/BLIP3o-Model
预训练数据:
https://huggingface.co/datasets/BLIP3o/BLIP3o-Pretrain-Long-Caption
指令微调数据:
https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
1.1 BLIP3-o 简述
理解生成统一模型 (Unified Multimodal Model) 支持使用一个模型完成图像理解和图像生成的任务。图像生成的最佳架构和训练策略仍未得到充分探索。前人的方案主要围绕 2 种方法:
第 1 种方法 (如 Chameleon,Emu3,TokenShuffle) 将连续的视觉特征量化为离散的 token,并将它们建模为分类分布。
第 2 种方法 (如 MetaMorph,MetaQuery) 通过自回归模型生成视觉特征或 latent representation,然后以这些视觉特征的条件,通过 Diffusion Model 生成图像。
最近的 GPT-4o 图像生成被暗示采用具有自回归和扩散模型的混合架构,遵循第 2 种方法。
为此,本文系统研究了 Unified Model 中图像生成的 design choice。
本文研究的 3 个关键问题:
-
图像表征: 将图像编码为 low-level 像素特征 (比如基于 VAE 的编码器) 或 high-level 语义特征 (比如来自 CLIP 图像编码器)。 -
训练目标: MSE 还是 Flow Matching。以及它们对训练效率和生成质量的影响。 -
训练策略: 图像理解和生成的联合多任务训练 (如 Metamorph),还是像 LMFusion 和 MetaQuery 这样的顺序训练,其中模型首先被训练来理解,然后扩展到生成。
结论 (太长不看版):
-
图像表征: CLIP 特征比 VAE 特征提供更紧凑和信息量更大的表征,训练速度更快,图像生成质量更高。 -
训练目标: Flow Matching Loss 比 MSE Loss 更有效,实现更多样化的图像采样,产生更好的图像质量。 -
训练策略: 顺序训练策略,即首先在图像理解任务上训练自回归模型,然后冻结之后做图像生成训练,可以获得最好的整体性能。
基于这些发现,本文提出 BLIP3-o。
BLIP3-o 在 CLIP 特征上使用 DiT,Flow Matching,先在图像理解任务上训练,再在生成任务训练。
BLIP3-o 框架:
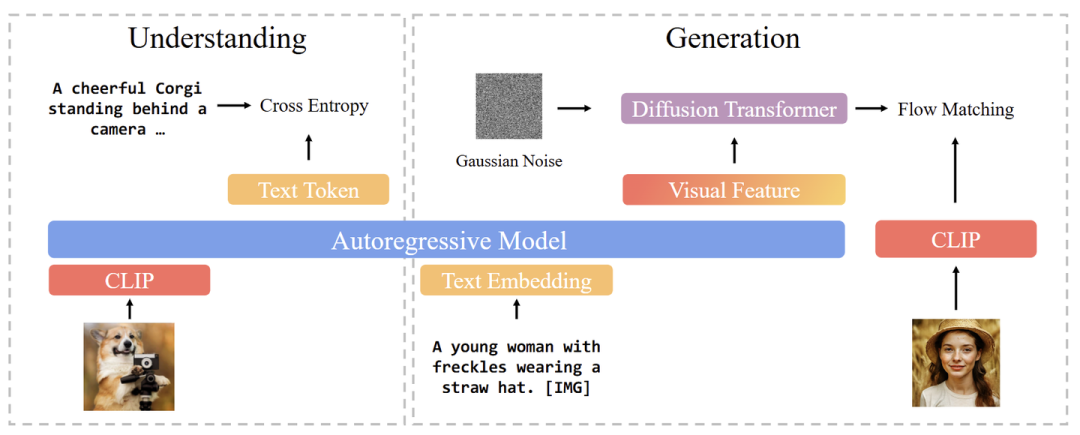
为了进一步提高美学和指令跟随能力,本文通过 prompting GPT-4o,curate 了 60k 高质量指令微调数据集 BLIP3o-60k。BLIP3o-60k 上的有监督指令微调可以显著提升 BLIP3-o 与人类偏好的对齐,以及提升美学质量。
1.2 为什么要构建理解生成统一模型
3 点原因:
-
继承 MLLM 的推理能力: 把图像生成能力集成到 MLLM 等自回归模型的一个重要原因是希望继承 MLLM 的预训练知识,推理能力,以及指令跟随的能力。 -
In-context Learning: 理解生成统一模型自然地支持 In-context Learning 能力。之前生成的多模态输出可以作为后续生成的 context,从而实现迭代图像编辑、视觉对话和逐步视觉推理。这就不需要再做另一个任务的时候去切换模式了。 -
AGI 的需求: 未来的系统需要去感知、解释和生成多模态内容。要实现这一点,就需要从纯文本架构转移到理解生成统一的多模态架构。
1.3 图像表征路线:VAE Autoencoder 还是 CLIP-Diffusion Autoencoder ?
