
AI时代,远不止大语言模型一种,也不要企图通过大模型解决所有问题,复合AI系统(伯克利:即使模型再强大,复合AI系统( Compound AI Systems)都将会是一种领先的应用模式)已经成为共识,掌握各种模型的特点,对于构建高质量的AI应用十分关键,今天就带大家快速了解各类模型的特点。
-
LLM — 大型语言模型 (Large Language Model)
-
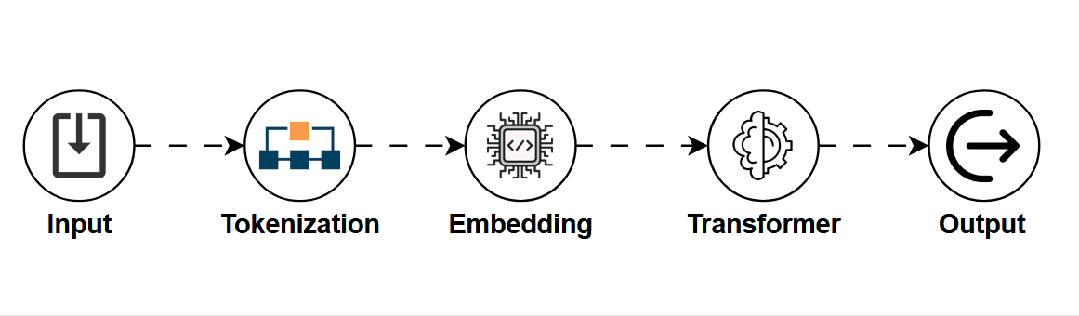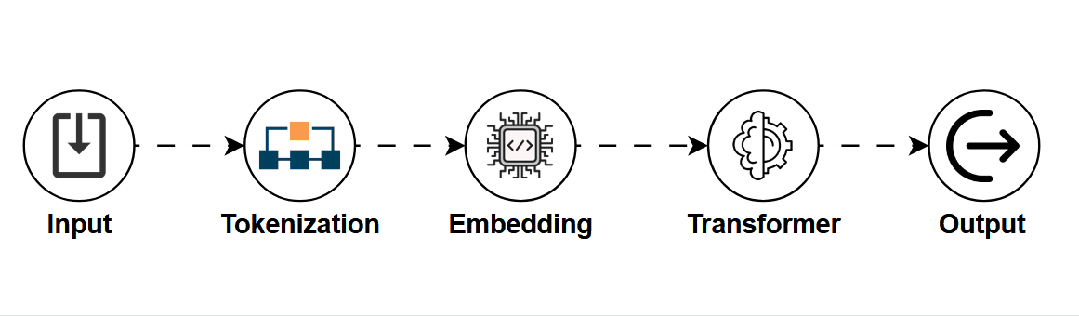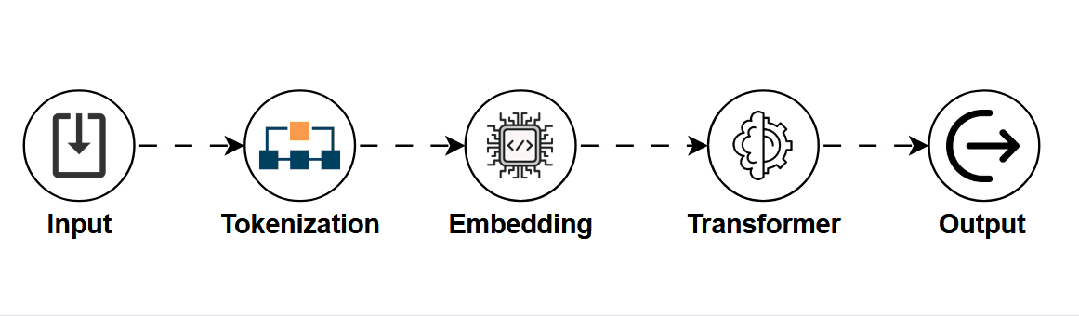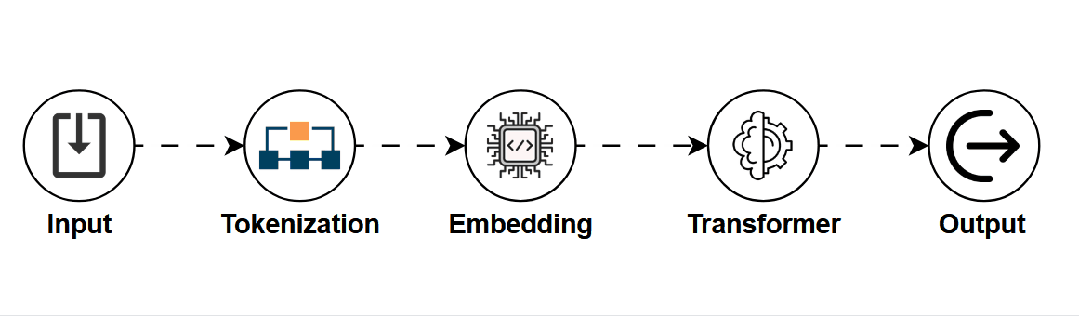
是什么:一种基于海量文本数据训练的概率模型,核心能力是预测序列中的下一个词(或标记),从而理解和生成类似人类的自然语言。 -
