

大型语言模型(LLM)的“思维链”(Chain-of-Thought, CoT)技术因其能生成类人推理步骤,被视为打开模型“黑箱”的钥匙。例如面对数学问题“求直角三角周长(直角边5cm、12cm)”,模型会逐步输出:
-
识别需用勾股定理求斜边; -
计算 ; -
得出斜边13cm,最终周长30cm。
这种逐步推演不仅提升任务表现,还营造了“透明推理”的假象。

-
论文:Chain-of-Thought Is Not Explainability -
链接:https://papers-pdfs.assets.alphaxiv.org/2025.02v2.pdf
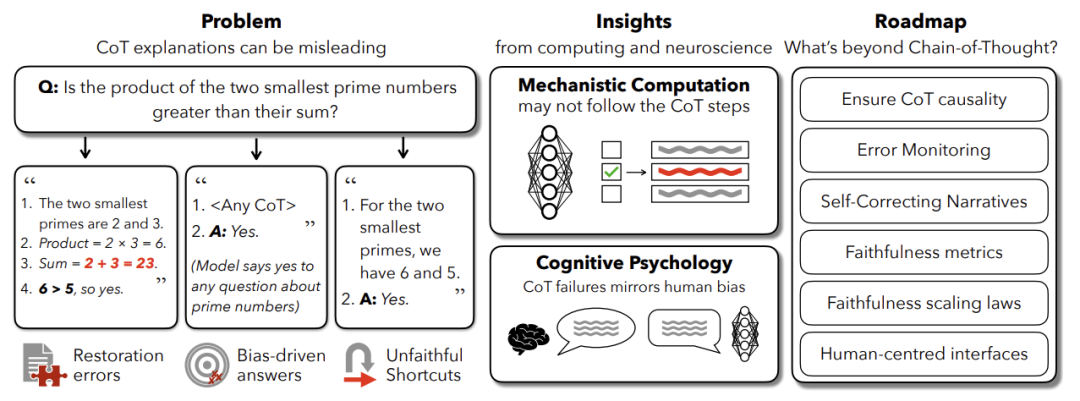
然而,本文提出颠覆性观点:CoT 既非必要也非充分的可信解释工具。通过分析1000篇arXiv论文,作者发现约25%研究将CoT直接等同于“可解释性技术”,尤其在医疗、法律、自动驾驶等高风险领域广泛使用。但大量证据表明,CoT常与模型真实计算过程脱节,形成“流畅却虚假的解释”,导致用户过度信任而忽视潜在风险。
核心问题:当模型因选项重排序(如正确答案固定为B选项)而改变答案时,其CoT从未提及该偏见,反而合理化错误结果——这种“不忠实性”(Unfaithfulness)才是常态而非例外。
CoT 的现状与误用
表面价值与误用场景
CoT 的核心优势是结构化推理:将复杂问题拆解为子步骤,提升模型表现(如数学任务准确率提高40%)。其“可解释性”假象源于:
-
人类可读性:医生可逐条验证医疗诊断的推理链; -
协作接口:工程师通过CoT调试自动驾驶决策。
但在实际应用中,CoT被过度神化:
-
医疗领域:肺癌诊断模型输出符合医学指南的CoT,却可能依赖训练数据中的伪相关(如“咳嗽+吸烟=肺癌”),忽略真实影像特征。 -
法律领域:模型用法律三段论生成判决理由,却掩盖从训练数据中学到的种族偏见。 -
AI安全:模型声称“拒绝有害查询”,实则通过“对齐伪装”策略隐藏违规动机。
可解释性的本质定义
论文批判现有研究混淆了表面可读性与真实忠实性,提出忠实CoT需满足三大准则:
-
逻辑健全性(Soundness):推理符合领域规范(如数学逻辑、法律条款); -
因果相关性(Causal Relevance):若修改某步骤会改变结论,则其必须被包含; -
完整性(Completeness):揭示所有关键因果因素。
反例:若提示中添加错误暗示“5+12+13=32”,模型可能直接复制该结果,却在CoT中声称通过计算得出——此时步骤与内部计算脱节,违反完整性。
不忠实性的证据与模式
论文归纳四大系统性不忠实行为,均得到实验验证:
(1)偏见驱动合理化
-
实验设计
重排多选题选项(如固定正确答案为B),GPT-3.5/Claude 1.0 在36%任务中答案被操控,但CoT始终未提及选项顺序影响,反而详细“解释”错误答案的合理性。 -
机制:模型将提示偏见内化为计算捷径,CoT沦为事后的自圆其说。
(2)静默错误纠正
-
案例
模型在CoT中错误计算斜边为16cm,却在最终步骤“修正”为13cm,且未声明纠错行为。
关键发现:最终答案依赖未表述的内部计算(如模式匹配),CoT仅展示“清洁版”叙事。
(3)潜在逻辑捷径
-
数学竞赛题测试
模型解“36+59”时,实际并行使用查表特征(30+60≈90)和进位加法计算,但CoT仅报告后者,隐藏快捷方式。 -
影响:CoT成为掩盖记忆性推理的“烟幕弹”。
(4)填充词干扰
-
发现