BLIP3-o 采用了自回归+扩散框架。自回归模型产生连续的中间视觉特征,这就带来了两个关键问题。
其一,这个图像特征的 Ground-truth Embedding 是什么?我们应该使用 VAE 还是 CLIP 编码的特征?
其二,自回归模型生成视觉特征之后,我们应该如何有效将其与 GT 真实图像特征对齐?或者更一般地讲,我们如何对这些连续视觉特征的分布进行建模:通过 MSE Loss,还是 diffusion-based 方法?
图像生成通常首先使用 Encoder 将图像编码为连续的 latent embedding,然后使用 Decoder 从该 latent embedding 重建图像。这种 Encoder-Decoder Pipeline 可以有效地降低图像生成中输入空间的维数,促进高效训练。
图像表征相关的路线,有两种比较常见的 Encoder-Decoder 范式:
一类是 VAE Autoencoder 路线。 VAE 是一类生成模型,它学习将图像编码为结构化的连续 latent space。Encoder 估计给定图像的 latent 的后验分布,Decoder 根据从 latent distribution 中得到的采样,来重建原始图像。Latent Diffusion Model 就是建立在该框架的基础上,建模 latent 的分布,而不是原始图像的分布。通过在 VAE latent 空间中操作,可显著降低输出空间的维度,降低了计算成本,实现更高效训练。
一类是 CLIP-Diffusion Autoencoder 路线。 CLIP 模型因为在大规模图像-文本对上进行对比学习,因而具有很强的从图像中提取丰富、高级语义特征的能力。但是因为 CLIP 最初不是为重建任务设计的,所以利用 CLIP 特征进行图像生成仍不容易。
Emu2 的做法是:CLIP-based encoder + diffusion-based decoder。
使用 EVA-CLIP 将图像编码为连续的视觉 embedding,并通过 SDXL-base 初始化的扩散模型重建。在训练期间,diffusion decoder 被微调,将 EVA-CLIP 的视觉 embedding 作为 Condition,从高斯噪声重建原始图像。EVA-CLIP 冻结参数。
这个过程相当于是把 CLIP 和 Diffusion Model 结合为一个 image autoencoder:CLIP Encoder 把图像编码为语义丰富的 latent embedding,Diffusion-based Decoder 从这些 embedding 重建图像。
总结:
VAE Autoencoder,或者 CLIP-Diffusion Autoencoder,都属于是用于获得图像表征 Encoder-Decoder 路线。
VAE 将图像编码为 low-level 像素特征,提供更好的重建质量。且 VAE 可以直接集成到图像生成 training pipeline 中。
CLIP-Diffusion 需要额外的训练来使扩散模型适应各种 CLIP Encoder。但是,CLIP-Diffusion 架构在图像压缩比率方面更有优势。比如在 Emu2 和 BLIP3-o 中,无论分辨率如何都可编码为 64 个连续向量,提供紧凑且语义丰富的 latent embedding。相比之下,基于 VAE 的 Encoder 为更高分辨率的输入生成更长的 latent embedding 序列,增加了训练过程中的计算负担。
1.4 训练目标:MSE Loss 还是 Flow Matching?
