
阶跃星辰发布新一代基础大模型Step3

阶跃星辰发布新一代基础大模型Step3,主打多模态推理能力,在国产芯片上32K上下文推理效率最高可达DeepSeek R1的300%,计划7月31日向全球开源。
阶跃星辰发布新一代基础大模型Step3,主打多模态推理能力,在国产芯片上32K上下文推理效率最高可达DeepSeek R1的300%,计划7月31日向全球开源。

MLNLP社区介绍其论文《PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning》,提出了一种通过轻量级适配器在测试时学习长文本上下文的方法,显著降低了训练时的内存需求并提高了长文本推理性能。
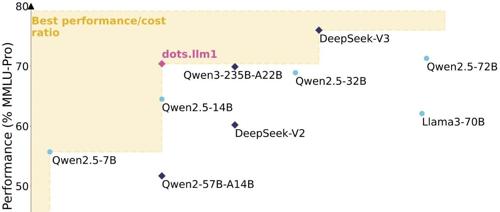
中等规模的dots.llm1模型在仅使用11.2万亿高质量真实数据的情况下达到与Qwen2.5-72B相当的性能水平,上下文长度达32K,参数量为140亿(14B)和1420亿(142B),并提供预训练中间检查点。