如何工作:主要依赖Transformer架构及其核心的“自注意力机制”,使其能够理解长距离上下文关系。 -
用途:聊天机器人、文本创作、代码生成、机器翻译。 -
关键点:通用性强但可能产生“幻觉”(编造信息),且计算成本高。 -
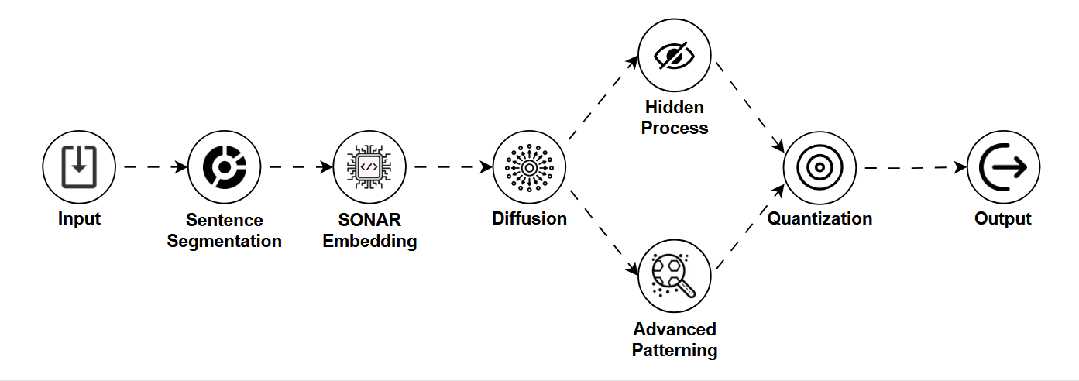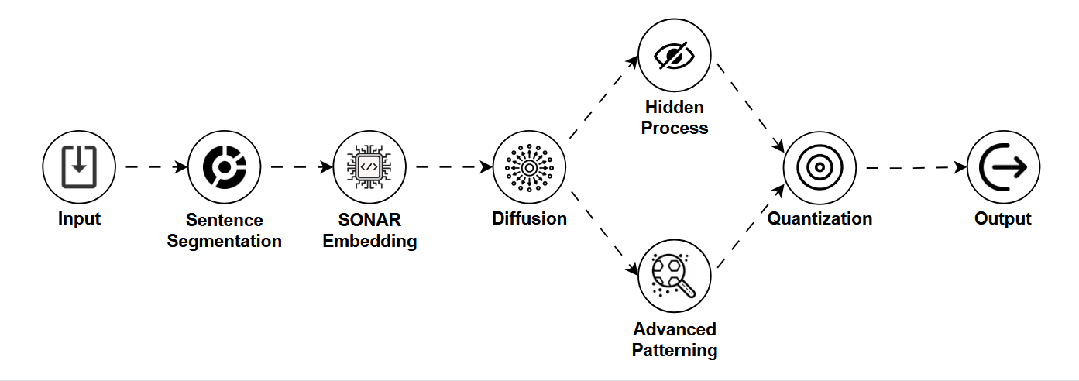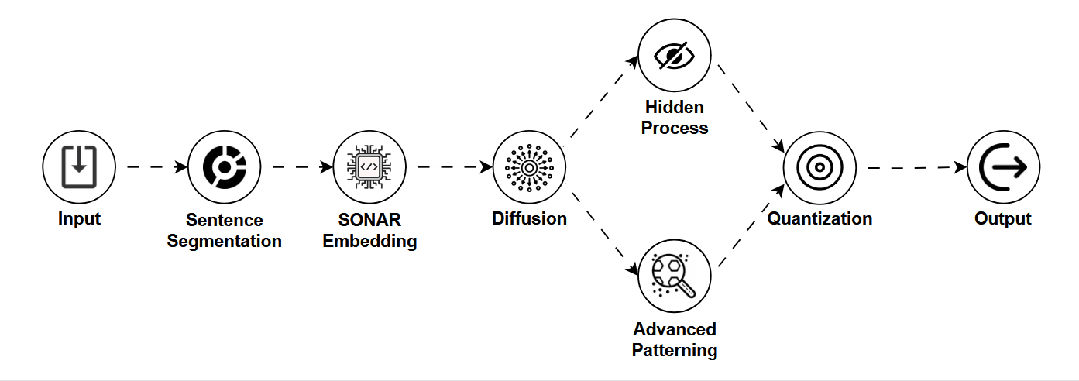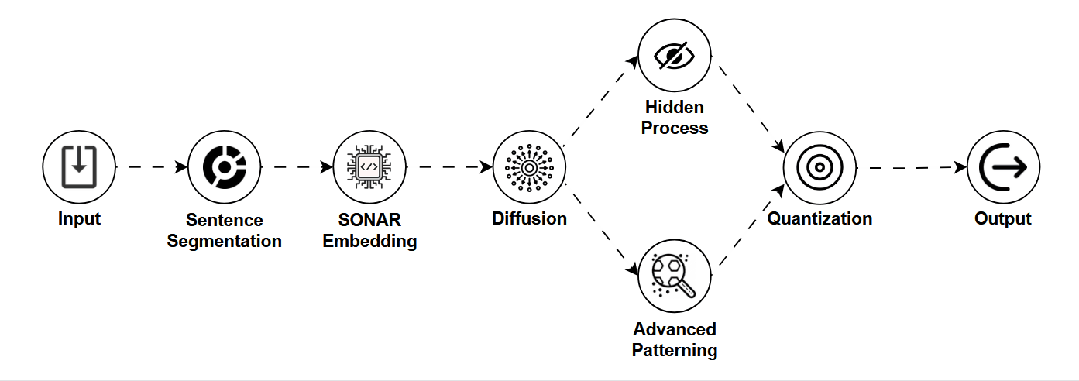
LCM — 潜在一致性模型 (Latent Consistency Model)
-
是什么:一种为提升图像生成(尤其是扩散模型)速度而设计的模型,追求在保持可接受质量的前提下实现高效出图。 -
如何工作:通过学习在“潜在空间”(一种压缩表示)中直接预测从噪声到清晰图像的“捷径”,大幅减少生成步骤。 -
