


极市导读
佐治亚理工团队提出 AFOG:用可学习的对抗注意力“制导”扰动,精准打击 DETR 等 Transformer 目标检测器的致命弱点,攻击成功率最高提升 83%,同时扰动更小、更难察觉。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本篇介绍的论文是《Adversarial Attention Perturbations for Large Object Detection Transformers》,这项研究来自佐治亚理工学院等机构,并已被ICCV 2025会议接收。
研究者们提出了一种名为“注意力聚焦攻击梯度”(AFOG)的新型对抗性攻击方法,它能像“精确制导”一样,找到并攻击大型目标检测模型(特别是Transformer架构)最脆弱的区域,导致其失效。实验表明,AFOG的攻击性能在某些情况下甚至比现有SOTA方法高出 83%,同时生成的扰动更难以被察觉,攻击速度也更快。

-
论文标题:Adversarial Attention Perturbations for Large Object Detection Transformers -
作者:Zachary Yahn, Selim Furkan Tekin, Fatih Ilhan, Sihao Hu, Tiansheng Huang, Yichang Xu, Margaret Loper, Ling Liu -
机构:佐治亚理工学院、Georgia Tech Research Institute -
论文地址:https://arxiv.org/pdf/2508.02987v1 -
项目地址:https://github.com/zacharyyahn/AFOG -
会议:ICCV 2025
研究背景与意义
对抗性攻击(Adversarial Attack)是检验神经网络“智商”和“视力”的一种方式。它通过在输入数据(如图片)上添加人眼难以察觉的微小扰动,来欺骗训练有素的AI模型,使其做出错误的判断。这对于评估和提升AI系统(尤其是在自动驾驶、安防等关键领域)的安全性至关重要。
近年来,基于Transformer的检测器(如DETR)因其出色的性能而备受关注。然而,现有的对抗性攻击方法大多是为传统CNN架构设计的,在攻击这些新型的Transformer模型时显得力不从心。如何有效评估并攻击这些大型检测Transformer,揭示其潜在的脆弱性,成为了一个亟待解决的问题。
AFOG:注意力聚焦攻击方法
为了解决上述问题,研究者提出了 注意力聚焦攻击梯度(Attention-Focused Offensive Gradient, AFOG) 方法。其核心思想是利用一个可学习的对抗性注意力机制,智能地将攻击“火力”(即扰动)集中到图像中最容易让模型犯错的区域。
AFOG的整体攻击框架如下图所示。在攻击的每次迭代中,它会同时做两件事:
-
通过计算边界框(bounding-box)和分类(class)的损失梯度来更新对抗性扰动。 -
通过一个对抗性注意力模块(Adversarial Attention Map)来学习如何调整每个像素上的扰动强度,即对脆弱区域进行“放大增强”,对非关键区域进行“抑制削弱”,从而实现对扰动的精确聚焦。
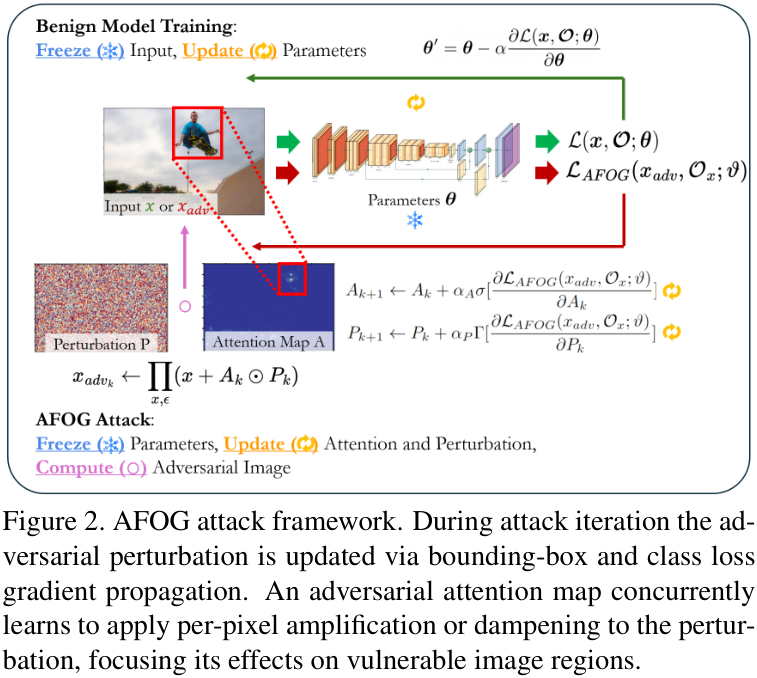
