



论文标题:ONLY: One-Layer Intervention Sufficiently Mitigates Hallucinations in Large Vision-Language Models
🎉 背景
大型视觉-语言模型(LVLM)在图像理解与文本问答方面表现优异,但仍存在“幻觉”(hallucination)问题,即生成与图像信息不符的内容,这严重影响其真实应用可靠性。论文提出一种无需训练、在线推理中即可部署的轻量干预机制“ONLY”,希望实时抑制幻觉生成。
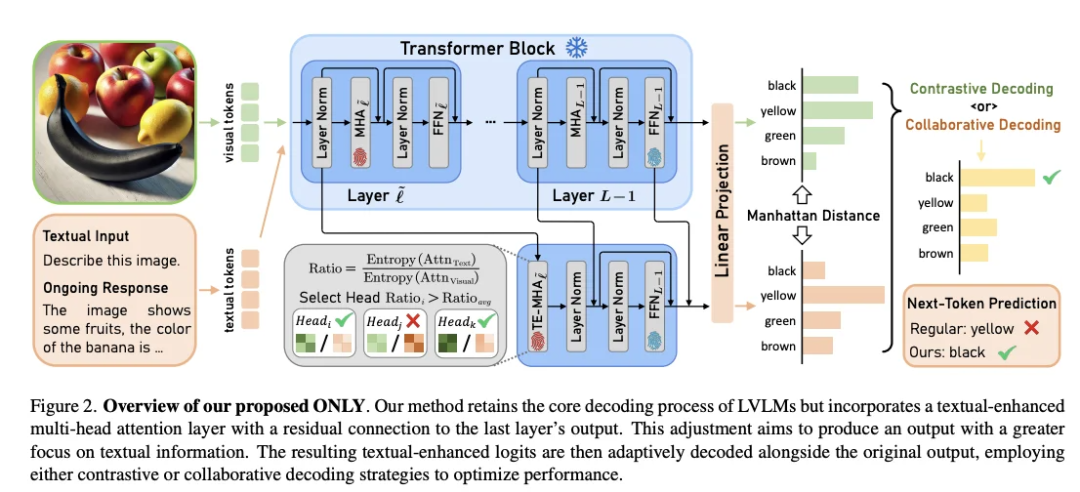
✨ 方法
“ONLY” 是一种解码阶段干预方法,无需修改模型参数,设计如下: 增加一次查询操作(single query)与单层干预(one-layer intervention),在模型生成文本时引入视觉信息反馈。 具体机制:通过计算每个生成 token 的“文本-视觉熵比”(text-to-visual entropy ratio),对关键 token 提升视觉一致性,指导生成与图像更匹配的文本描述。