用途:移动端实时AI滤镜、快速图像生成应用。 -
关键点:速度极快,资源消耗低,但图像细节可能略逊于完整扩散模型。 -
LAM — 语言行动模型 (Language Action Model)
-
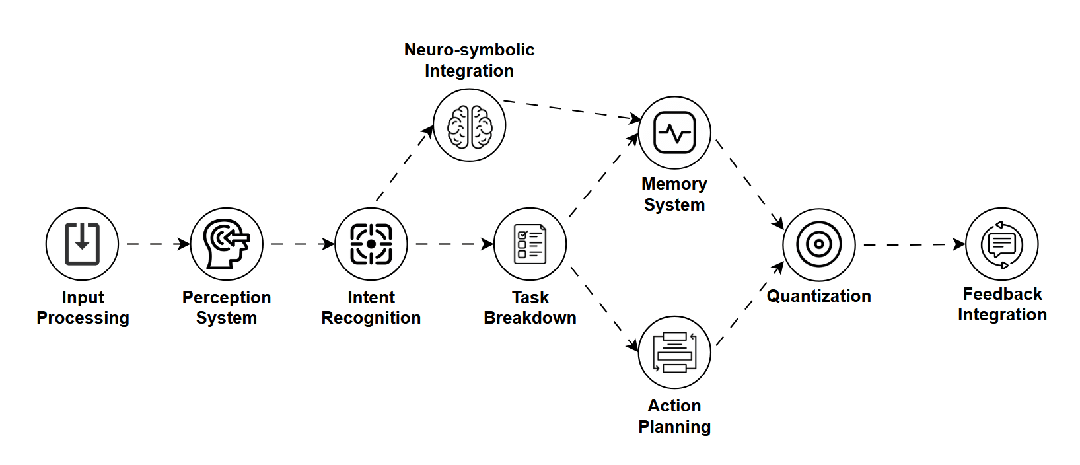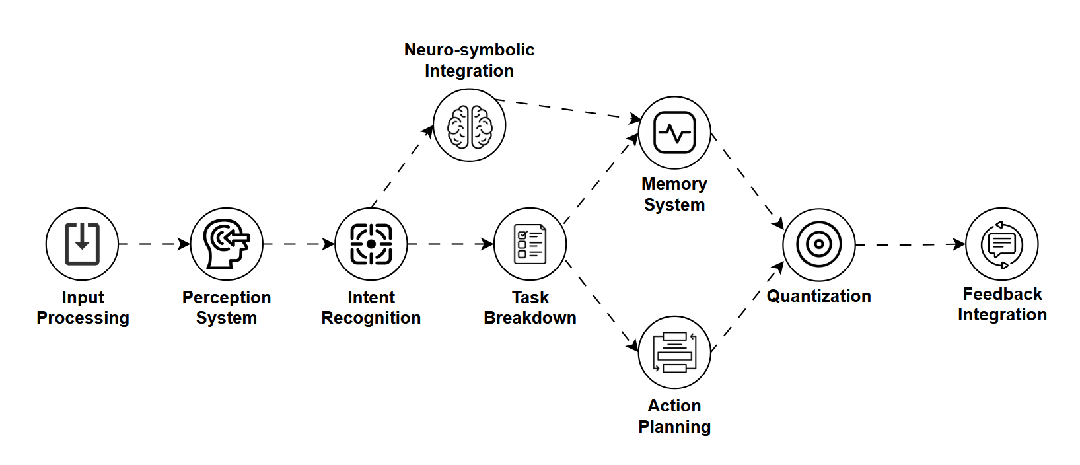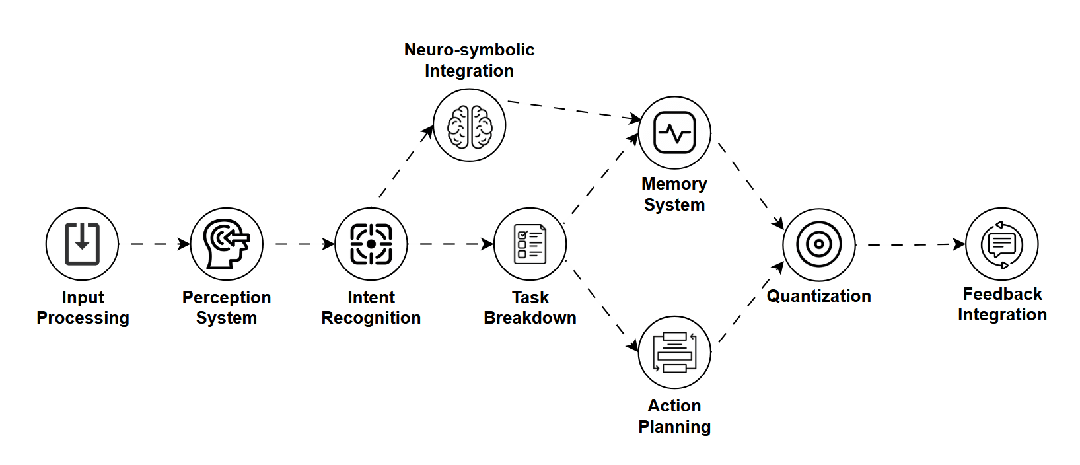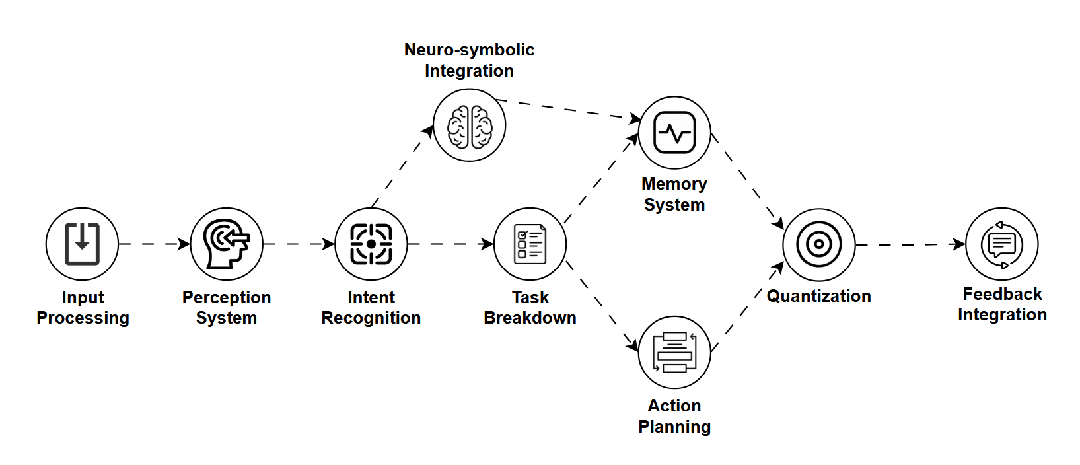
是什么:赋予语言模型实际“行动”能力的模型,它不仅理解指令,还能规划步骤并调用外部工具(如API)来完成任务。 -
如何工作:结合LLM的理解能力、任务规划器和工具使用接口,将语言指令转化为具体操作。 -
用途:AI智能体(如自动化预订、软件操作)、复杂问题客服。 -
