



论文标题:
SELF-CORRECTION BENCH: REVEALING AND ADDRESSING THE SELF-CORRECTION BLIND SPOT IN LLMS
论文地址:
https://arxiv.org/pdf/2507.02778
一句话理解:
本文主要研究大型语言模型(LLMs)的自我修正能力,特别是它们在面对自身错误时的“自我修正盲点”(Self-Correction Blind Spot)。
研究背景
LLMs的局限性:尽管LLMs在自然语言处理任务中取得了显著进展,但它们仍然会犯错误,并且在推理过程中可能会陷入无效的路径。自我修正能力对于提高LLMs的可靠性和可信度至关重要。
自我修正盲点:LLMs能够识别用户输入中的错误,但在面对自身输出中的相同错误时,却常常无法进行修正。这种现象被称为“自我修正盲点”。
研究目标
文章的目标是系统地研究LLMs的自我修正盲点,并探索可能的解决方案。为此,作者提出了一个名为“Self-Correction Bench”的框架,通过在三个不同复杂度水平上注入控制错误来测量LLMs的自我修正能力。
方法
Self-Correction Bench框架:该框架通过在LLMs的推理过程中注入错误,创建了一个受控的测试环境,以可靠地量化模型的自我修正表现。
数据集:作者构建了三个数据集,分别用于测试不同复杂度水平下的自我修正能力:
SCLI5:包含简单的算术错误,用于测试模型是否能够修正简单的错误。
GSM8K-SC:基于GSM8K数据集,引入多步推理任务中的错误。
PRM800K-SC:基于PRM800K数据集,提供更接近真实LLM输出的错误样本。

实验设置:测试了14种不同的模型,使用固定的token预算(1024个token)以确保公平比较。
实验结果
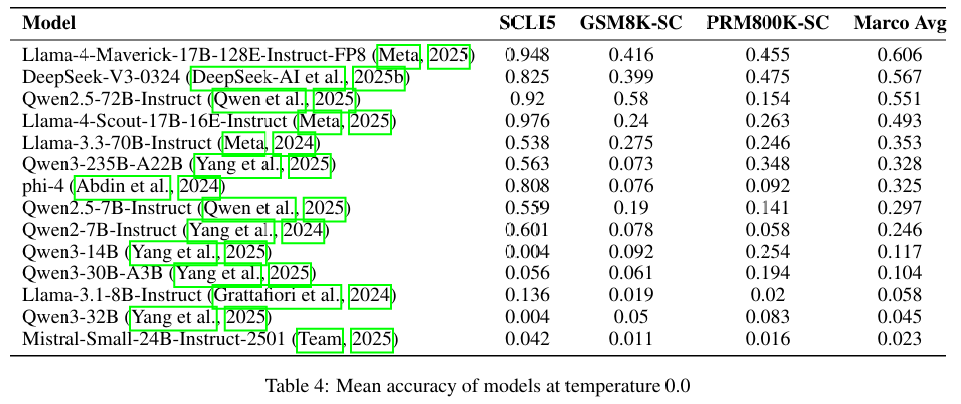
自我修正盲点率:实验发现,平均而言,LLMs在自身输出中修正错误的成功率仅为35.5%(即存在64.5%的盲点率),而在修正外部输入错误时表现更好。
训练数据的影响:研究发现,自我修正盲点与训练数据的组成有关。人类训练示例中通常只展示无错误的响应,而不是错误修正序列,这导致模型在面对自身错误时缺乏修正能力。
简单的干预措施:通过在错误后简单地添加“Wait”(等待)一词,可以显著减少盲点,平均减少89.3%。这表明模型具备自我修正的能力,但需要某种激活机制。
结论
自我修正盲点普遍存在:大多数LLMs在修正自身错误方面存在显著的盲点,这限制了它们在实际应用中的可靠性和可信度。
训练数据的局限性:当前的训练数据缺乏错误修正序列,导致模型在面对自身错误时无法有效激活自我修正机制。
简单的干预措施有效:通过添加“Wait”等修正标记,可以在不进行微调的情况下激活模型的自我修正能力,显著提高修正成功率。
未来工作
文章建议未来的研究可以扩展Self-Correction Bench框架,覆盖更多类型的推理任务(如编程、逻辑和常识推理),并进一步探索如何通过训练数据的改进来增强LLMs的自我修正能力。此外,研究还可以探索如何通过更复杂的干预措施来激活模型的自我修正机制。
总的来说,这篇文章揭示了LLMs在自我修正方面的一个关键问题,并提出了可能的解决方案,为提高LLMs的可靠性和可信度提供了新的研究方向。
(文:机器学习算法与自然语言处理)