字节开源视觉-语言多模态大模型,AI理解现实世界的能力越来越强了。

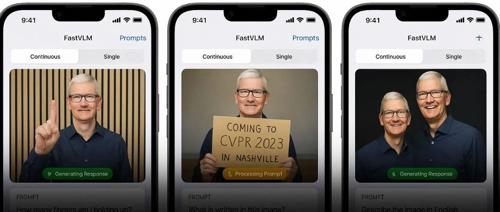
字节开源的Seed1.5-VL是视觉-语言多模态大模型,支持多种复杂任务如盲人判断红绿灯和智能导盲。其包含5.32亿参数视觉编码器和200亿激活参数混合专家大语言模型,已在多个公开基准中表现出色。
字节开源的Seed1.5-VL是视觉-语言多模态大模型,支持多种复杂任务如盲人判断红绿灯和智能导盲。其包含5.32亿参数视觉编码器和200亿激活参数混合专家大语言模型,已在多个公开基准中表现出色。

Seed1.5-VL 是一个由 ByteDance 开发的多模态语言模型,在处理复杂表格、模糊图片和几何题目等方面表现出色。其架构包含视觉编码器和MoE LLM。预训练数据包括3万亿高质量token,遵循幂律和对数线性关系。Seed1.5-VL 在Hugging Face上可用体验,并通过强化学习后处理提升性能。

字节推出视觉-语言多模态大模型Seed1.5-VL,具备更强的通用多模态理解和推理能力,在视频理解、视觉推理等方面表现突出。

字节发布轻量级多模态推理模型Seed1.5-VL,在60个主流基准测试中拿下38项第一,仅用532M视觉编码器+200亿活跃参数即能与大型顶尖模型抗衡。该模型通过多层次架构和训练细节实现了高效处理多种多模态数据的能力。
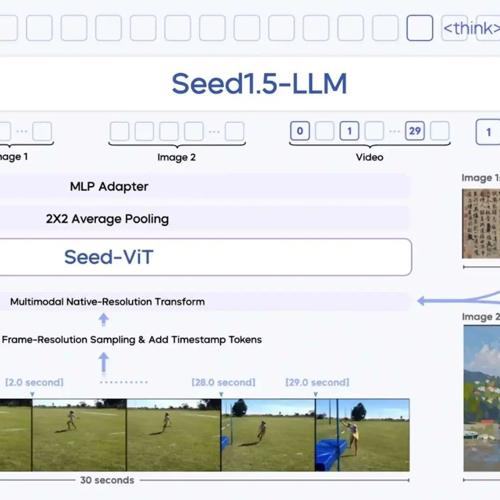
Seed1.5-VL是专为通用多模态理解和推理设计的视觉-语言基础模型,仅用5.32亿视觉编码器和200亿参数的MoE LLM实现顶尖性能,在60个公共基准测试中有38项达到最佳水平。