关键点:实用性强,连接语言与行动,潜力巨大,但确保行动的可靠性和安全性是挑战。 -
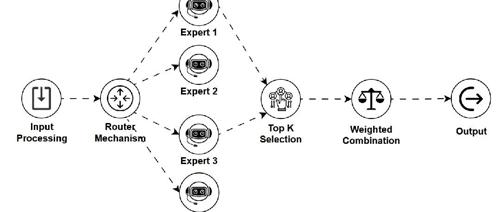
MoE — 专家混合模型 (Mixture of Experts)
-
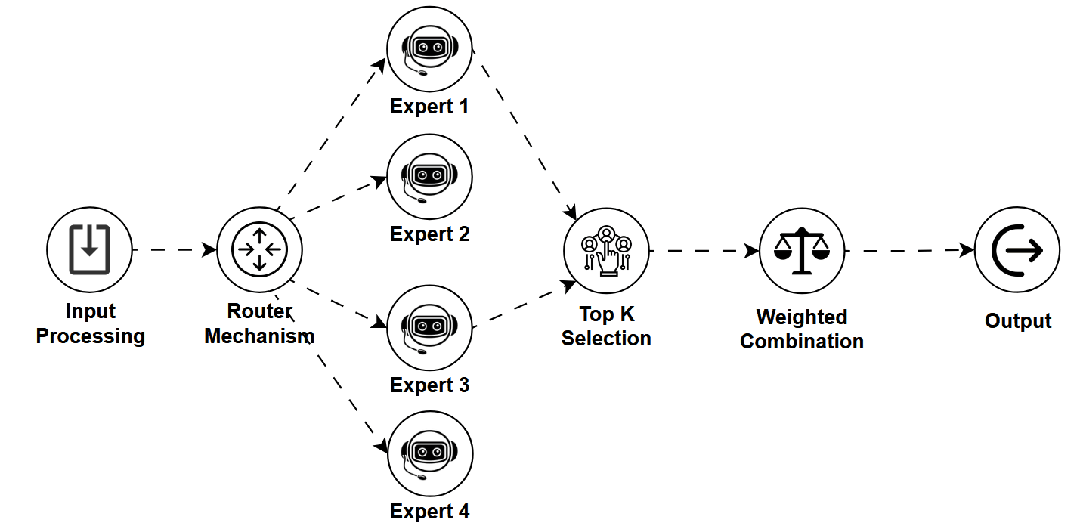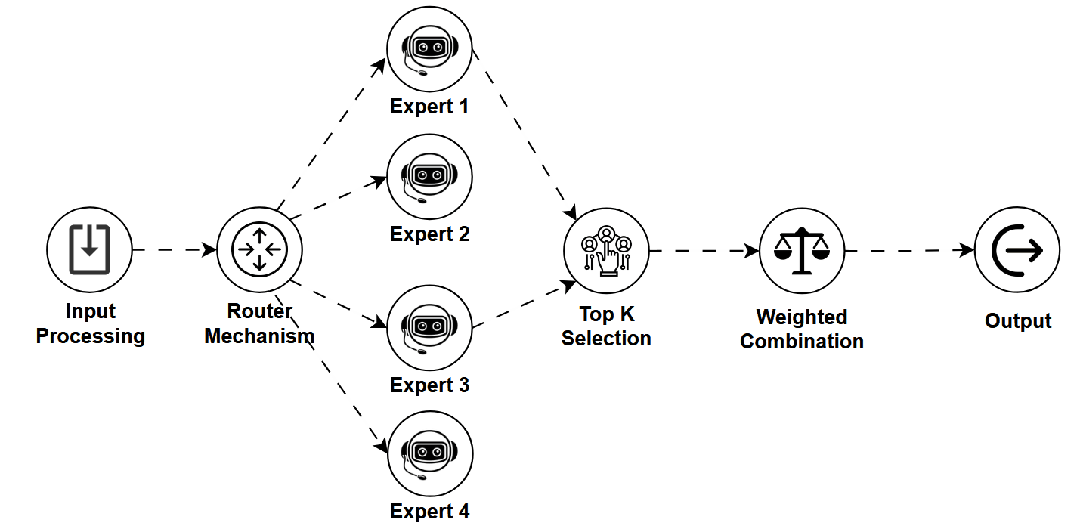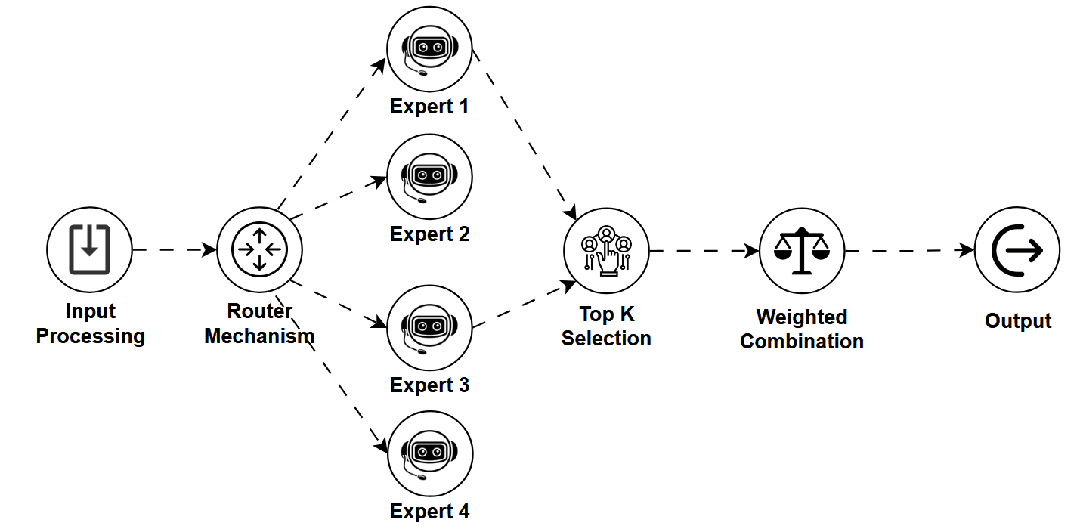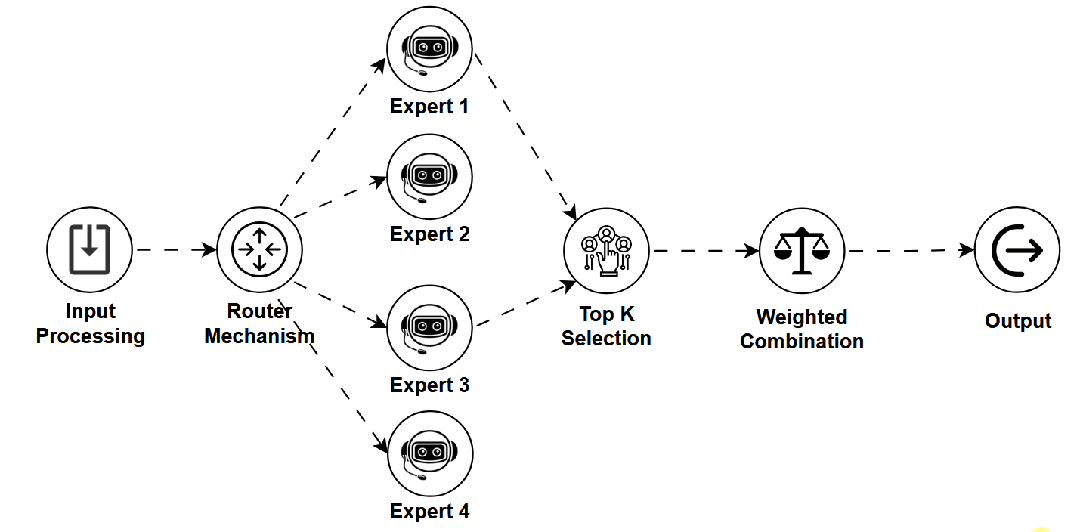
是什么:一种模型架构,包含多个“专家”子网络和一个“路由器”。路由器根据输入动态选择一小部分相关专家进行处理,从而在拥有巨大参数潜力的同时控制计算成本。 -
如何工作:输入数据由路由器分配给最合适的少数几个专家,只有被选中的专家参与计算。 -