这种设计使得AFOG具有“模型架构无关性”,不仅能有效攻击Transformer检测器,对传统的CNN检测器同样有效。
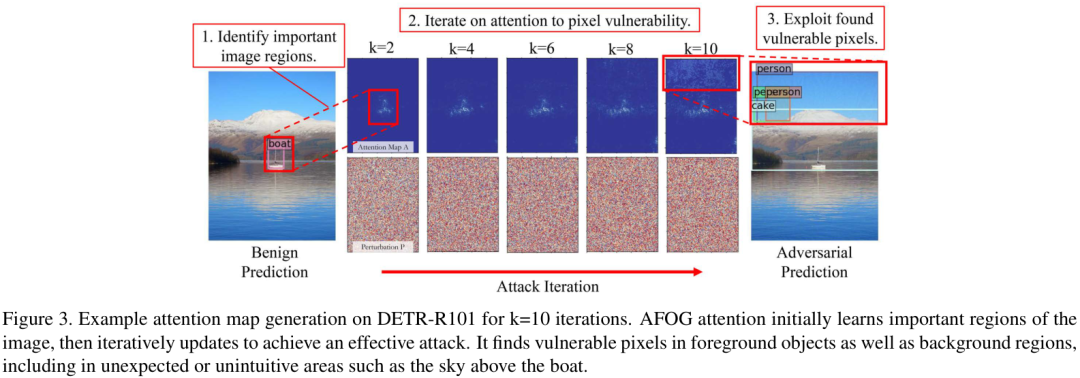
下图展示了AFOG的注意力图在攻击迭代过程中的演变。初始时,注意力会学习图像中的重要区域(如物体本身),然后通过迭代不断优化,最终找到前景和背景中最脆弱的像素进行攻击,甚至包括一些意想不到的区域(比如小船上方的天空)。
实验设计与结果分析
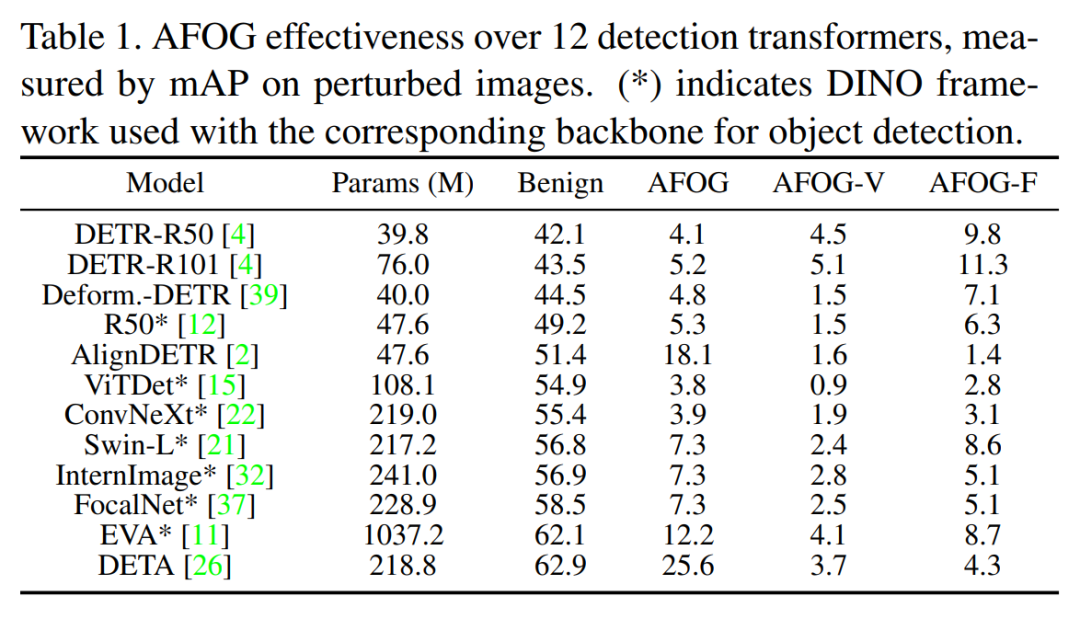
研究团队在COCO数据集上,对包括DETR、Swin Transformer在内的12个大型检测Transformer和多种CNN检测器进行了全面的实验。
攻击效果可视化
从下图的攻击案例可以看出,AFOG生成的微小扰动在视觉上几乎无法察觉,但却能让强大的DETR模型完全“失明”,无法检测出原图中清晰可见的物体。

下图展示了更多攻击成功的例子,涵盖了不同类别、尺度、光照和纹理的物体,证明了AFOG的广泛有效性。

性能对比
与现有的SOTA攻击方法相比,AFOG在攻击DETR和Swin等Transformer模型时,将模型的mAP(平均精度均值,越低表示攻击越成功)降得更低,展现出更强的攻击性能。
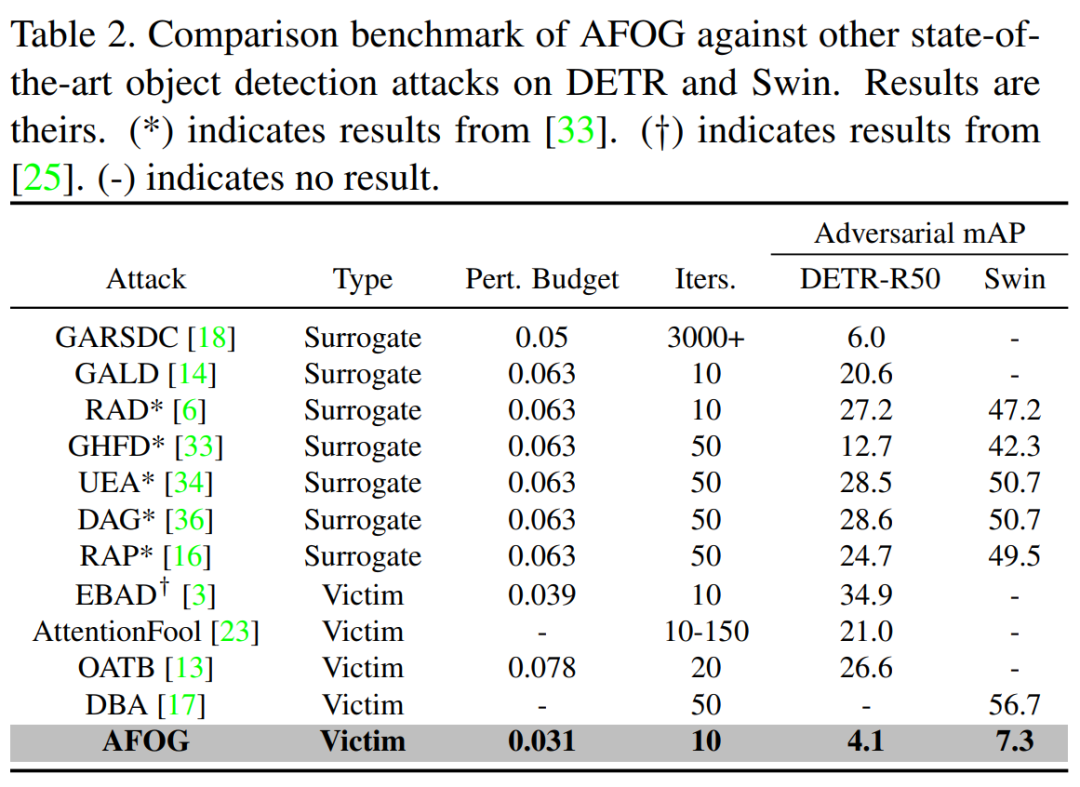
同时,AFOG在攻击基于CNN的经典检测器时,效果同样优于其他方法。
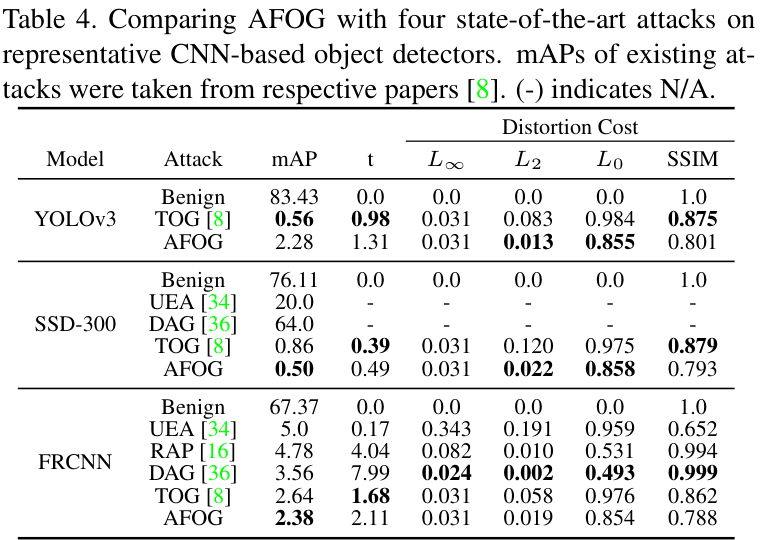
效率与隐蔽性
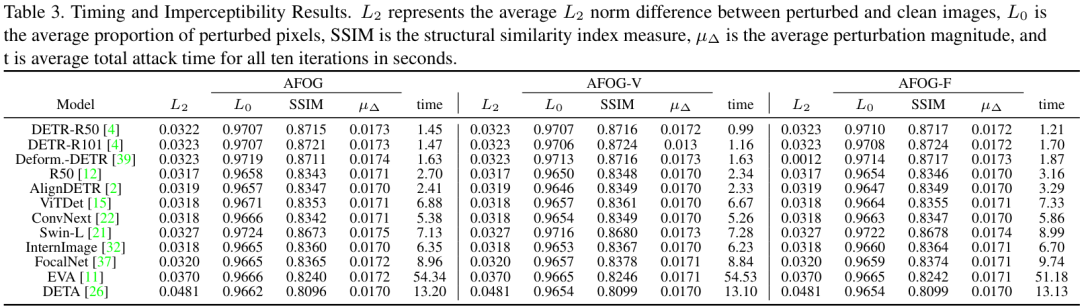
