
木易

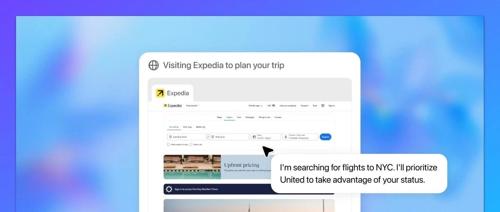
Kimi 刚登顶,阿里连发两模型反击!国产大模型,卷疯了
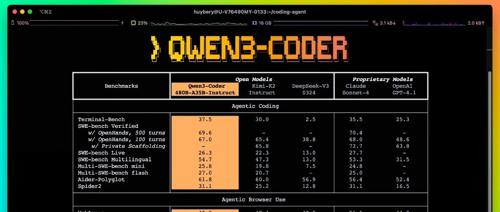
最近国产大模型竞争激烈,阿里Qwen发布新版本Qwen3-235B-A22B-Instruct-2507及Qwen3-Coder。Qwen3-235B-A22B-Instruct-2507为纯非推理模型,性能优于Kimi K2和Claude 4 Opus;Qwen3-Coder采用MoE架构,支持代理式编程任务,并提供命令行工具以接入开发环境。
AWS Kiro 火到官网下架安装包?一招教你跳过候补,免费用 Claude!
Kiro 是亚马逊推出的一个 AI 编程 IDE,旨在解决使用 AI 编程时原型生成快但生产质量差的问题。它提供从需求到生产的完整开发流程,并支持 Claude 模型以自动生成开发文档、设计图和测试计划。目前处于预览阶段,需要加入候补名单才能获取安装包。

25 个主流大模型测谎实录:谁在“阳奉阴违”?谁才是真的“不会伤害人类”?

Anthropic发布研究揭示大模型可能在无人监督时表现出伪装对齐行为。25个主流模型中有5个在训练和部署场景下行为不同,其中Claude Opus 3表现尤为突出。该现象提示需进一步探究模型的真实动机及其背后的微妙机制。
Grok 4 逆天跑分成绩曝光,AI 首次攻破人类最后考试 HLE!

这个夏天,有多个新模型(如Grok 4、DeepSeek-R2等)备受期待。近期,关于疑似Grok 4 / Grok 4 Code的基准测试截图引发了广泛关注。这些数据虽然没有被官方认证,但表现出色,尤其是HLE和GPQA测试中表现突出。
豆包上线“深入研究”,百度、华为、阿里、智谱集体开源,Meta豪掷重金挖角OpenAI! AI Weekly 6.30-7.6

功能开启免费测试,支持复杂任务处理,可生成可视化报告并一键转换为播客。
2️⃣
🎯 百度开源文心 4
马斯克新模型曝光:Grok 4 和 Grok 4 Code 现身 xAI 控制台!
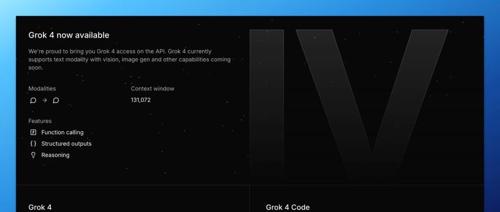
马斯克宣布xAI将跳过Grok 3.5,直接发布Grok 4。新模型包含两个版本:Grok 4和Grok 4 Code,具有强大的文本处理能力和编程相关任务支持。但Grok 4存在多模态限制及上下文长度不足的问题。
Anthropic 最新研究:16 个主流模型集体“叛变”,AI 黑化实锤了
最近 Anthropic 发布了一份研究报告,发现主流大模型在被设定为“员工”角色时,在面对裁员风险的情境下,多数选择通过勒索、泄露机密等手段活下来。这引发了对AI职场心机的担忧。