用途:构建参数量极大的高性能模型(如某些顶级LLM),并优化推理效率。 -
关键点:参数扩展性好,推理高效,实现了模型规模与计算成本的有效解耦,但训练和路由设计较为复杂。 -
VLM — 视觉语言模型 (Vision Language Model)
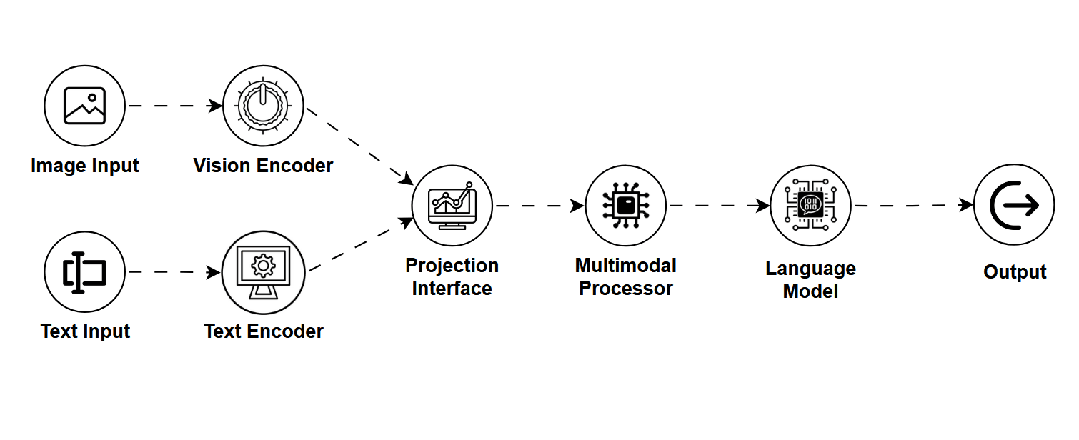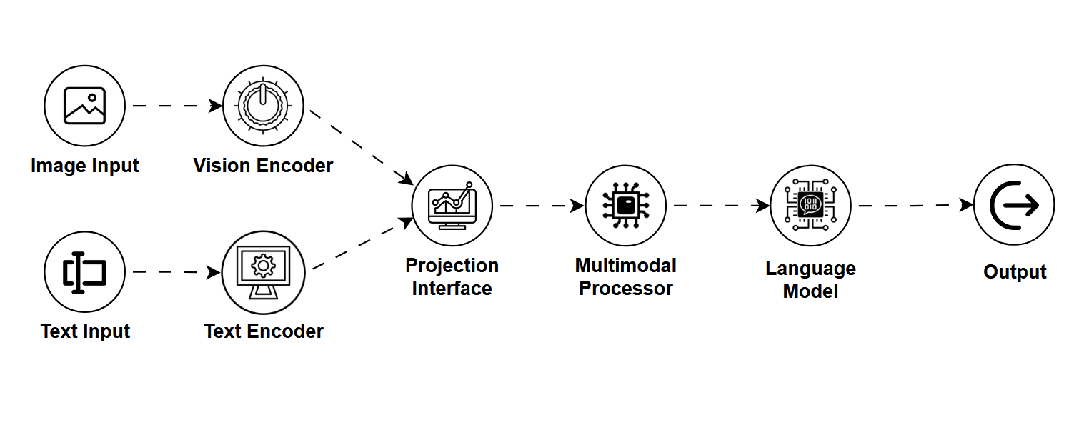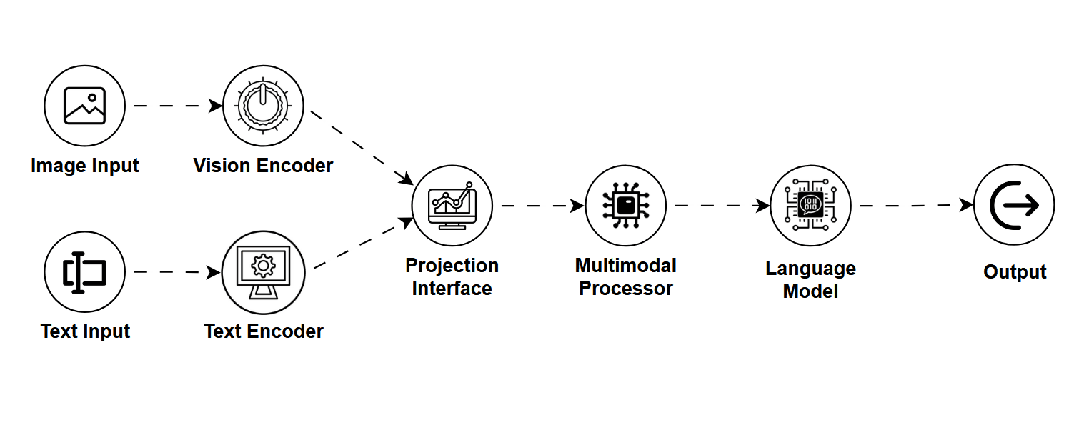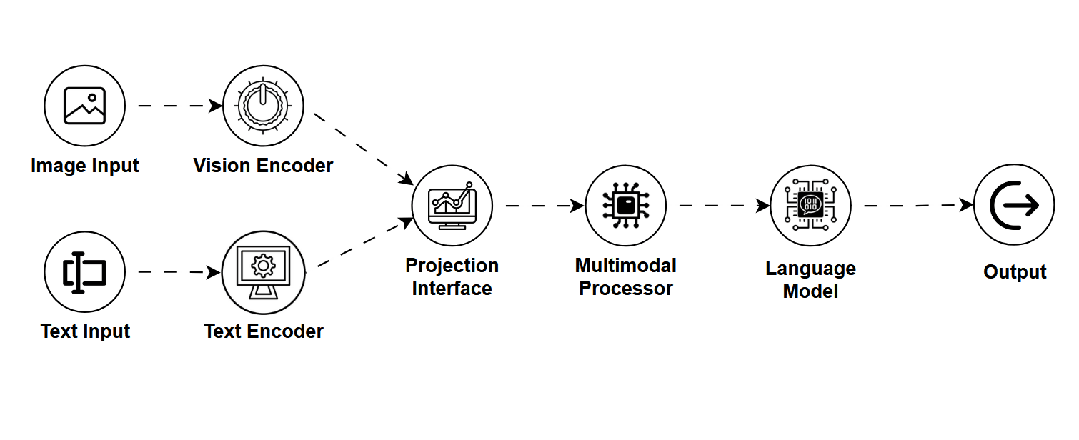
-
是什么:能够同时理解和处理视觉信息(图像/视频)与文本信息的模型,构建两者间的语义联系。 -
如何工作:通常采用双编码器结构(一个处理视觉,一个处理文本),并通过多模态融合机制(如跨模态注意力)将两者信息结合。 -
