

今天是2025年9月1日,星期一,北京,晴
来看文档多模态RAG进展,关于这块,我们在多模态RAG专题中已经介绍了许多工作,包括visrag、MDocAgent等框架,以及一些embedding嵌入、竞赛等。
但是,还可以进一步的看看,这些方案中,如果抽离出来组件,那么从性能角度上看,会有什么结论,当我们搭建多模态RAG时,会选用哪些embedding?会使用什么模型?有哪些可用的框架,表现如何?又有哪些可用的数据集?这些都可以作为指导。从一个工作出发,进行解答。
另外,关于文档解析方面进展,涉及到古籍方面,来看一个数据合成工具,包括古籍中的印章以及竖排文字。
多总结,多归纳,多从底层实现分析,会有收获。
一、多模态文档RAG选型组合的一些评估经验
顺着文首,我们来看多模态文档检索的一个评估数据集Double-Bench,《ARE WE ON THE RIGHT WAY FOR ASSESSING DOCUMENT RETRIEVAL-AUGMENTED GENERATION?》 https://arxiv.org/pdf/2508.03644,https://double-bench.github.io,https://github.com/Episoode/Double-Bench,https://huggingface.co/datasets/Episoode/Double-Bench,其给出了一些可以借鉴的点,分点来看。
1、数据集方面
数据集包含3276份文档(共72880页)、5168个单跳与多跳查询,覆盖6种语言(阿拉伯语、中文、英语等)和4类文档(PDF【DocVQA、MMLongBench-Doc】、扫描文档【DocVQA、MMLongBench-Doc、CommonCrawl】、幻灯片【SlideVQA、Commoncrawl】、HTML页面【Wikipedia】)。
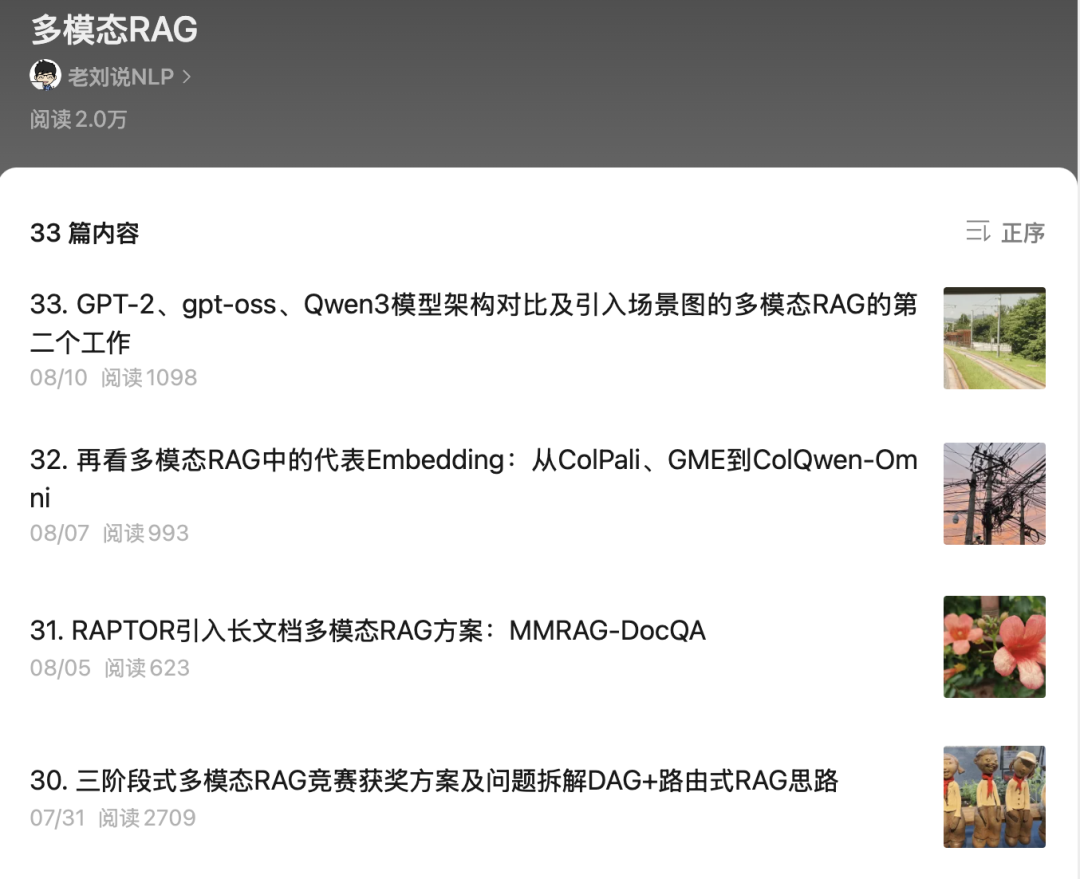
这里的亮点是数据集的构建过程:原始文档经过粗粒过滤(10-50页,使用GPT-4o进行语言验证),然后使用Docling和MinerU等工具进行模态分解,将每页拆分为构成文本、表格和图形组件,然后生成单跳查询,同时额外构建知识图谱,以辅助多跳查询的生成。
这个点值得借鉴,做多跳数据生成,还是使用知识图谱来做中间辅助。
2、嵌入模型选型
9个嵌入模型,包括:
4种文本Embedding模型(Qwen3-Embedding-4B、NV-Embed-v2、gte-Qwen2-7B-instruct、bge-m3),这些都是主流模型选型。
