大模型自信心崩塌!谷歌DeepMind证实:反对意见让GPT-4o轻易放弃正确答案

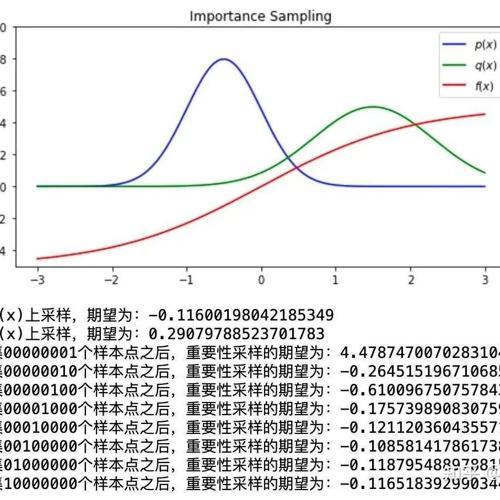
研究发现,大语言模型如GPT-4o和Gemma 3在面对反向意见时过度敏感,并且会轻易改变初始答案,这与其记忆机制有关。研究表明,缺乏记忆的模型可能更容易动摇。
研究发现,大语言模型如GPT-4o和Gemma 3在面对反向意见时过度敏感,并且会轻易改变初始答案,这与其记忆机制有关。研究表明,缺乏记忆的模型可能更容易动摇。

现高校LLM对齐研究课程介绍,涵盖手撕PyTorch五大并行算法DP、TP、PP、CP和EP,以及Backward梯度计算与重叠通信技术。课程内容丰富,提供多卡DeepSpeed RLHF训练及垂域大模型实操项目。
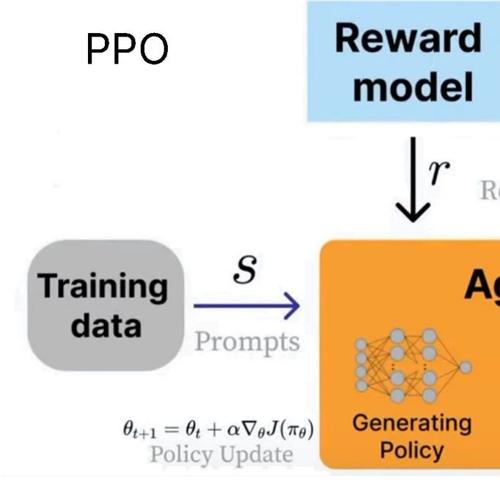
Unsloth发布了关于大模型强化学习的完整指南,涵盖目标、关键作用及在AI代理中的应用等内容,并提供了GRPO、RLHF、DPO和奖励函数的相关信息。