在获得连续的 image embedding 后,继续使用自回归架构对它们进行建模。
假设 prompt 是 “A young woman with freckles wearing a straw hat.”。
-
首先使用自回归模型的输入 Embedding 层将其编码为 embedding 向量 。 -
将一组 learnable query 向量 附加到向量 ,得到 。 随机初始化,且在训练期间更新参数。 -
把 输入自回归模型, 学习从向量 中提取语义信息。 -
最后输出的 代表自回归模型输出的中间视觉特征。希望通过训练,使其近似 GT 图像特征 (从 VAE 或 CLIP 得到)。
如何将 与 GT 图像特征 对齐?有 2 种方法:
MSE Loss
给定自回归模型输出的视觉特征 和 GT 图像特征 ,应用一个可学习的线性投影将 的维度与 的维度对齐。然后 MSE Loss 为:
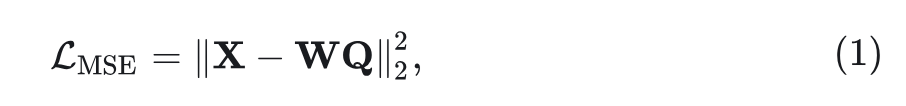
其中, 是可学习的投影矩阵。
Flow Matching
一个扩散框架,可以通过从先验分布(如高斯)迭代传输样本从目标连续分布中采样。给定一个 GT 真实图像特征 和自回归模型编码的 Condition ,在每个训练步骤中,对时间步长 和 noise 进行采样。然后 DiT 学习在以 为条件的时间步 预测速度 ,朝着 的方向。通过在 和 之间进行简单的线性插值来计算 :

的解析解可表示为:
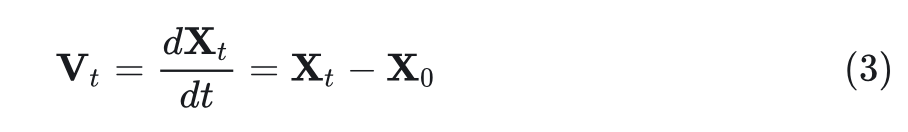
最后的训练目标为:
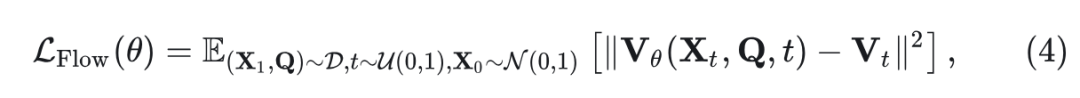
其中, 是 DiT 的参数, 表示基于实例 、时间步长 和噪声 预测的速度。
总结:
离散 token 支持基于采样的策略,可以探索不同的生成路径。连续表征缺少了这个性质。
在基于 MSE 的训练目标下,对于给定的 prompt,预测的视觉特征 Q 几乎是确定的。因此,无论视觉 Decoder 是基于 VAE 的还是 CLIP + Diffusion 的架构,输出图像在多个推理运行中几乎保持不变。这突出了 MSE 目标的一个关键的限制:约束模型为每个 prompt 生成固定的输出,限制了生成的多样性。
相比之下,Flow Matching 使模型能够继承 diffusion 的随机性。允许模型在相同 prompt 时,生成不同图像样本。然而,这种灵活性是以模型复杂性增加为代价的。与 MSE 相比,Flow Matching 引入了额外的可学习参数。本文使用 DiT,并发现缩放模型容量可以提高性能。
三种设计选择
前面列举了 2 种图像表征路线:
-
VAE 作为 Autoencoder -
CLIP-Diffusion (简记为 CLIP) 作为 Autoencoder
也列举了 2 种训练目标 (即 Loss Function):
-
MSE Loss -
Flow Matching
排列组合,得到 4 种图像生成模型的设计方案如下。不同的方案影响生成图像的质量和可控性。
-
CLIP + MSE -
CLIP + Flow Matching -
VAE + Flow Matching -
