
监督学习未死,一题训练五小时起飞!华人学者新方法20倍训练效率释放大模型推理能力

加拿大滑铁卢大学TIGER Lab华人学者团队提出One-Shot Critique Fine-Tuning (One-Shot CFT) 新方法,通过生成多个不同版本的解答和多个点评者模型进行点评,让目标模型从“批判答案”中学习推理规律。该方法在计算资源消耗、效果稳定性方面表现优异,比传统的监督式微调和强化学习有明显优势。
加拿大滑铁卢大学TIGER Lab华人学者团队提出One-Shot Critique Fine-Tuning (One-Shot CFT) 新方法,通过生成多个不同版本的解答和多个点评者模型进行点评,让目标模型从“批判答案”中学习推理规律。该方法在计算资源消耗、效果稳定性方面表现优异,比传统的监督式微调和强化学习有明显优势。

下一代AI系统如何改进?让AI自己改!DGM验证了怎样的路径?‘自进化’范式有哪些特征?Sakana AI和UBC提出‘达尔文哥德尔机’探索AI自主学习能力

MLNLP社区发布了关于多模态数学推理的研究论文《Multimodal Mathematical Reasoning with Diverse Solving Perspective》。该研究提出了一种新的数据集MathV-DP,以及基于Qwen-VL模型的Qwen-VL-DP,旨在提升大型多模态语言模型在数学推理任务中的表现,并强调了从多样化的解题视角学习的重要性。

文章总结了强化学习(RL)在大型语言模型(LLM)中的应用,指出传统监督学习的局限性,并阐述了RL作为一种新的扩展方法如何通过弱监督信号和正/负权重机制,解决数据生成性和训练效率问题。
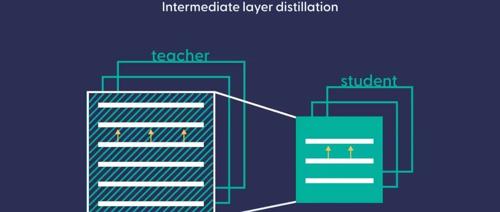
苹果研究人员提出蒸馏扩展定律,基于计算预算及其在学生和教师之间的分配,能够预测蒸馏模型的性能。该发现降低了大规模使用蒸馏的风险,并指导了优化教师和学生模型的计算资源以最大化学生模型性能的方法。
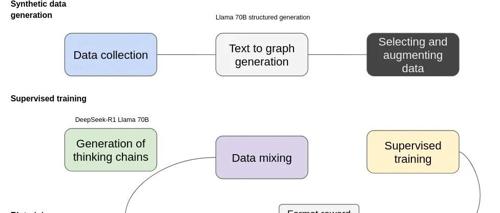
该项目基于Hugging Face Open-R1和trl构建,并重现了DeepSeek R1训练方案。通过合成数据生成、监督训练和强化学习(使用GRPO策略优化)等步骤,旨在提高模型进行文本到图信息提取的能力。



