


论文地址:
https://arxiv.org/pdf/2507.02804
论文标题:
Multimodal Mathematical Reasoning with Diverse Solving Perspective
一句话理解:
本文是关于多模态数学推理的研究,旨在通过引入多样化的解题视角和反思性监督来提升大型多模态语言模型(MLLMs)在数学推理任务中的表现。以下是文章的主要内容概述:
研究背景与动机
大型语言模型(LLMs)的发展:近年来,LLMs在推理任务中表现出色,尤其是在数学领域。然而,现有的多模态LLMs(MLLMs)在处理需要视觉理解的复杂数学问题时,仍落后于一些封闭源代码的模型(如GPT-4V和Gemini)。
现有方法的局限性:现有的MLLMs通常依赖一对一的图像-文本对和单一解题监督,忽略了多样化的推理视角和内部反思。这限制了模型在多模态数学推理中的表现。

研究目标与方法
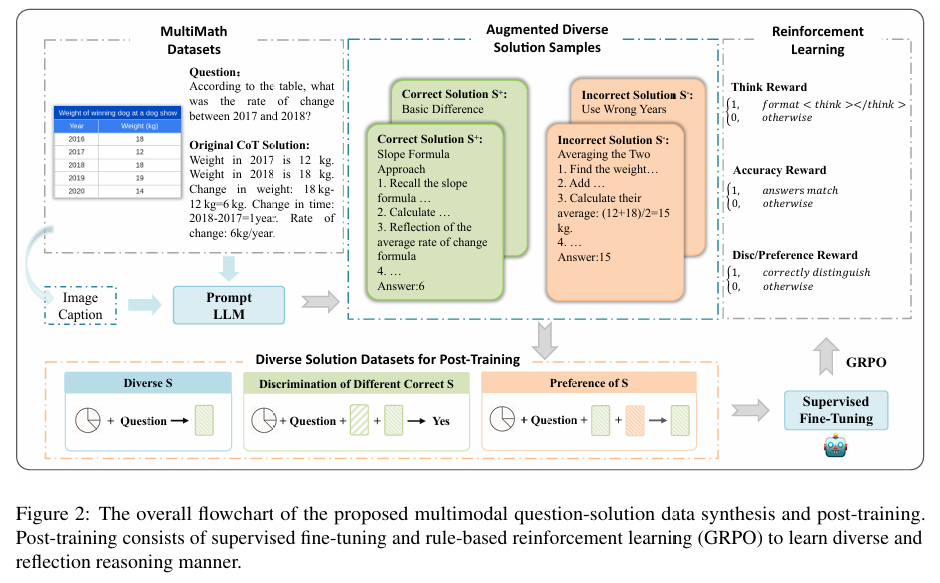
MathV-DP数据集:作者提出了一个新的数据集MathV-DP,该数据集为每个图像-问题对提供了多种多样化的解题路径,以丰富推理监督。
Qwen-VL-DP模型:基于Qwen-VL模型,作者提出了Qwen-VL-DP,通过监督学习微调和基于规则的强化学习(GRPO)进行增强。GRPO是一种规则基础的强化学习方法,结合了正确性判别和多样性感知的奖励函数。
多样化推理视角:该方法强调从多样化的推理视角学习,并区分正确但不同的解题方法。
实验与结果
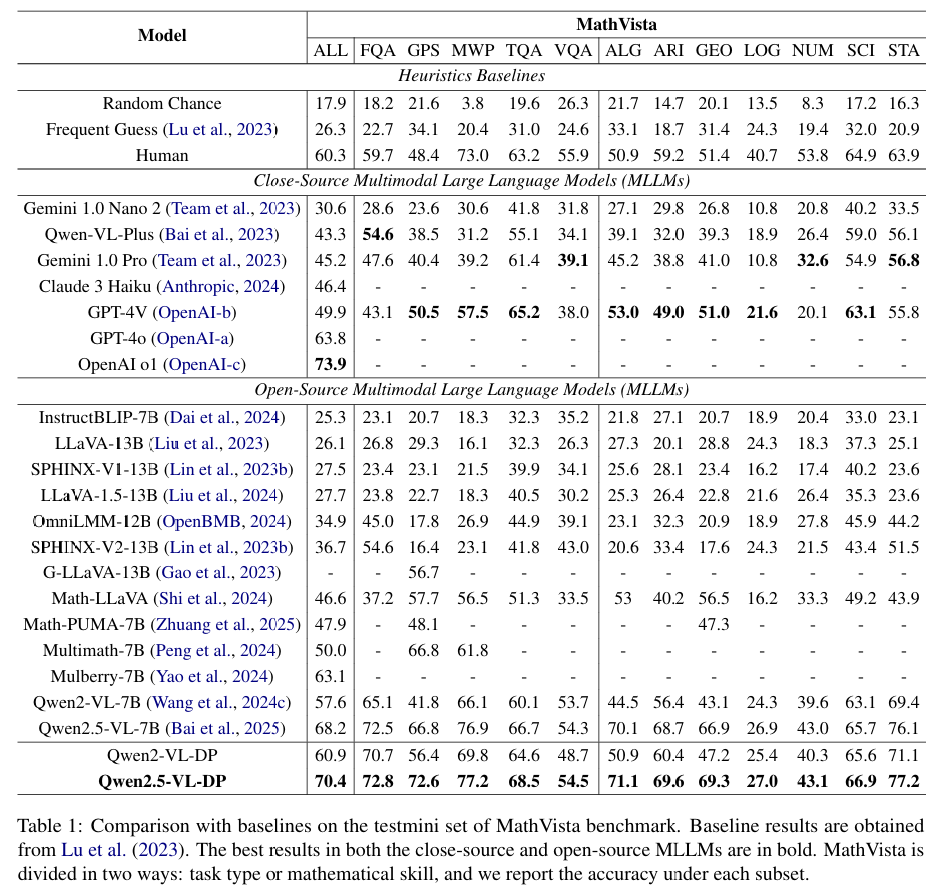