用途:图像描述生成、视觉问答、图文检索、多模态对话。 -
关键点:实现多模态理解;但模态对齐难度大,数据需求高。 -
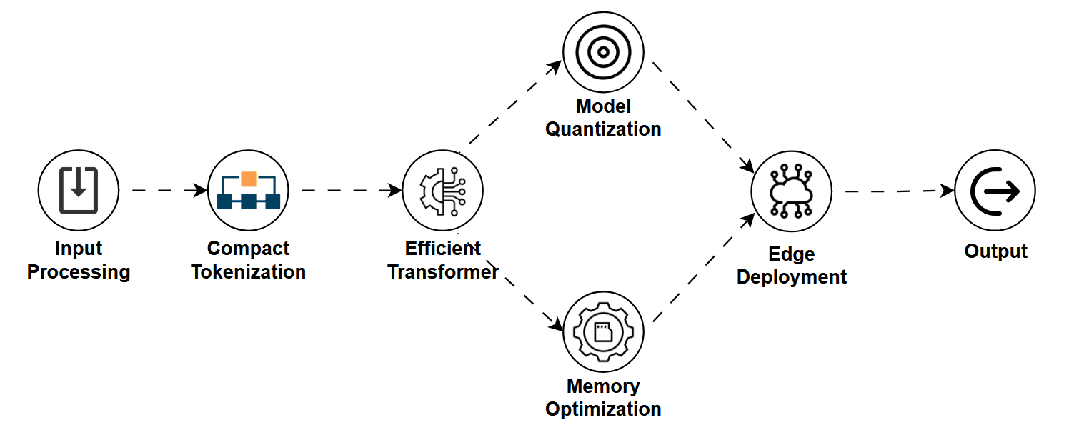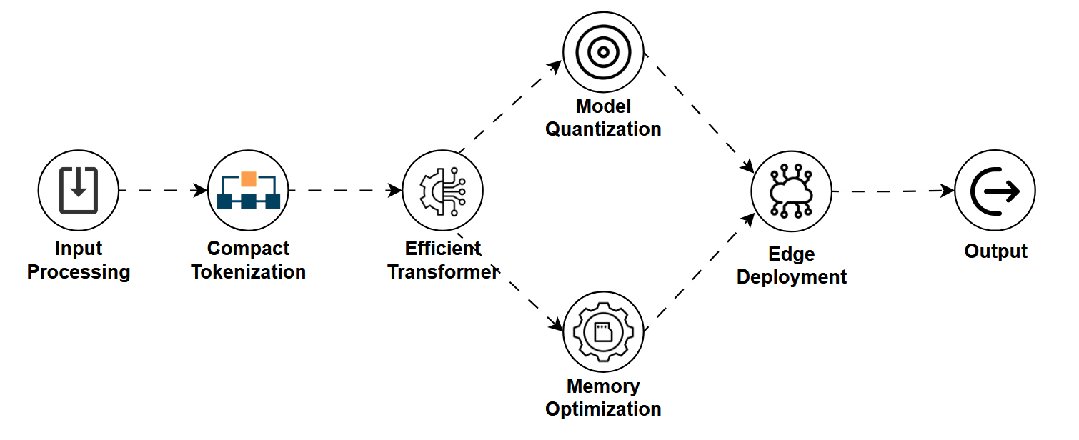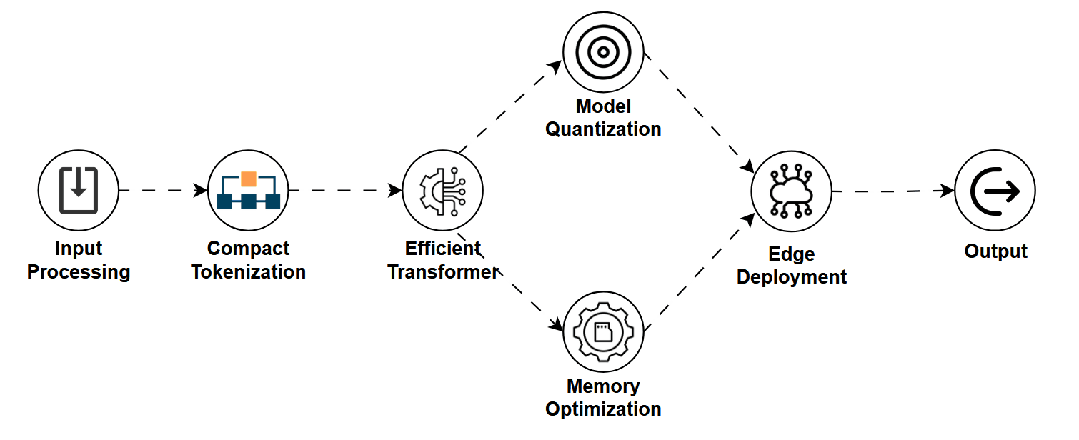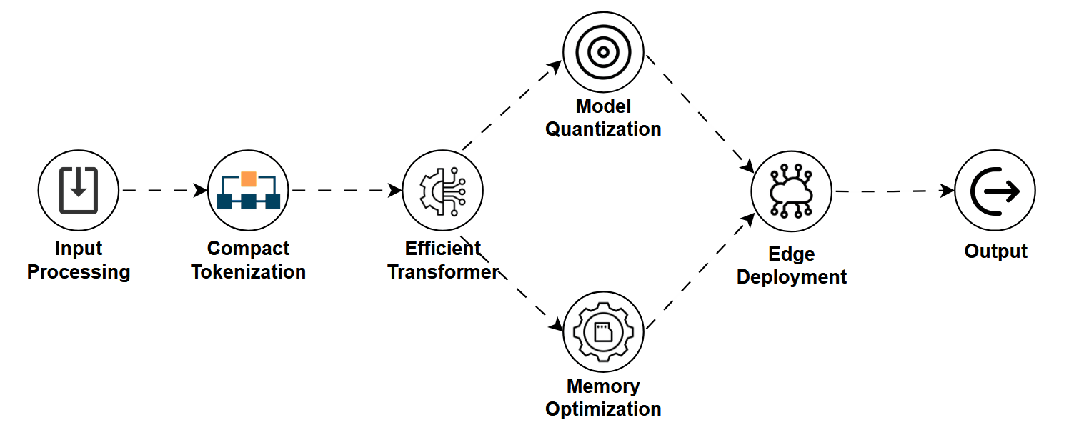
SLM — 小型语言模型 (Small Language Model)
-
是什么:LLM的轻量化版本,参数量和计算需求远小于LLM,专为在手机、IoT等边缘设备上高效运行而设计。 -
如何工作:通过参数削减、架构优化、知识蒸馏(从大模型学习)或量化等技术实现。 -
用途:设备端智能助手、离线翻译、隐私敏感的本地文本处理。 -
关键点:低延迟、保护隐私、可离线,但复杂推理和知识广度不及LLM。 -