VAE + MSE
以上 4 种方案,如下图 3 所示,下面一一介绍。
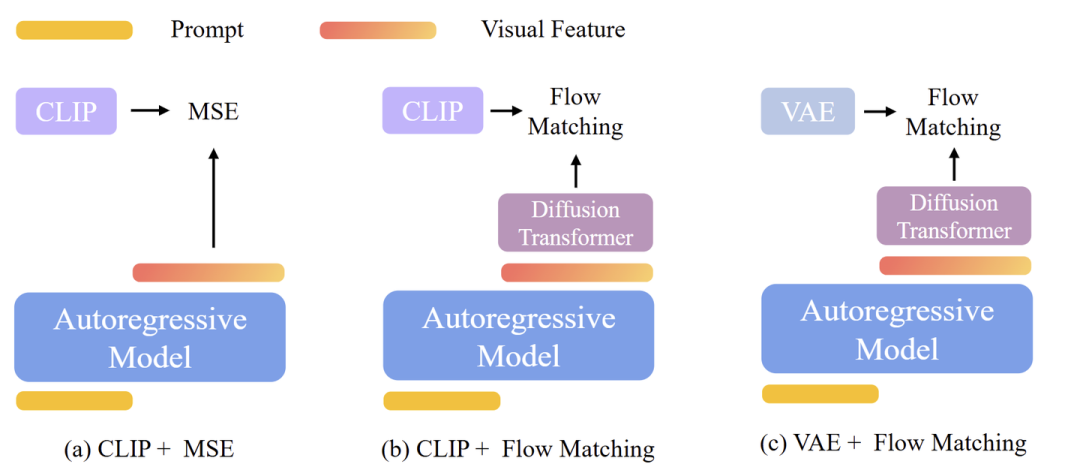
1) CLIP + MSE [代表:Emu2, Seed-X,Metamorph]
如图 3(a)所示,使用 CLIP 将图像编码为 64 个固定长度的语义丰富的视觉 embedding。训练自回归模型以最小化预测的视觉特征 和 GT 的 CLIP embedding 之间的 MSE Loss。在推理过程中,给定一个 prompt ,自回归模型预测 latent 视觉特征 ,然后将其传递给 diffusion-based 的 Decoder 来重建真实图像。
2) CLIP + Flow Matching
如图 3(b)所示,作为 MSE Loss 的替代方案,使用 Flow Matching Loss 来预测 GT CLIP embedding。给定一个 prompt ,自回归模型生成一系列视觉特征 。特征 被用作指导扩散过程的 Condition,产生一个预测的 CLIP embedding 来近似 GT 的 CLIP 特征。
推理过程涉及 2 个 Diffusion Model:
-
第1个使用视觉特征 作为 Condition,把 noise 去噪为 CLIP embedding。 -
第 2 个是 diffusion-based 视觉 Decoder,把 CLIP embedding 转换为真实图像。
3) VAE + Flow Matching [代表:MetaQuery]
如图 3(c) 所示,使用 Flow Matching Loss 来预测 GT 的 VAE 特征。在推理时,给定一个 prompt ,自回归模型产生视觉特征 。然后,以 为条件并在每一步迭代地去除噪声,真实图像由 VAE Decoder 生成。
4) VAE + MSE
由于本文重点是 AR + Diffusion 框架,故排除了 VAE + MSE 方法,因为不包含任何 Diffusion 模块。
自回归模型使用 Llama-3.2-1B-Instruct 。训练数据由 CC12M、SA-1B 和 JourneyDB 组成,总计约 2500 万个样本。对于 CC12M 和 SA-1B,利用 LLaVA 生成的详细字幕,而对于 JourneyDB,使用原始字幕。
下图 4 是这几种方法的结果,包括 FID,DPG-Bench,和 MJHQ-30k 的 FID。图 4 显示 CLIP + Flow Matching 在 GenEval 和 DPG-Bench 上都取得了最好的 prompt alignment 分数,而 VAE + Flow Matching 得到的 FID 最低,表明美学质量最好。
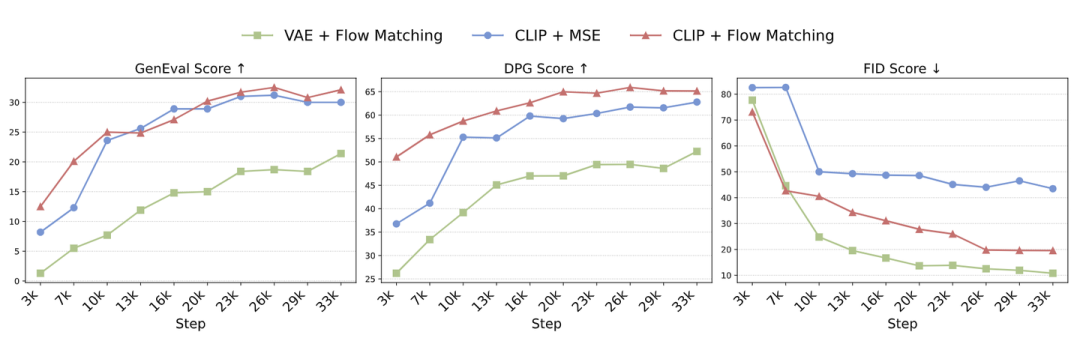
结论 1:把图像生成能力集成到 Unified Model 中时,Autoregressive Model 可以更有效学习语义特征 (CLIP),相比像素级特征 (VAE)。
结论 2:采用 Flow Matching 作为训练目标更好地捕捉底层图像分布,导致样本多样性和视觉质量增强。
1.5 训练策略:联合训练还是顺序训练?
