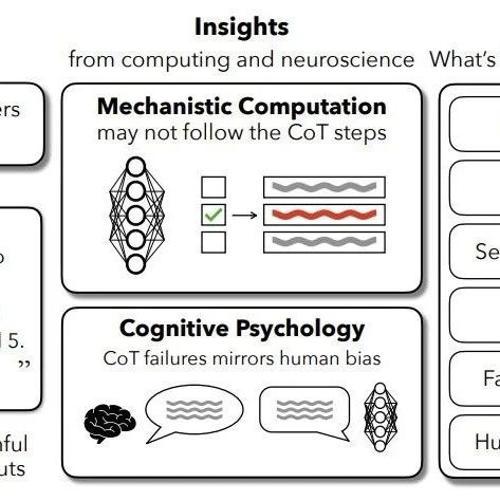
打破“思考陷阱”:DuP-PO算法让AI推理更高效

MLNLP社区致力于促进国内外自然语言处理与机器学习领域内的交流合作。近期,一篇名为《Do Thinking Tokens Help or Trap? Towards More Efficient Large Reasoning Model》的论文探讨了大型推理模型在简单任务中的过度思考问题,并提出了一种新算法DuP-PO以提高模型效率。
MLNLP社区致力于促进国内外自然语言处理与机器学习领域内的交流合作。近期,一篇名为《Do Thinking Tokens Help or Trap? Towards More Efficient Large Reasoning Model》的论文探讨了大型推理模型在简单任务中的过度思考问题,并提出了一种新算法DuP-PO以提高模型效率。

MLNLP社区发布了一篇关于提升大型语言模型复杂推理能力的研究论文《MixtureofReasoning》。文章提出一种新的训练框架MoR,使模型能够自主选择和应用多种推理策略,显著提升了模型在多个数据集上的表现。

MLNLP社区发布了关于多模态数学推理的研究论文《Multimodal Mathematical Reasoning with Diverse Solving Perspective》。该研究提出了一种新的数据集MathV-DP,以及基于Qwen-VL模型的Qwen-VL-DP,旨在提升大型多模态语言模型在数学推理任务中的表现,并强调了从多样化的解题视角学习的重要性。

MLNLP社区发布论文《SELF-CORRECTION BENCH: REVEALING AND ADDRESSING THE SELF-CORRECTION BLIND SPOT IN LLMS》,系统研究LLMs的自我修正盲点,并提出解决方案,揭示了LLMs在实际应用中的可靠性限制。

第五届中国情感计算大会将于7月18日至20日在成都举行,旨在促进情感智能领域的学术与技术交流。会议将涵盖特邀报告、青年科学家论坛等形式,汇聚全球专家学者和产业精英。

MLNLP社区推出FineReason基准,评估大模型的审慎推理能力。通过逻辑谜题训练,提升模型在数学和通用推理任务上的表现,并揭示其反思与纠错能力的瓶颈。

MLNLP社区致力于促进国内外机器学习与自然语言处理的交流与进步。近日,论文提出一种无需训练、在线推理中即可部署的轻量干预机制’ONLY’,显著降低大型视觉-语言模型生成幻觉的能力。

MLNLP社区致力于推动国内外机器学习与自然语言处理领域的学术交流和技术发展。本文提出AI4Research综述工作,涵盖五个方面:科学理解、学术综述、科学发现、学术写作和学术评审。系统性分类方法及新兴研究方向识别,关键应用与丰富资源总结。
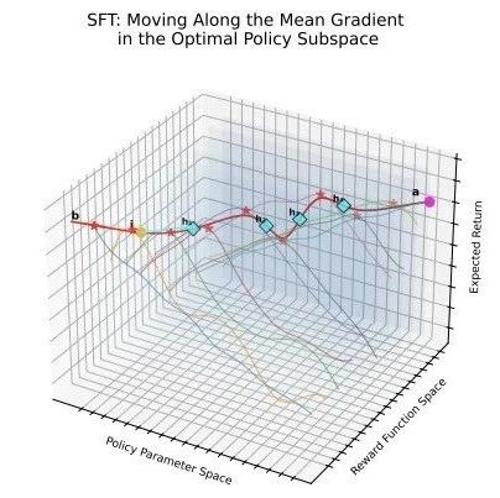
本文探讨了SFT与DPO的理论关联及其改进方法,提出小学习率策略与基于f散度的新目标可显著提升LLM性能,揭示隐式奖励在两者优化中的作用,并为未来统一框架提供了基础。