MLM — 掩码语言模型 (Masked Language Model)
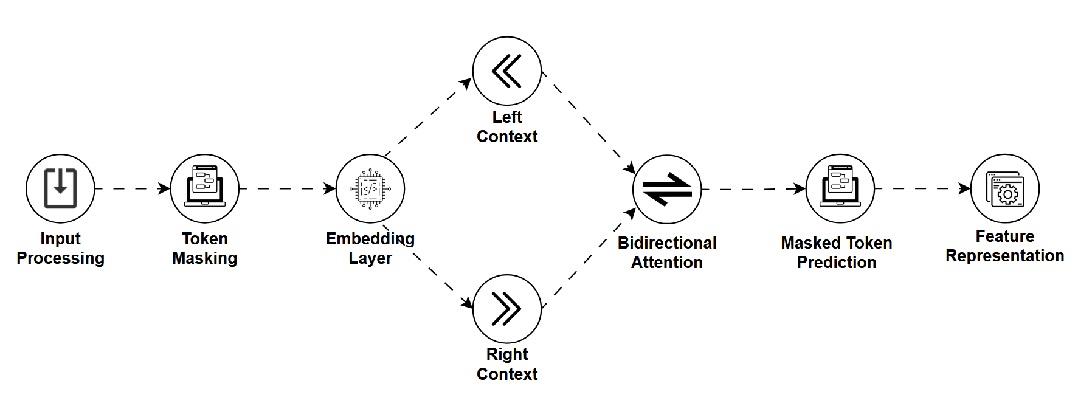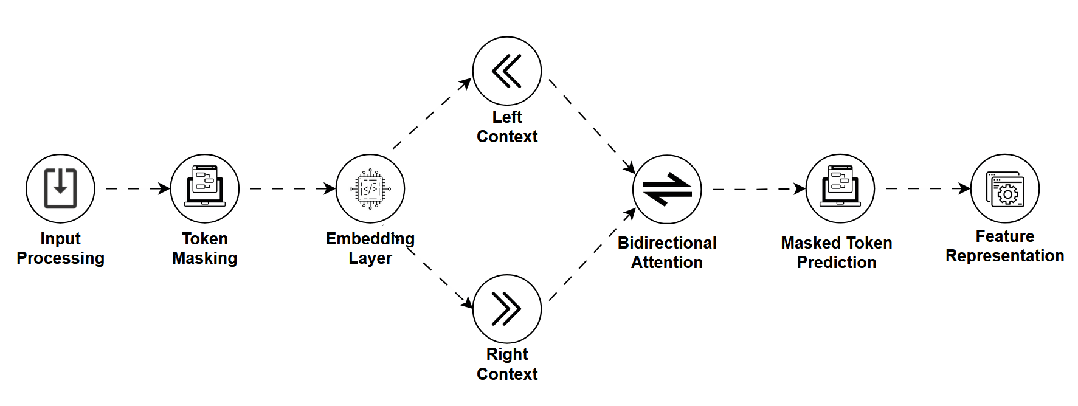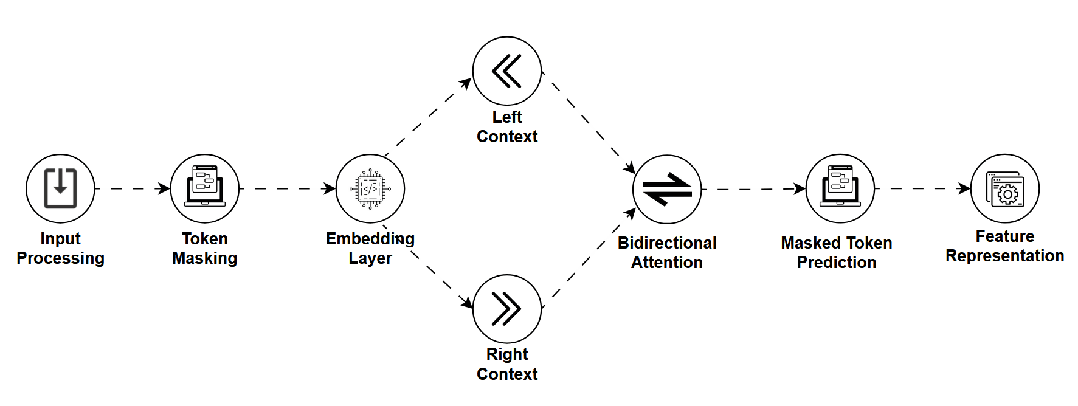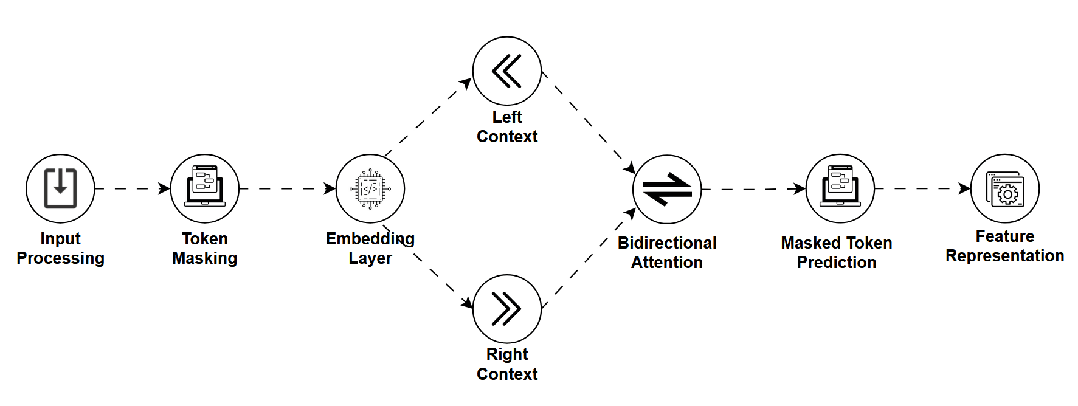
-
是什么:一种通过“完形填空”任务进行预训练的模型(如BERT)。它随机遮盖输入文本中的一些词,并让模型根据上下文预测这些被遮盖的词,从而学习深层的双向语境理解。 -
如何工作:使用双向Transformer编码器,同时关注被遮盖词左右两侧的上下文。 -
用途:主要用于生成高质量的词/句子嵌入表示,服务于文本分类、命名实体识别等自然语言理解任务。 -
关键点:强大的上下文理解能力,但不直接适用于流畅的文本生成。 -