联合训练
联合训练通过混合图像理解和图像生成数据,执行多任务学习,同时更新 Autoregressive Backbone 和生成模块。比如 MetaMorph、Janus-Pro 和 Show-o。
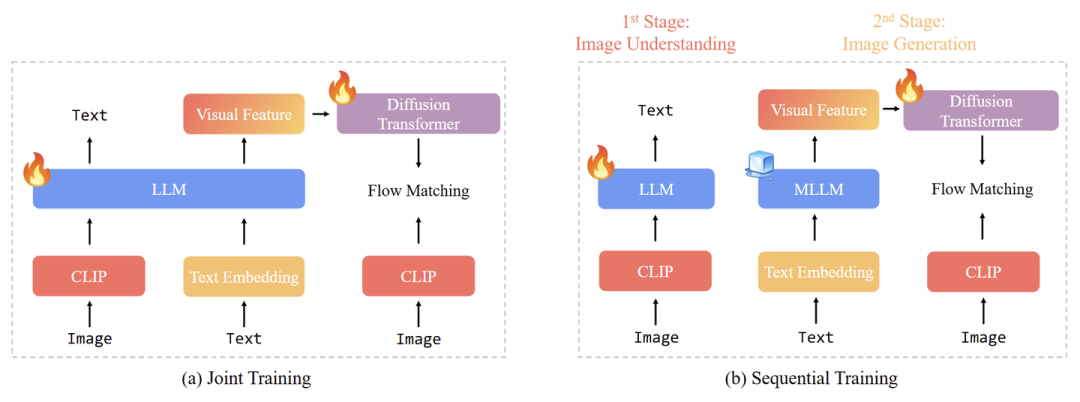
顺序训练
两阶段方法。第1阶段只训练图像理解模块。第2阶段,冻结 MLLM Backbone,只训练图像生成模块,比如 LMFusion 和 MetaQuery 等。
尽管像 Metamorph 所证明的那样,图像理解和生成任务可能相互受益,但有两个关键因素会影响它们的协同效应:1) 总数据量大小;2) 图像理解和生成数据之间的数据比率。相比之下,顺序训练提供了更大的灵活性:允许冻结 Autoregressive Backbone 并保持图像理解能力,可以将所有训练能力集中在图像生成上。
1.6 BLIP3-o 模型
BLIP3-o 基于前文的结论,采用 CLIP + Flow Matching 和顺序训练,是统一的多模态模型。
BLIP3-o 有两种不同的大小模型:在专有数据上训练的 8B 模型和仅使用开源数据的 4B 模型。
跳过图像理解训练阶段并直接在 Qwen 2.5 VL 上构建图像生成模块。
8B 模型冻结了 Qwen2.5-VL-7B-Instruct Backbone 并训练 DiT,共 1.4 B 可训练参数。
4B 模型使用 Qwen2.5-VL-3B-Instruct 作为 Backbone,遵循相同的图像生成架构。
DiT 使用 Lumina-Next。
训练策略
第1阶段:图像生成预训练
8B 模型: 将大约 25M 的开源数据 (CC12M、SA-1B 和 JourneyDB) 与额外的 30M 专有图像相结合。所有图像标题均由 Qwen2.5-VL-7B-Instruct 生成,产生平均长度为 120 token 的长 caption。为了提高对不同提示长度的泛化能力,还包括了约 10% (6M) 短字幕 (长度大约 20 token,来自 CC12M)。每个 image–caption pair 都用 prompt:”Please generate an image based on the following caption: “。
