
SFT

多模态大模型文心4.5后训练详解
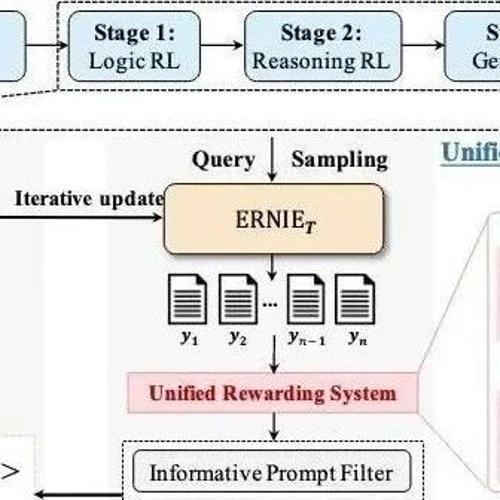
MLNLP社区致力于促进国内外机器学习与自然语言处理的交流与发展,涵盖硕博生、高校老师及企业研究人员。文心4.5开源10个多模态大模型,并介绍其后训练阶段的技术细节。

邱锡鹏老师团队发现SFT与DPO破壁统一:内隐奖励作为桥梁
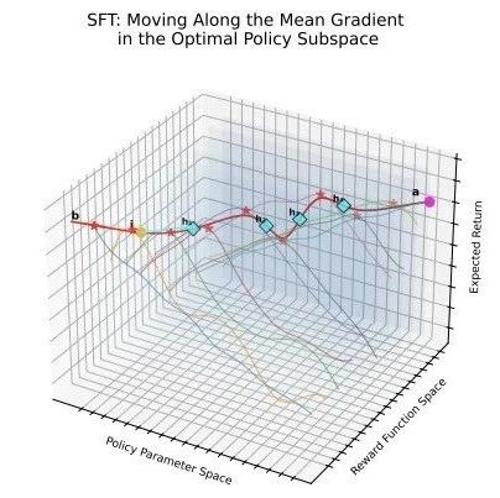
本文探讨了SFT与DPO的理论关联及其改进方法,提出小学习率策略与基于f散度的新目标可显著提升LLM性能,揭示隐式奖励在两者优化中的作用,并为未来统一框架提供了基础。


Graph+图数据库+Agent能做什么?Chat2Graph的尝试思路

今天是2025年5月25日,星期日,北京,晴。文章讨论了技术问题,提到了一个名为Chat2Graph的技术项目,该项目使用图数据库和多智能体系统来实现自然语言与图形数据的交互,强调单主动-多被动混合架构、双LLM推理机及图规划器等关键技术细节。

360智脑开源Light-R1!1000美元数学上首次从零超越DeepSeek-R1-Distill

2B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维