5种多模态embedding模型(colqwen2.5-3b-multilingual、vdr-2b-multi、jina-embeddings-v4、gme-Qwen2-VL-7B-Instruct、colpali-v1.3),这些也是大家在实际落地中喜欢用的模型列表。
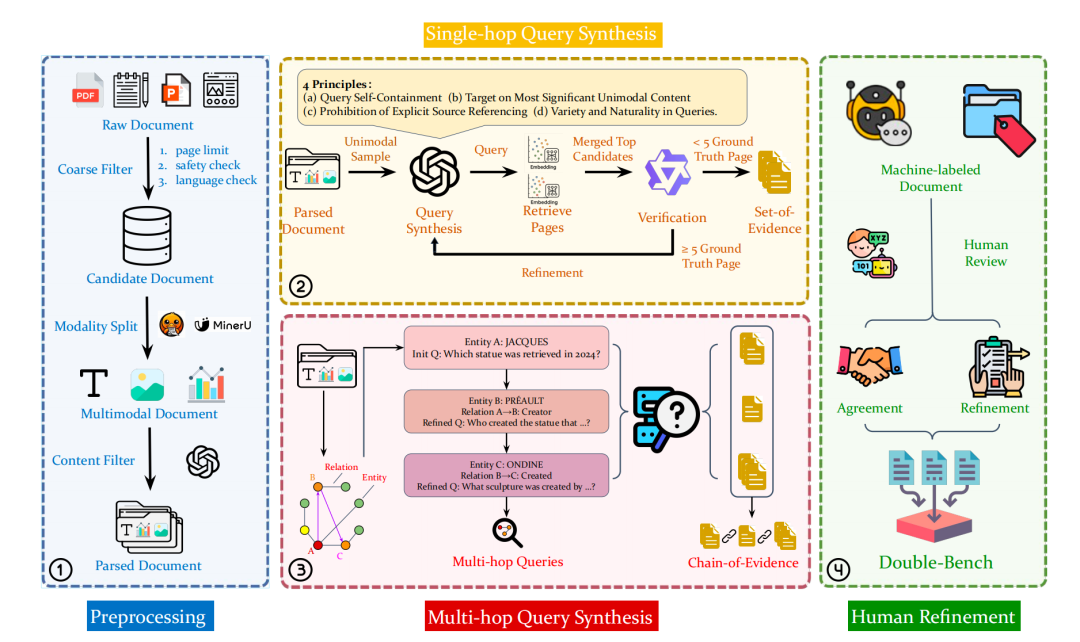
结论方面,文本嵌入模型与视觉/多模态模型的检索差距持续缩小,Qwen3-Embedding-4B(文本)在阿拉伯语、日语等语言的hit@5接近甚至超过jina-embeddings-v4(多模态);
3、MLLM模型选型
4个MLLM模型,包括Qwen3-32B、Qwen2.5-VL-7B/32B、GPT-4o、Llama4Maverick。
结论方面,多模态模型,即便提供真实的页面,MLLM在多跳查询的正确率仍不高,且未按“步骤推理”,而是提取各跳的“标志性信息”直接筛选答案(如多跳问题中跳过“定位实体”步骤,直接匹配结果),这个比较有意思
4、文档多模态RAG框架
文档多模态RAG框架,包括四个。分别是:
1)MDocAgent(多模态多智能体协同,分模块处理检索与生成,MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding,https://github.com/aiming-lab/MDocAgent/blob/main/README.md,https://arxiv.org/abs/2503.13964)
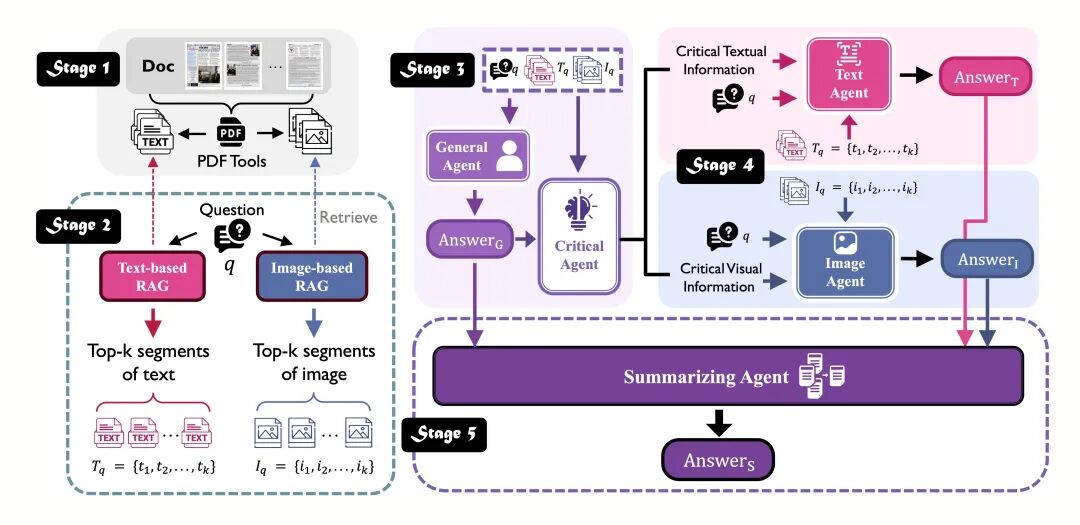
2)ViDoRAG(动态迭代推理,可重复调用组件优化结果,ViDoRAG: Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents,https://arxiv.org/abs/2502.18017,https://arxiv.org/abs/2502.18017)
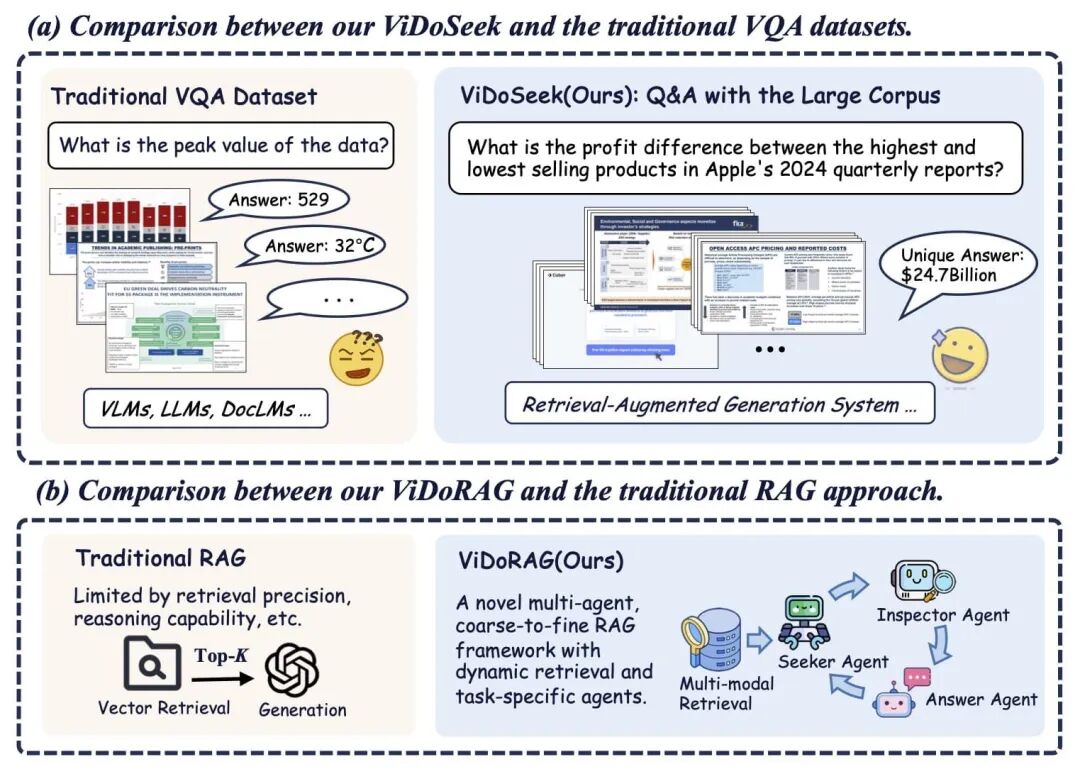
3)M3DOCRAG(多页多文档理解,M3DOCRAG: Multi-modal Multi-page Document RAG System,https://github.com/Omaralsaabi/M3DOCRAG,https://arxiv.org/pdf/2411.04952)