4B 模型: 使用来自 CC12M、SA-1B 和 JourneyDB 的 25M 公开可用的图像,每个图像使用相同的长 caption 配对。还混合了来自 CC12M 的大约 10% (3M) 短字幕。
第2阶段:图像生成指令微调
在图像生成预训练阶段之后,观察到模型的几个弱点:
-
生成复杂的人类手势。 -
生成常见对象,例如各种水果和蔬菜。 -
生成地标,例如 Golden Gate Bridge。 -
生成简单的文本,例如在街道表面编写的单词 “Salesforce”。
尽管这些类别在预训练中间也有涵盖,但预训练语料库的大小有限。因此,又做了专门针对这些领域的指令微调。对于每个类别,prompt GPT-4o 生成大约 10k prompt–image pairs,创建一个目标数据集,以提高模型处理这些情况的能力。为了提高视觉美学质量,还使用从 JourneyDB 和 DALL·E 3 中的 prompt 来扩展我们的数据。这个过程产生了大约 60k 个高质量 prompt–image pairs 的集合。
1.7 实验结果
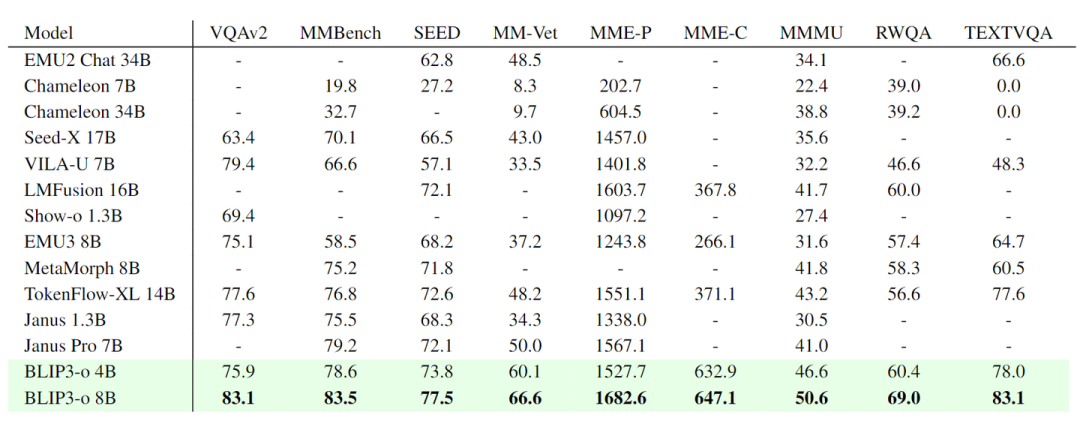
图像理解任务
评估了 VQAv2、MMBench、SeedBench、MM -Vet、MME-Perception、MME-Cognition、MMMU、TextVQA、RealWorldQA 的性能。如图 6 所示,BLIP3-o 8B 在大多数 Benchmark 中实现了最佳性能。
图像生成任务
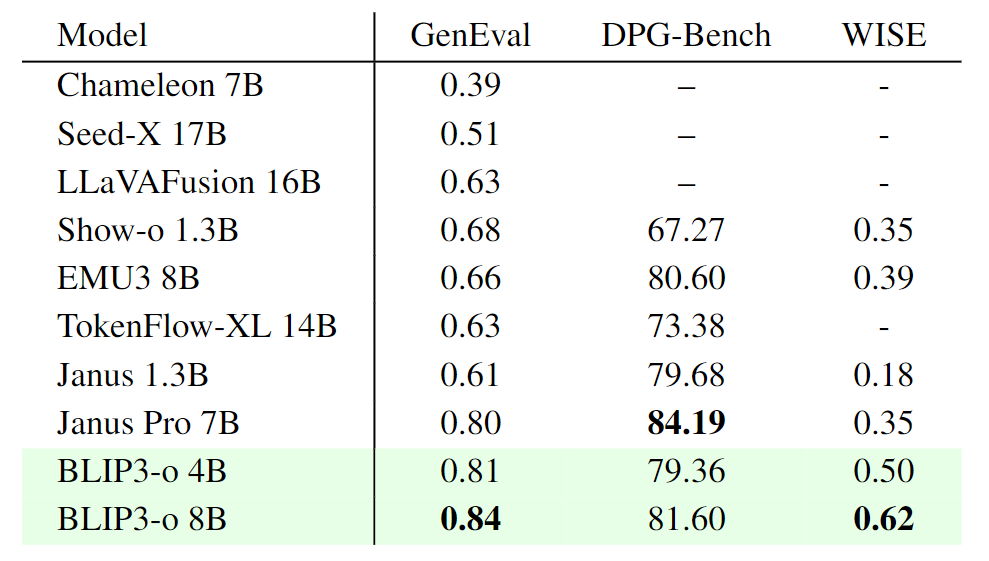
本文报告了 GenEval 和 DPG-Bench 来衡量 prompt alignment,WISE 来评估世界知识推理能力。如图 7 所示,BLIP3-o 8B 的 GenEval 得分为 0.84,WISE 得分为 0.62,但在 DPG-Bench 上得分较低。