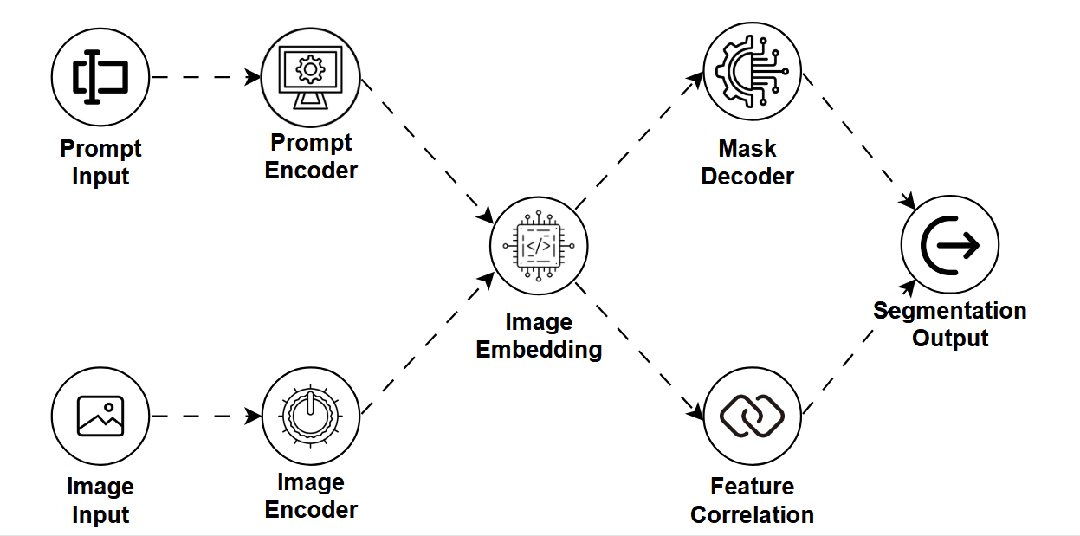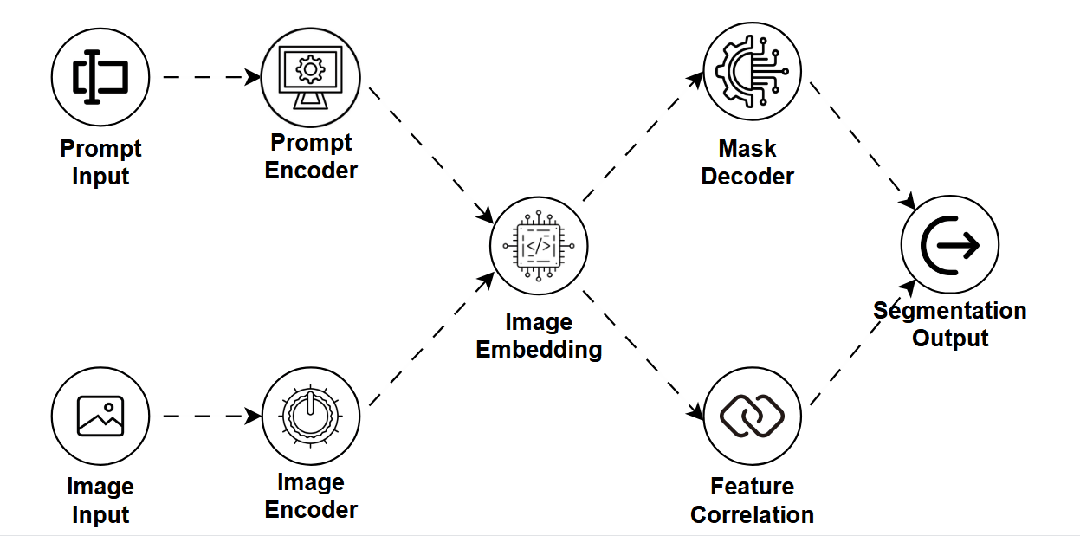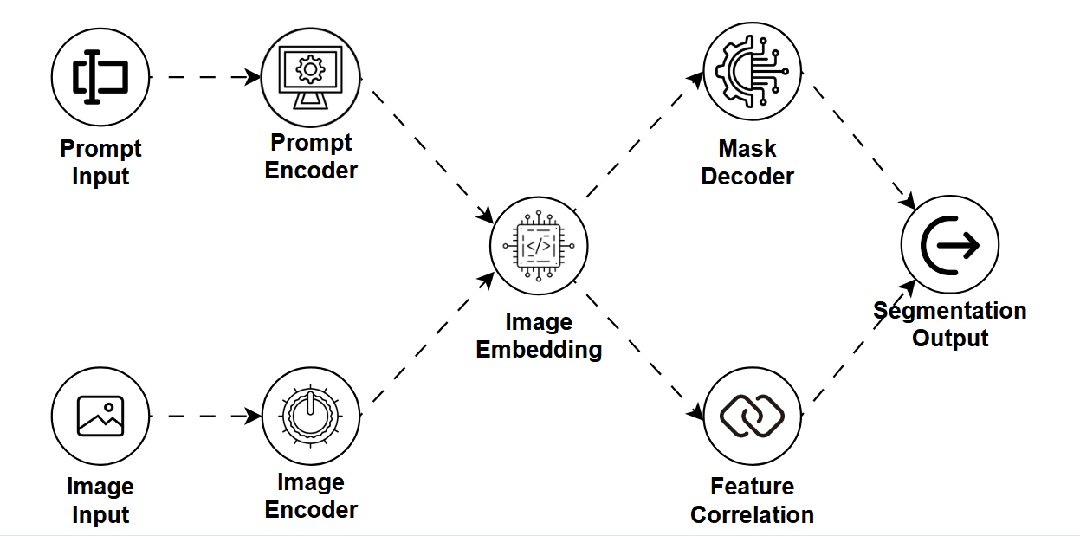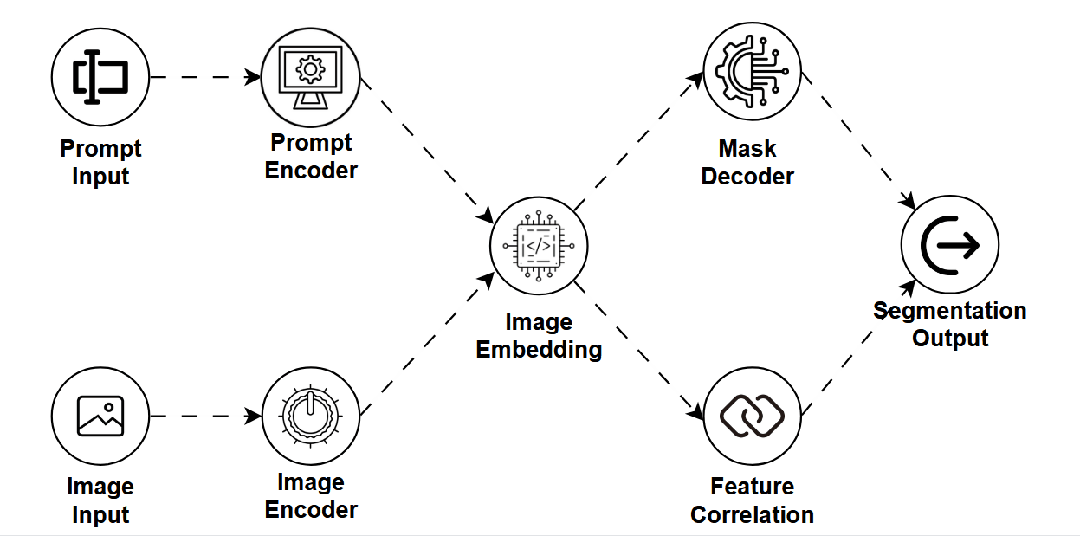
SAM — 分割一切模型 (Segment Anything Model)
-
是什么:一种通用的图像分割模型,能够根据用户提供的简单提示(如点、框)对图像中的任何物体进行精确的像素级分割,无需针对特定类别训练。 -
如何工作:结合强大的图像编码器、提示编码器和高效的掩码解码器,实现对任意目标的快速、精确分割。 -
用途:图像编辑(抠图)、医学影像分析、机器人视觉、数据标注。 -
关键点:零样本泛化能力极强,交互灵活;但本身不识别物体类别(只分割,不命名),需与其他模型配合。
(文:AI工程化)