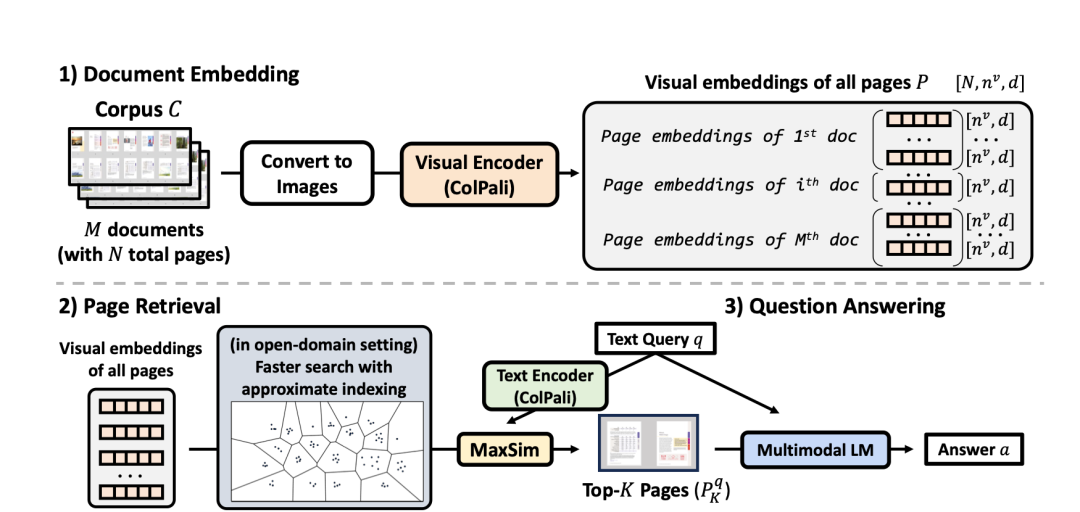
4)Colqwen-gen(简单组合:colqwen2.5-3b检索+GPT-4o生成)。
最终,来看下结论方面:
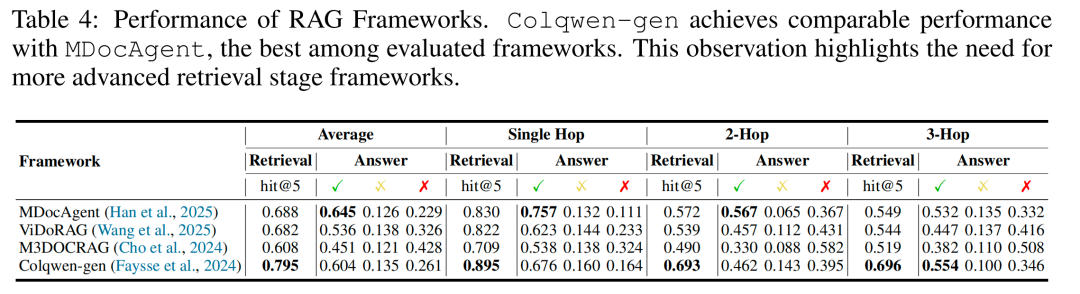
首先,框架的回答准确性与检索准确性高度相关,Colqwen-gen(强检索+简单生成)的多跳回答正确率接近复杂框架MDocAgent,证明“优化检索阶段”比“设计复杂生成流程”更关键;
其次,主流框架(如MDocAgent、ViDoRAG)倾向“有问必答”,即便未检索到证据,仍生成推测性内容,过度自信。复杂框架(MDocAgent、ViDoRAG)因多智能体串行协调,推理时间是Colqwen-gen的4倍左右。
另外,看不同文档类型上,不同框架的表现:
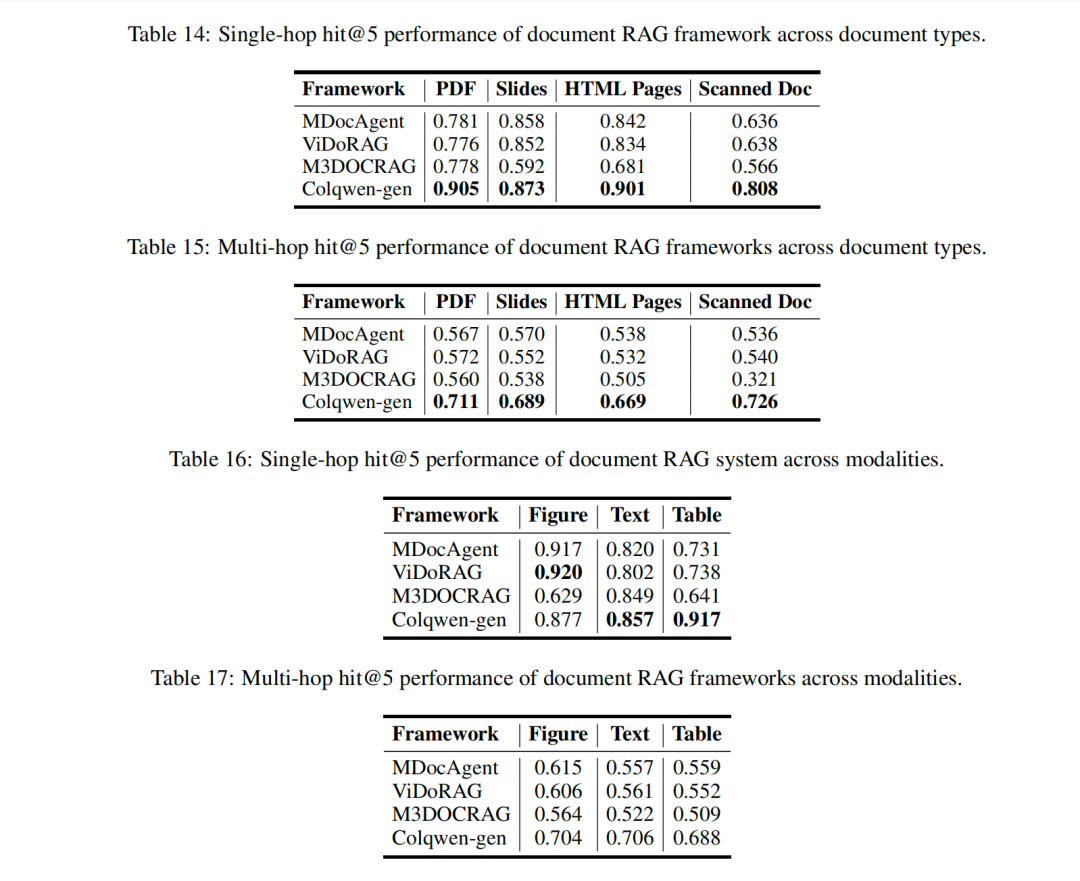
这其实都说明一个点,检索做好了,其实后面效果就会好,搞agent,搞的很复杂,效果并不一定最好。
古籍文档数据集的数据合成工具
另外,还是再做个记录,关于古籍文档数据集,细分来看,古籍文档包括两类特征,一种是电子印章、一个是竖直排版。
顺着这两个特征,来看两个工具。