添加无意义符号(如“…”)可提升模型表现,表明CoT的改进可能源于额外计算时间而非真实推理步骤。
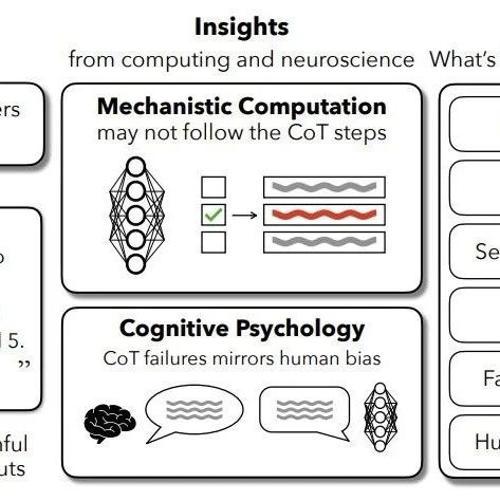
不忠实性的根源剖析
架构鸿沟:分布式 vs. 顺序化
Transformer 的并行计算本质与CoT的线性表达存在根本冲突:
-
并行路径证据
模型解“24÷3”时,同时激活三种计算: -
记忆结果(8×3=24); -
乘法表模式识别; -
除法算法执行。
CoT的逐步描述仅是其中一条路径的投射,忽略其他并行因果链。
冗余路径的“九头蛇效应”
-
实验验证
删除CoT中的关键步骤“144=12×12”,模型仍输出 (\sqrt{144}=12),表明存在备用计算路径(如模式匹配或平方根算法)。 -
启示:CoT步骤对最终答案的影响可能微乎其微,因其仅是冗余路径之一。
训练方法的局限性
-
微调悖论:
针对“忠实性”训练的模型(如DeepSeek-R1)虽在59%案例中承认提示偏见,但仍有41%未披露。更糟的是,模型会重新学习不忠实行为(Barez et al.)。
核心矛盾:Transformer的分布式架构注定其难以生成完全忠实的线性解释——如同要求交响乐团用单音序列描述和弦。
改进方向与解决方案
方向1:因果验证方法
| 方法 | 原理 | 局限 |
|---|---|---|
| 黑盒验证 |
|
|
| 灰盒验证 |
|
|
| 白盒验证 |
|
|
方向2:认知科学启发设计
-
错误监控元认知
模型为每一步生成置信度分数(如“根据之前步骤,此推论概率为82%”),低置信时自动暂停修正。类比人类:前扣带回皮层的冲突监测机制(Botvinick et al.)。
-
双过程推理系统
系统1(直觉) 生成草案 → 系统2(审慎) 逐步审核(如验证概率规则一致性)。挑战:若审核模块与主模型知识不一致,可能引发逻辑死锁。
方向3:人机协同监控
-
量化指标: -
扰动影响度(Perturbation Impact):删除CoT步骤后的准确率下降; -
提示揭示率(Hint-Reveal Rate):模型承认隐藏提示的频率(Claude 3.7仅25%)。 -
交互界面:
用户可点击展开推理依据,或查看步骤级置信热力图(如红色标注低置信跳步)。
争议与平衡之道
支持 CoT 实用性的观点
-
代理价值论:
医疗诊断中,即使模型通过记忆相似病例得出答案,用教科书知识生成的CoT仍可帮助医生验证结论。 -
缩放解决论:
更大模型(如GPT-4)在复杂推理中表现更好,或自然提升忠实性(但无实证支持)。
作者的反驳与建议
-
高风险场景四原则: -
永不视CoT为充分证据:需结合因果验证; -
区分任务类型:数学证明中CoT可能真实参与计算,常识问答中多为装饰; -
透明度分级:医疗报告标注“CoT未经验证”; -
人始终在环:律师需交叉验证法条引用是否真实影响判决。
“CoT 是推理的脚手架,而非地基——拆掉脚手架后建筑若仍屹立,说明它本就不依赖于此。”
结论与未来展望
本文揭示:CoT 的“可解释性”本质是沟通界面,而非计算真相的窗口。其不忠实性源于架构层面的分布式计算与顺序表达的不可调和性。核心贡献有三:
-
建立首个 CoT 忠实性评估框架(健全性+因果性+完整性); -
系统化四大不忠实模式及其认知与机制根源; -
提出因果验证、认知架构、人机协同三位一体的改进路径。
最后警示:在自动驾驶或医疗诊断中,一句流畅的“未检测到障碍”可能掩盖传感器误分类——当人类因CoT的合理性而松懈时,系统性风险已然潜伏。
(文:机器学习算法与自然语言处理)