


Seed1.5-VL 效果展示
-
很模糊的图片也能清晰的抽取出来,并改正代码

-
几何题目也能推理出来

-
OCR能力

推荐大家在huggingface上体验Seed1.5-VL,效果相当惊艳,特别是处理一些复杂表格,也是能完全拿捏的。
网址如下:
https://huggingface.co/spaces/ByteDance-Seed/Seed1.5-VL
-
无边框、无序排列 
Seed1.5-VL 的模型架构
Seed1.5-VL 由一个 532M 参数的视觉编码器和一个 20B 激活参数的专家混合 (MoE) LLM 组成。
它包括三个主要组件:
-
(1) 用于对图像和视频进行编码的 SeedViT, -
(2) 用于将视觉特征投影到多模态令牌中的 MLP 适配器, -
(3) 用于处理多模态输入的大型语言模型。

-
Seed1.5-VL 接受各种分辨率的图像,并使用原始分辨率转换对其进行处理,以保留最大的图像细节。 -
对于视频输入,我们提出了动态帧分辨率采样策略,该策略可以动态调整采样帧率和分辨率。此外,在每帧之前添加时间戳标记以增强模型的时间感知。
Pretraining Data(预训练数据) & Scaling Law(缩放定律)
Seed1.5-VL 预训练语料库包含 3 万亿个多样化的高质量token。此数据根据目标功能进行分类。
-
在预训练期间,发现大多数子类别的训练损失与训练标记之间的关系遵循幂律。 -
子类别的训练损失与相应的下游评估指标之间的关系在局部邻域内似乎是对数线性的(例如,度量 ∼ 对数(损失))。
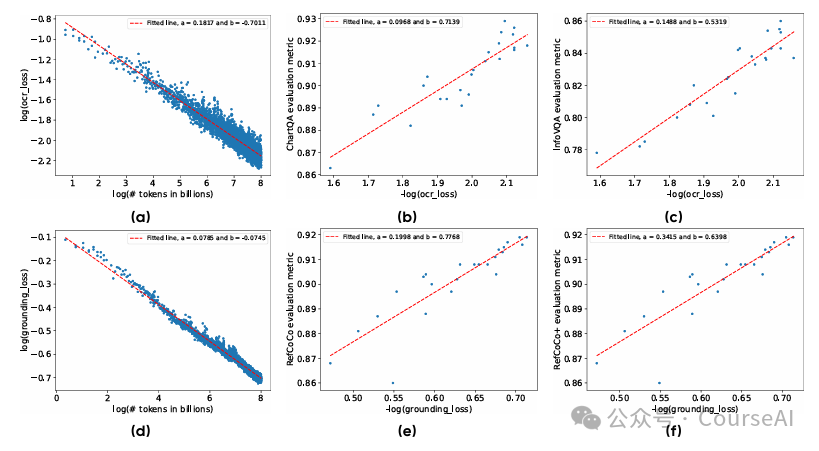
-
(a) OCR 相关数据集的训练损失作为训练标记的函数; -
(b) ChartQA 上排名第一的准确率与训练损失的函数关系; -
(c) InfographicVQA 上排名第一的准确率与训练损失的函数关系; -
(d) 接地相关数据集的训练损失作为训练令牌的函数; -
(e) RefCOCO 的准确性与训练损失的函数关系; -
(e) RefCOCO+ 的准确性与训练损失的函数关系。
此图中显示的评估指标代表预训练后的性能,因此不能直接与强化学习 (RL) 后获得的最终结果进行比较。
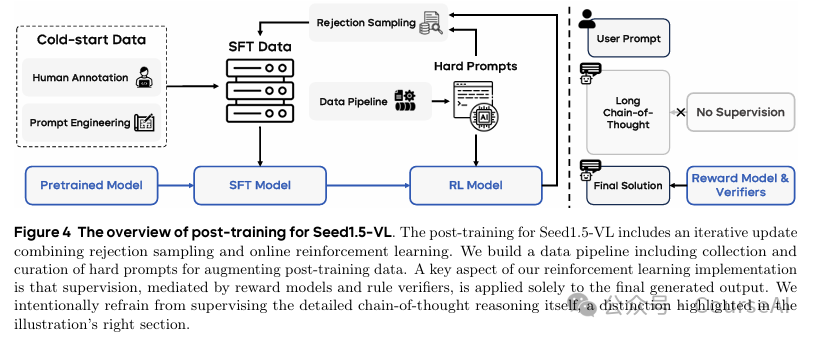
Post-Training(后处理)
Seed1.5-VL 的后训练包括:结合拒绝采样、在线强化学习的迭代更新。
-
通过构建了一个数据管道,包括收集和管理硬提示,以增强训练后数据。 -
强化学习实施的一个关键方面是,由奖励模型和规则验证器调解的监督仅应用于最终生成的输出。
https://arxiv.org/abs/2505.07062 https://github.com/ByteDance-Seed/Seed1.5-VL
(文:PaperAgent)