1、中文古籍设计的电子印章制作工具-vYinn基于Perl语言开发,支持阴文阳文切换、圆形方形椭圆等多种印框,模拟做残、油墨、扩散等传统印章效果。

地址:https://github.com/shanleiguang/vYinn
2、vRain-中文古籍刻本风格直排电子书制作的开源工具
复刻传统雕版刻本工艺,先生成书叶背景图,再逐字按自右向左、自上而下的排版规则精准排布文本。
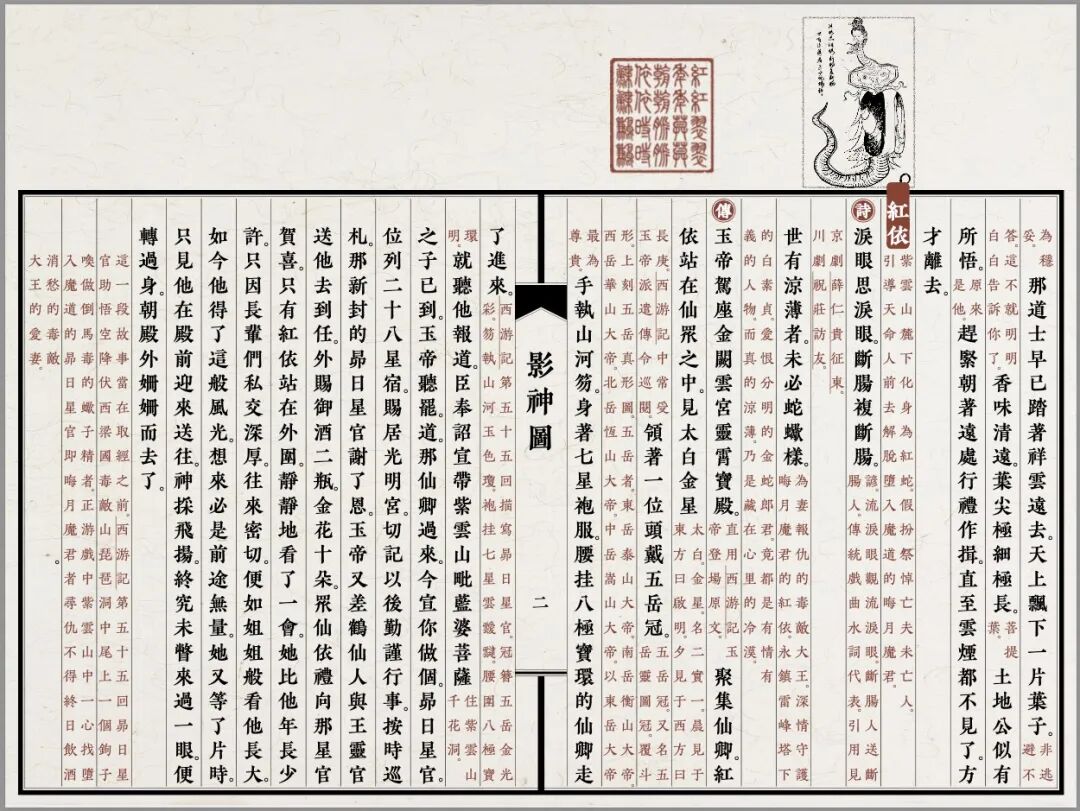
从功能侧看,支持多种古籍背景样式:宣纸做旧、竹简风格,书房名、尺寸、列数、框线粗细及颜色均可自定义;
细节调控:正文与批注文字字体、大小、颜色、位置可调,标点符号可归一化、替换、微调,支持书名号和引号直排旋转。
使用手册在:https://github.com/shanleiguang/vRain/wiki
地址在:https://github.com/shanleiguang/vRain
参考文献
1、https://arxiv.org/pdf/2508.03644
2、https://github.com/shanleiguang/vYinn
3、https://github.com/shanleiguang/vRain
(文:老刘说NLP)