
尝试终结Attention Sink起因的讨论
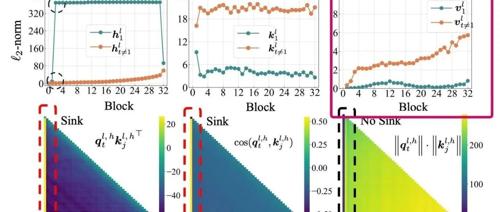
文章提出Transformer中的Attention Sink现象源于模型需要Context Aware的Identity Layer,即注意力块需在某些情况下保持恒等变换。该假设通过首个token的value接近0、深层解码更明显、非归一化注意力和门控机制消除sink等多个实验证据支持,并解释了这一现象的原因。
文章提出Transformer中的Attention Sink现象源于模型需要Context Aware的Identity Layer,即注意力块需在某些情况下保持恒等变换。该假设通过首个token的value接近0、深层解码更明显、非归一化注意力和门控机制消除sink等多个实验证据支持,并解释了这一现象的原因。

版本以及跨本体大小脑协同框架
RoboOS 2.0 单机版
。
RoboBrain 2.0,作为集感

eng
(OpenAI前AI安全与机器人技术应用研究副总裁,现Thinking Machines L
MLNLP社区致力于促进自然语言处理领域的学术与产业交流合作。通过PromptCoT等方法生成高质量数据集,提高模型性能。近期实验表明基于PromptCoT合成的数据可用于零样本强化学习训练,提升效果接近官方预训练模型。