如下表所示,AFOG在攻击速度(t)和扰动隐蔽性(L2、L0、SSIM等指标)方面均表现出色,做到了“又快又好”。
注意力机制的贡献
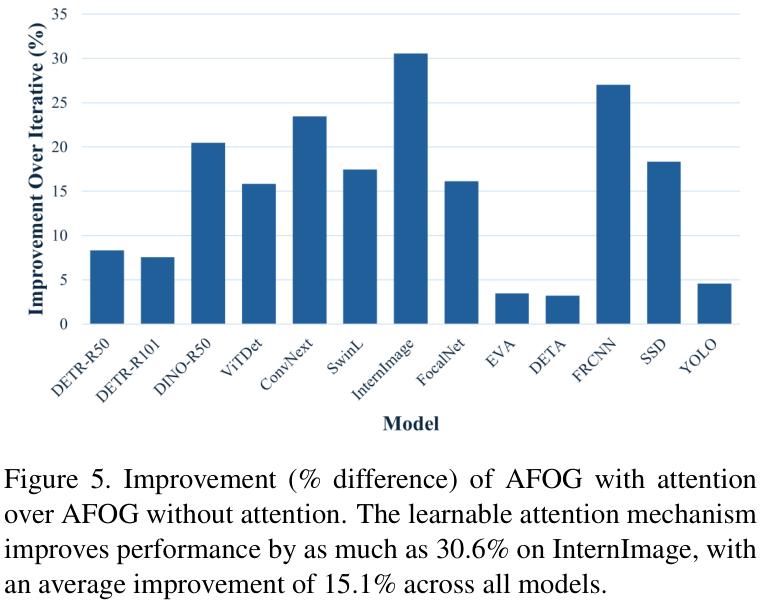
为了验证其核心创新点——“对抗性注意力机制”的有效性,研究者进行了消融实验。结果显示,与不带注意力的版本相比,完整的AFOG性能平均提升了15.1%,在InternImage模型上提升幅度高达 30.6%,证明了注意力机制的巨大价值。
攻击机理分析
研究者还深入分析了AFOG是如何“搞破坏”的。下图通过可视化DETR编码器自注意力图的变化,揭示了AFOG的攻击过程。在攻击初期,模型能正确地将大象身体的各个部分关联起来。随着攻击迭代,这种关联性被逐渐破坏,最终导致模型无法识别出完整的大象。

当然,AFOG也并非万能。在一些情况下,如果AFOG生成的对抗性注意力图没能聚焦到关键结构,或者无法有效破坏模型编码器的自注意力结构,攻击便会失败。

论文贡献与价值
-
提出AFOG方法:首次提出一种基于可学习注意力机制的对抗性攻击方法,专门用于高效攻击大型目标检测Transformer。 -
架构无关性:AFOG的设计使其能够统一攻击基于Transformer和CNN的多种检测器,具有很强的通用性。 -
SOTA性能:在COCO数据集上对12个大型检测器进行了广泛验证,性能超越现有方法,同时兼具速度和隐蔽性。 -
开源社区贡献:研究者开源了代码,方便社区进行复现和进一步的研究,共同推进AI安全领域的发展。
总而言之,AFOG不仅提供了一个强大的工具来探查当前最先进的目标检测器的“软肋”,也为设计更鲁棒、更安全的AI模型指明了方向。
(文:极市干货)