
多模态推理
刚刚,小扎任命清华校友为Meta AI首席科学家!GPT-4幕后功臣或取代65岁图灵奖得主

Meta 宣布清华校友赵晟佳将担任超级智能实验室首席科学家。此前赵晟佳已与多位顶尖学者合作,并在 OpenAI 深度参与多项研究工作。
阶跃Step 3把推理效率卷到DeepSeek的3倍,还拉来了国产芯片半壁江山|WAIC2025

阶跃星辰发布新一代基础大模型 Step 3,强调多模态推理能力和国产芯片友好性。该模型已在多个榜单上表现出色,并将在7月31日开源。同时,阶跃成立「模态生态创新联盟」,联合多家国产芯片厂商推动大模型落地应用。
昆仑万维开源Skywork-R1V3:38B多模态推理模型,高考数学142分刷新开源SOTA

昆仑万维Skywork-R1V3-38B开源多模态模型在高考数学、物理等跨学科任务上超越同规模闭源模型,实现视觉-语言推理新标杆。支持图像文本联合解析、多图融合、教育级链式思维展示等功能。
ICML2025|多模态理解与生成最新进展:港科联合SnapResearch发布ThinkDiff,为扩散模型装上大脑

多模态理解与生成新方法ThinkDiff在ICML2025上提出,仅需少量数据和计算资源,让扩散模型具备推理能力,并通过视觉-语言训练和掩码策略传递VLM的多模态推理能力,大幅提高图像生成质量。

VRAG-RL:阿里开源多模态RAG推理框架,视觉信息理解与生成的“新引擎”!
阿里巴巴通义大模型团队推出VRAG-RL多模态RAG推理框架,通过视觉感知驱动和强化学习优化提升VLMs处理视觉丰富信息的能力。支持多轮交互、动态调整策略等,应用场景包括智能文档问答、视觉信息检索、多模态内容生成等。

地铁换乘都搞不定?ReasonMap基准揭示多模态大模型细粒度视觉推理短板
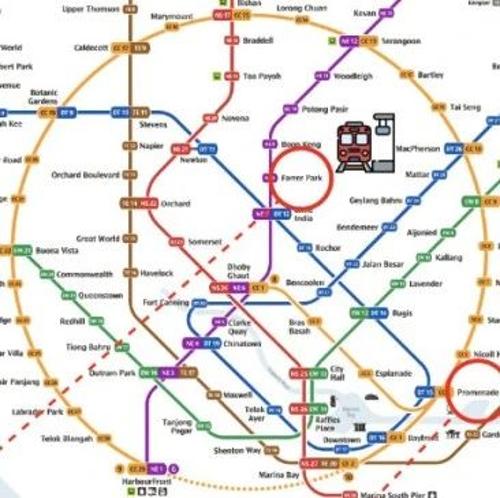
ReasonMap 是首个聚焦于高分辨率交通图的多模态推理评测基准,用于评估大模型在理解图像细粒度结构化空间信息方面的能力。