
GRPO
入选ICML 2025!哈佛医学院等推出全球首个HIE领域临床思维图谱模型,神经认知结果预测任务上性能提升15%

大学及 MIT-IBM 沃森实验室的跨学科团队,共同构建了一个专业级医学推理基准测试数据集,并提出了

unsloth制作了一份关于大模型强化学习的完整指南
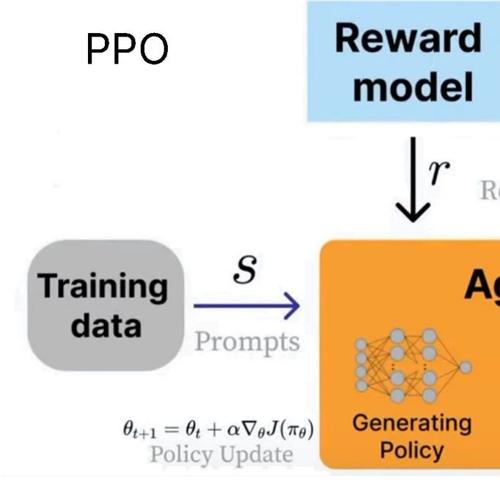
Unsloth发布了关于大模型强化学习的完整指南,涵盖目标、关键作用及在AI代理中的应用等内容,并提供了GRPO、RLHF、DPO和奖励函数的相关信息。
理解GRPO,超越GRPO!GVPO算法详解
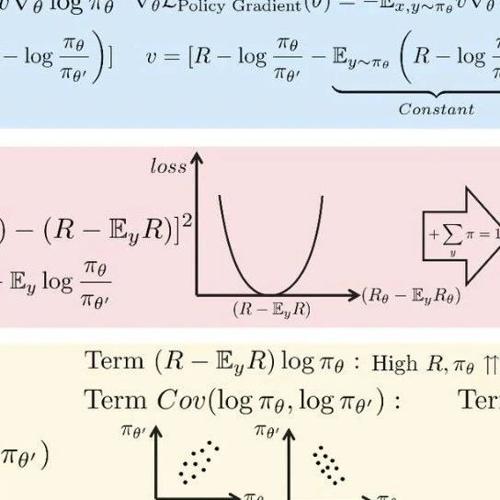
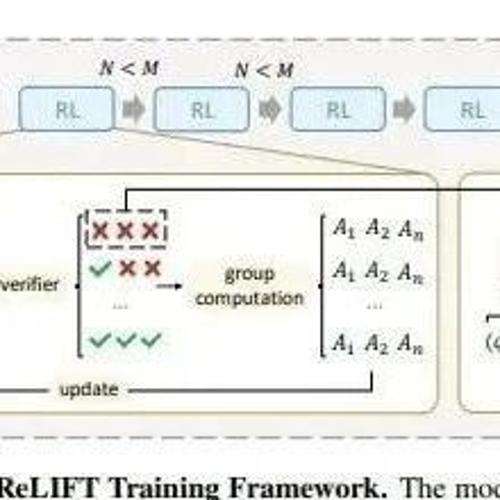
MLNLP社区致力于推动国内外自然语言处理和机器学习领域内的交流合作。文章提出GVPO算法,通过KL约束的奖励最大化解析解解决了GRPO中的训练不稳定问题,并支持多样化的采样分布,具有较好的稳定性和表现。

QwenLong-L1:迈向具备长上下文推理能力的大型语言模型的强化学习方法
本文提出了一种强化学习框架QwenLong-L1,旨在提升大语言模型在长上下文中的泛化能力,并通过逐步扩展上下文长度、混合奖励函数等方法实现这一目标。

Unsloth 发布了 GRPO 的新互动教程 (ipynb notebook)
Unsloth 发布了GRPO的新互动教程,用户可以轻松微调Qwen3-Base并开启其思考模式,实现几乎无监督学习。
DeepSeek-R1发布100天后:全面复盘推理大模型复现研究及未来!

RLMs的最新发展及其复现研究总结,强调监督微调和基于可验证奖励的强化学习方法的重要性,并讨论了数据构建、训练策略和奖励设计的关键要素。