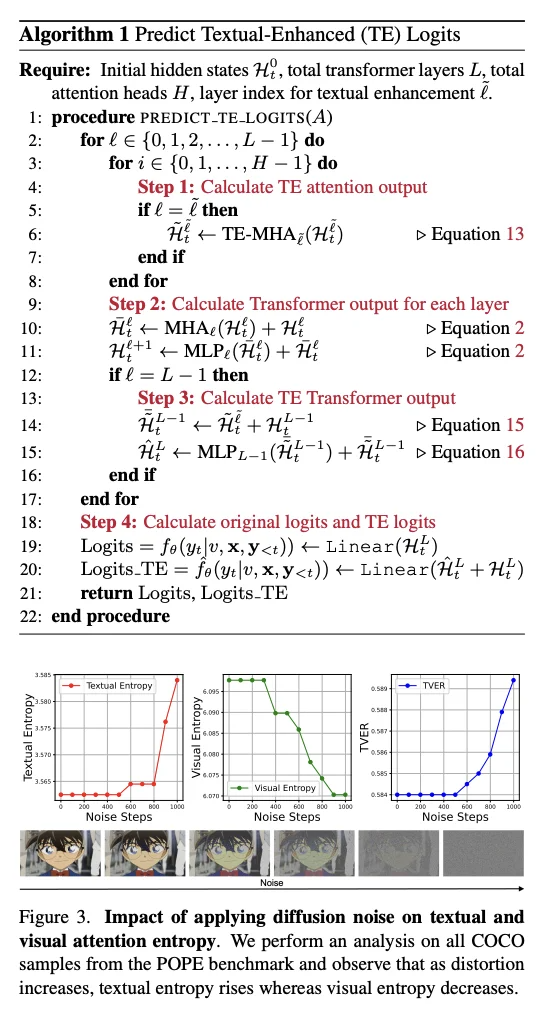
🏆 实验
在多个标准视觉-语言任务上评估,包括图像问答与描述生成。 与基础 LVLM 解码对比,ONLY 显著降低幻觉生成率,同时保持 fluency 与连贯性。 量化结果显示,仅依靠单层干预可取得与更复杂方法相当的性能提升,且延迟极低,适配实时系统部署。
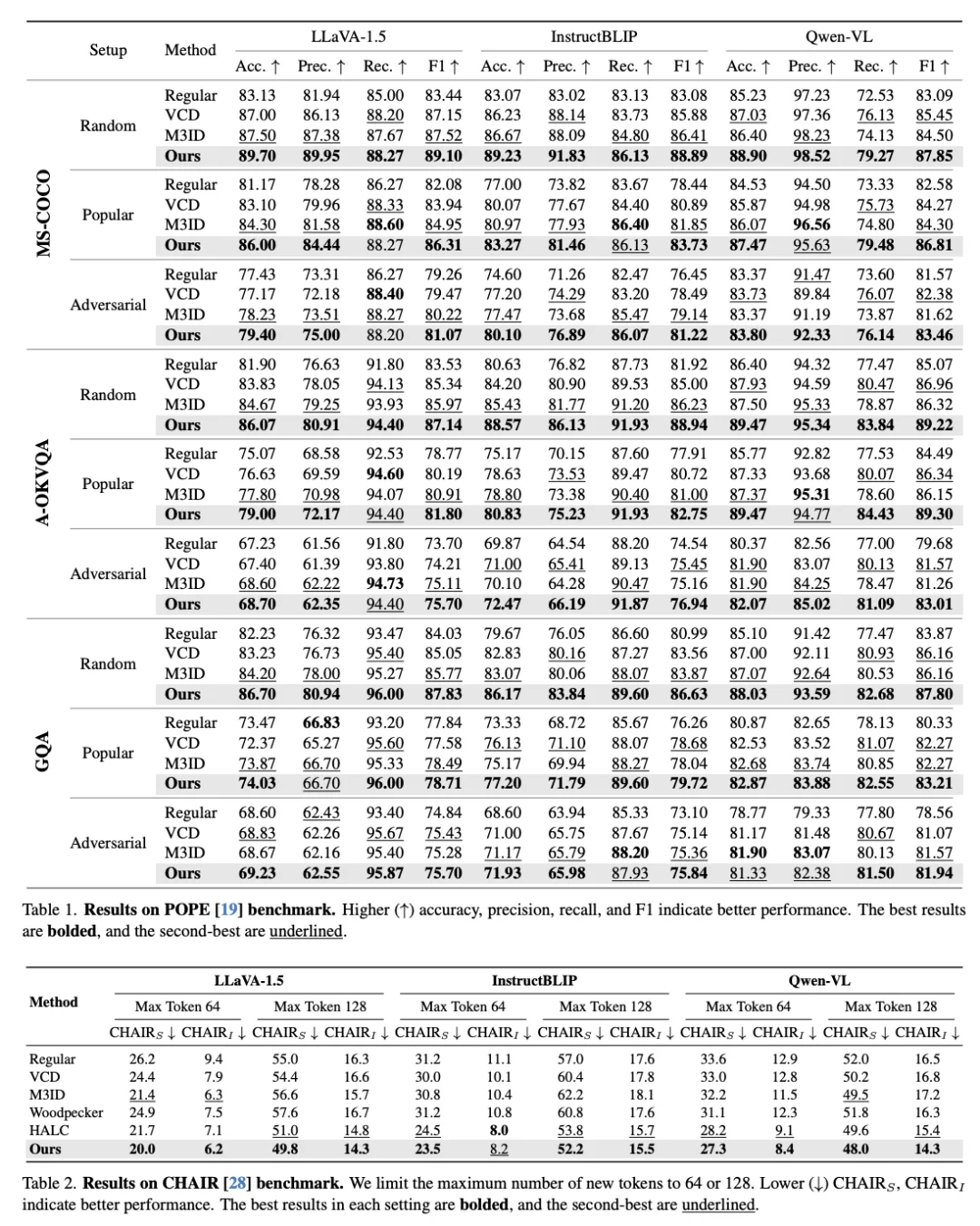
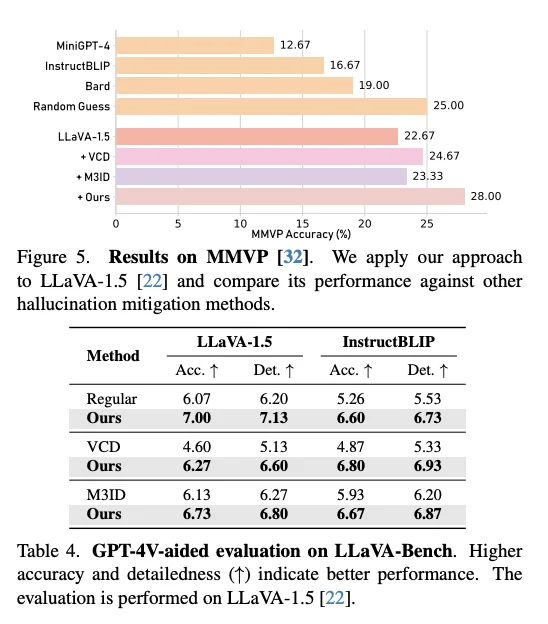
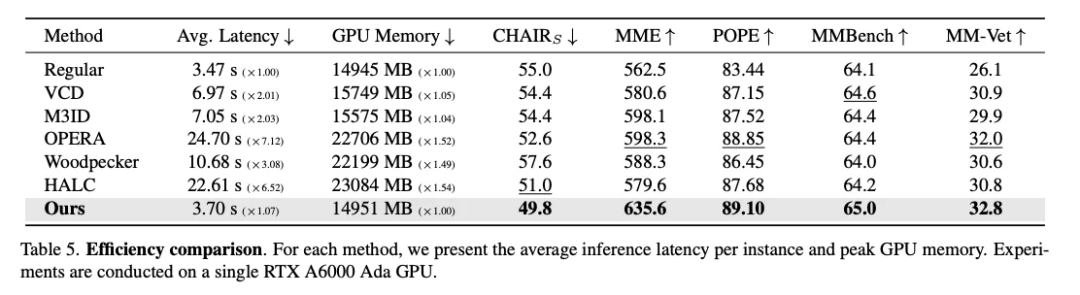
🔍 结论与意义
有效性:ONE‑Layer 干预策略足以在生成阶段抑制幻觉,提升视觉-语言一致性。 实用性:无训练成本、无模型修改、解码实时执行,具备工业实用价值。 展望:该方法可扩展于其他多模态生成场景,提示轻量级干预策略在模型可靠性保障方面的潜力。 Arxiv:2507.00898
(文:机器学习算法与自然语言处理)