MoE

从 0 手撕 LLM 分布式训练:DP, ZeRO, TP, PP, CP, EP

小冬瓜AIGC发布的X-R1开源框架课程,手撕PyTorch的五大并行算法DP、TP、PP、CP、EP,并实现分布式训练中的关键算法如Backward和MoE。该课程包含实操项目及多个测评工具,适合对LLM技术有兴趣的学员。
LLM不是所有!这几个模型你需要知道!
本文介绍了六种AI模型:LLM、LCM、LAM、MoE、VLM和SLM的特点,包括它们的工作原理、应用场景以及关键点。这些模型在不同的任务中发挥着重要作用,如语言理解和生成、图像处理等。
小红书开源了个模型 142b,激活14b
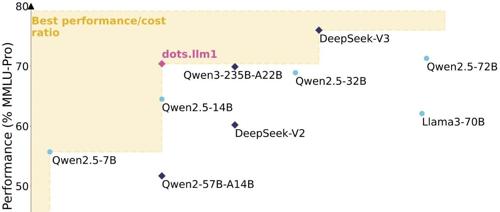
中等规模的dots.llm1模型在仅使用11.2万亿高质量真实数据的情况下达到与Qwen2.5-72B相当的性能水平,上下文长度达32K,参数量为140亿(14B)和1420亿(142B),并提供预训练中间检查点。
ICLR 2025 Oral IDEA联合清华北大提出ChartMoE:探究下游任务中多样化对齐MoE的表征和知识

京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文
智元机器人发布首个通用具身大模型

智元机器人发布首个通用具身基座大模型——智元启元大模型(Genie Operator-1),基于Vision-Language-Latent-Action(ViLLA)框架,由VLM和MoE组成,实现小样本快速泛化。