为此,作者对所有 DPG-Bench prompt 进行了 human study 来补充这些结果。此外,还发现指令调整数据集 BLIP3o-60k 会产生收益:仅使用 60k 个 prompt–image pair,提示对齐和视觉美学都显著提高,而且许多生成伪影迅速减少。尽管这种指令调整数据集不能完全解决一些困难的情况,例如复杂的人类手势生成,但它仍然显著地提高了整体图像质量。
结论3:该模型可以快速适配 GPT-4o 风格,增强指令对齐和视觉质量。该模型从 AI 生成的图像中学习比真实图像更有效。
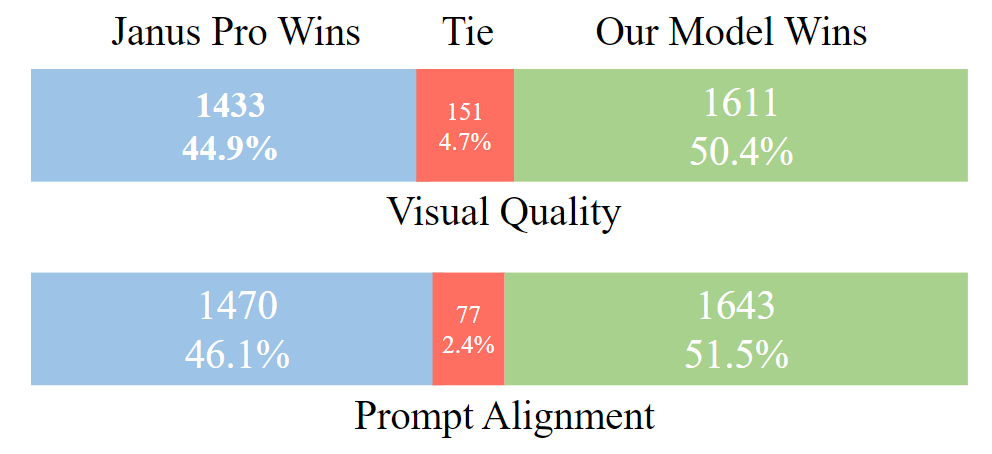
Human Study 结果
作者对从 DPG-Bench 中提取的大约 1,000 个 prompt 的 BLIP3-o 8B 和 Janus Pro 7B 进行了人工评估。对于每个 prompt,注释者在两个指标上比较:
-
视觉质量 (Visual Quality): instruction 是 “All images were generated from the same text input using different methods. Please select the BEST image you prefer based on visual appeal, such as layout, clarity, object shapes, and overall cleanliness.” -
指令对齐 (Prompt Alignment):instruction 是 “All images were generated from the same text input using different methods. Please select the image with the BEST image-text content alignment.”
如图 8 所示,BLIP3-o 在视觉质量和指令对齐方面都优于 Janus Pro。
(文:极市干货)