
打破“思考陷阱”:DuP-PO算法让AI推理更高效

MLNLP社区致力于促进国内外自然语言处理与机器学习领域内的交流合作。近期,一篇名为《Do Thinking Tokens Help or Trap? Towards More Efficient Large Reasoning Model》的论文探讨了大型推理模型在简单任务中的过度思考问题,并提出了一种新算法DuP-PO以提高模型效率。
MLNLP社区致力于促进国内外自然语言处理与机器学习领域内的交流合作。近期,一篇名为《Do Thinking Tokens Help or Trap? Towards More Efficient Large Reasoning Model》的论文探讨了大型推理模型在简单任务中的过度思考问题,并提出了一种新算法DuP-PO以提高模型效率。

MLNLP社区致力于推动国内外自然语言处理领域的学术与应用交流。最新文章探讨了大型推理模型的安全性问题及其对隐私、法律合规等多方面的影响,强调了构建动态防护体系的重要性以平衡AI能力与发展安全之间的关系。

阿里巴巴国际数字商业集团MarcoPolo团队发布Marco-o1,旨在推进开放式问题解决的大型推理模型。通过集成CoT微调、MCTS和推理动作策略等技术,提高复杂任务处理能力,并在翻译任务中表现出高级理解和推理能力。
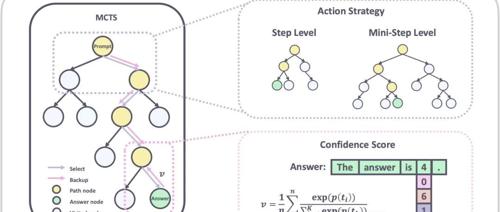
阿里开源Marco-o1,旨在解决缺乏明确标准且奖励难以量化的开放式问题。Marco-o1结合链式思考、蒙特卡洛树搜索等技术增强推理能力,在MGSM上提高了准确性,并展示了扩展解决方案空间和利用更细粒度动作策略的优势。