实验设置:作者在MathVista的minitest和Math-V基准测试上进行了广泛的实验,以评估Qwen-VL-DP模型的性能。
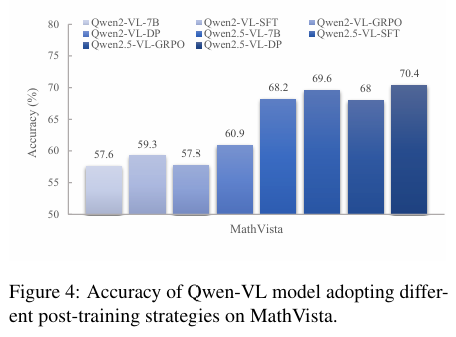
性能提升:实验结果表明,Qwen-VL-DP在准确性和生成多样性方面显著优于之前的MLLMs。例如,在MathVista的minitest上,Qwen2.5-VL-DP的整体准确率达到了70.4%,比基础模型Qwen2.5-VL-7B提高了2.2%。
生成多样性:Qwen-VL-DP在生成多样性方面也表现出色,其有效语义多样性分数在不同生成响应数量下均高于基础模型和其他变体。
结论
多样化视角的重要性:通过从多个解题视角学习,模型能够更好地理解和解决复杂的多模态数学问题。
监督学习与强化学习的结合:结合监督学习和基于规则的强化学习可以有效提升MLLMs的推理能力和生成多样性。
数据集和模型的贡献:MathV-DP数据集和Qwen-VL-DP模型为多模态数学推理领域提供了新的资源和方法,有助于推动相关研究的发展。
限制与未来工作
生成控制的挑战:尽管模型能够生成多样化的解题方法,但无法明确控制单个生成响应的具体视角。未来的工作将致力于使模型能够可控地生成预期的解题视角。
伦理声明
数据许可与使用:文章中使用的模型和数据集均遵循相应的许可协议,旨在训练和测试模型的多模态推理能力。
总的来说,这篇文章通过引入多样化的解题视角和反思性监督,显著提升了MLLMs在多模态数学推理任务中的表现,并为未来的研究提供了新的方向。
(文:机器学习算法与自然语言处理)