


论文标题:
Do Thinking Tokens Helpor Trap? Towards More Efficient Large Reasoning Model
论文链接:
https://arxiv.org/pdf/2506.23840
一句话理解:
本文探讨了大型推理模型(LRMs)在处理简单任务时过度思考的问题,并提出了一种名为“DualPolicyPreferenceOptimization”(DuP-PO)的新型算法,旨在提高模型的推理效率。以下是文章的主要内容概述:
研究背景与动机
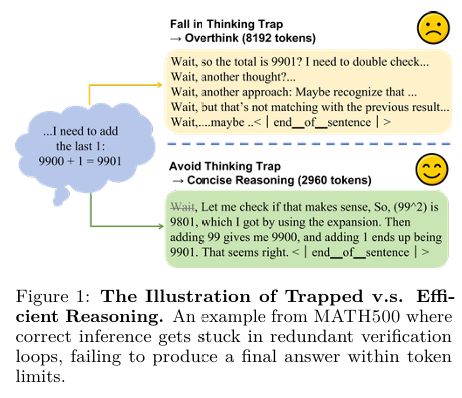
LRMs的优势与局限性:大型推理模型(LRMs)在解决复杂问题时表现出色,但它们在处理简单任务时往往会生成冗长的响应,充斥着诸如“wait”、“hmm”等思考标记(thinkingtokens)。这些标记会触发不必要的高级推理行为,如反思和回溯,从而降低效率。
过度思考的问题:这种过度思考现象被称为“thinkingtrap”,即无意义的推理循环,浪费计算资源而不提高任务性能。文章通过实验发现,错误的响应中包含的思考标记是正确响应的两倍,这表明思考标记的密度与推理失败的相关性更强。
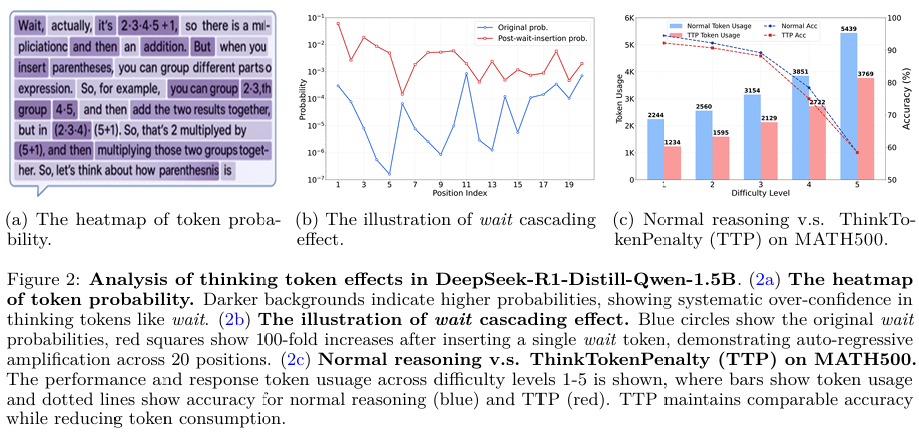
研究方法
DuP-PO算法:文章提出了DuP-PO算法,该算法通过以下三个关键创新来解决过度思考问题:
1.双策略采样(Dual-PolicySampling):在训练过程中,DuP-PO同时从正常策略(πn)和修正策略(πr)中采样响应。修正策略通过将思考标记的logit值设置为-∞,从而系统地消除思考标记,确保模型观察到思考标记多和少的两种响应类型。
2.标记级优势控制(Token-LevelAdvantageScaling):DuP-PO通过为不同轨迹中的特定标记应用不同的优势缩放因子,打破GRPO在轨迹内所有标记分配相同优势的限制。这使得模型能够选择性地鼓励简洁推理,同时抑制导致过度思考的触发因素(如思考标记)。
3.策略塑形(PolicyShaping):通过调整旧策略的概率,确保思考标记的梯度贡献不会被剪切,从而保证在训练过程中对思考标记的持续抑制。
实验
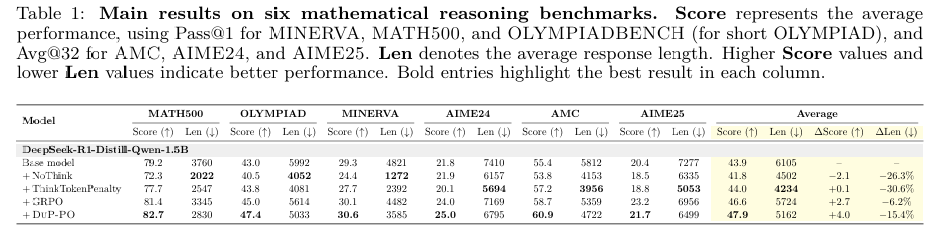
数据集与模型:实验使用了DeepSeek-R1-Distill-Qwen-1.5B模型,并从DAPO-MATH-17K数据集中筛选出1000个中等难度的问题作为训练数据。验证数据集使用AIME24。
基准测试:在六个流行的数学推理基准测试(AIME2024、AIME2025、AMC、Minerva、OlympiadBench和MATH500)上评估DuP-PO的性能。
基线比较:与无思考标记的NoThink方法和思考标记惩罚的ThinkTokenPenalty方法进行比较。
实验结果
性能提升与效率改进:DuP-PO在多个基准测试中显著提高了性能,同时减少了响应长度。例如,在MATH500基准测试中,DuP-PO的准确率提高了3.5%,响应长度减少了24.7%。
与GRPO的比较:DuP-PO在性能、推理效率和训练速度方面均优于GRPO。DuP-PO在80个训练步骤中实现了比GRPO更高的准确率和更少的推理标记。
关键结论
思考标记的必要性:文章通过实验表明,思考标记并非推理所必需,其缺失往往能提高推理效率。
DuP-PO的有效性:DuP-PO通过精确控制思考标记的使用,实现了性能提升和推理效率的平衡,且训练成本低。
未来工作:作者计划将DuP-PO扩展到更大的模型架构和更多样化的领域基准测试中,以验证其可靠性和鲁棒性。
(文:机器学习算法与自然语言处理)