
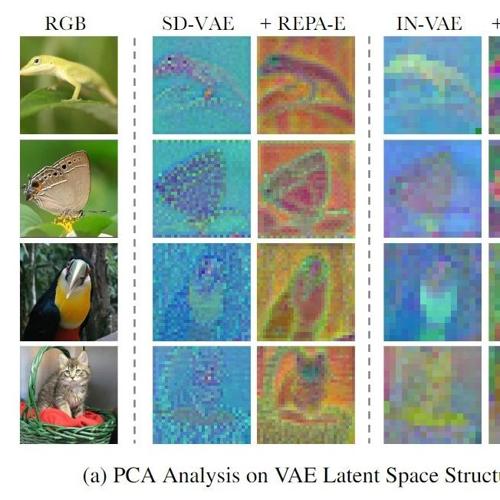
视觉编码器

NeurIPS 2024 TextHarmony:和谐统一的多模态文字理解与生成大模型

TextHarmony是首个在单一模型中实现视觉文本感知、理解与生成任务的OCR研究,通过ViT+MLLM+Diffusion架构及Slide-LoRA缓解模态不一致问题,显著提高OCR相关任务性能。
字节跳动Seed1.5-VL复杂图表精准抽取,Deep Think是多模态未来的主流

Seed1.5-VL 是一个由 ByteDance 开发的多模态语言模型,在处理复杂表格、模糊图片和几何题目等方面表现出色。其架构包含视觉编码器和MoE LLM。预训练数据包括3万亿高质量token,遵循幂律和对数线性关系。Seed1.5-VL 在Hugging Face上可用体验,并通过强化学习后处理提升性能。
看图猜位置不输o3!字节发布Seed1.5-VL多模态推理模型,在60个主流基准测试中拿下38项第一

字节发布轻量级多模态推理模型Seed1.5-VL,在60个主流基准测试中拿下38项第一,仅用532M视觉编码器+200亿活跃参数即能与大型顶尖模型抗衡。该模型通过多层次架构和训练细节实现了高效处理多种多模态数据的能力。
RoboMamba:推理速度提升7倍,北大如何打造高效机器人多模态大模型?

北京大学团队推出RoboMamba,一款高效多模态机器人模型,旨在提升复杂任务的推理与决策能力。其核心目标是增强视觉和语言集成能力、优化微调策略,并降低训练成本。
4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理

伯克利联合英伟达提出PS3视觉编码器,首次在4K超高分辨率下高效预训练,并引入高分辨率基准测试集4KPro。该方法显著提升了高清场景下的表现和效率。
斯坦福团队开源!OpenVLA:小白也能搞机器人,100条数据就能微调!

近期开源的OpenVLA模型通过高效的参数利用和卓越性能推动了机器人技术的发展。基于Llama 2语言模型和融合视觉编码器,它能够将自然语言指令转化为精确的机器人动作。支持在消费级GPU上进行微调,并实现高效服务。应用场景包括家庭服务机器人、工业机器人及教育研究等领域。

2025首篇关于多模态大模型在富文本图像理解上的全面研究综述
文本丰富的图像理解(TIU)涉及感知和理解两个核心能力。MLLMs通过模态对齐、指令对齐和偏好对齐等方法进行训练,并使用多样化的数据集和基准测试评估性能。