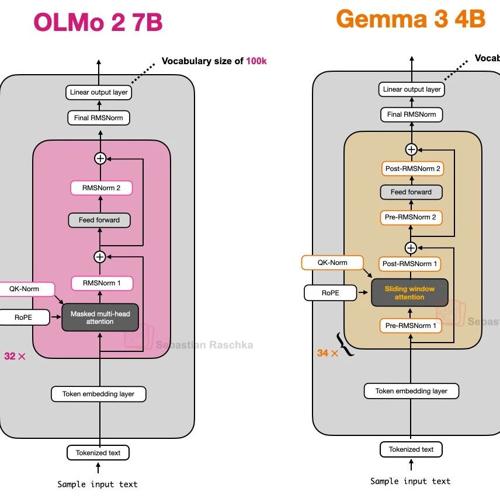
尝试终结Attention Sink起因的讨论
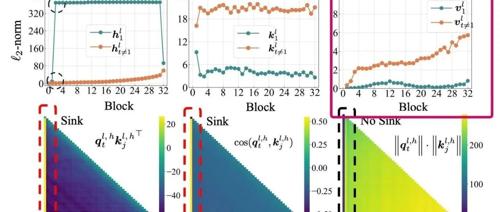
文章提出Transformer中的Attention Sink现象源于模型需要Context Aware的Identity Layer,即注意力块需在某些情况下保持恒等变换。该假设通过首个token的value接近0、深层解码更明显、非归一化注意力和门控机制消除sink等多个实验证据支持,并解释了这一现象的原因。
文章提出Transformer中的Attention Sink现象源于模型需要Context Aware的Identity Layer,即注意力块需在某些情况下保持恒等变换。该假设通过首个token的value接近0、深层解码更明显、非归一化注意力和门控机制消除sink等多个实验证据支持,并解释了这一现象的原因。
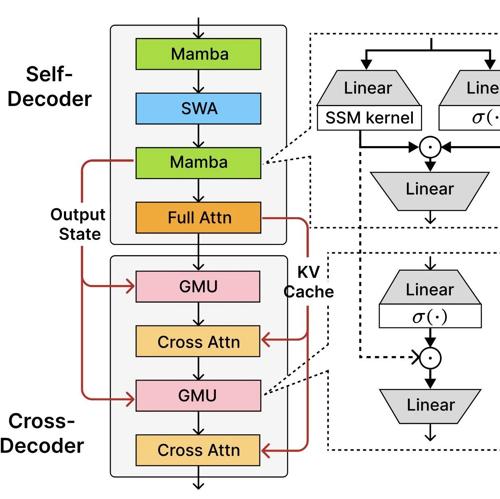
ArchScale是微软推出的一个神经架构预训练工具,支持多种前沿模型及扩展比例定律,提供优化器、高性能训练和全面评估方案等,适合专业研究和实验。

谷歌推出的新架构Mixture-of-Recursions(MoR)在单一框架中实现了参数共享和自适应计算,提高了推理速度并减少了内存需求。它超越了Transformer,在相同的训练预算下提供了更高的性能和效率。

UIUC、斯坦福与哈佛联合提出能量驱动Transformer(EBT),突破传统前馈推理方式,实现更精准和稳健的预测。EBT动态计算资源分配能力使模型能根据问题复杂度调整推理策略,展示类人思考过程。