
DeepSeek一口气开源3个项目,还有梁文锋亲自参与,昨晚API大降价

DeepSeek 发布了DualPipe和EPLB两个新工具以及训练和推理框架的分析数据,旨在帮助社区更好地理解通信-计算重叠策略和底层实现细节。
DeepSeek 发布了DualPipe和EPLB两个新工具以及训练和推理框架的分析数据,旨在帮助社区更好地理解通信-计算重叠策略和底层实现细节。

昨天DeepSeek开源第一天即收获9000颗星,今日其新项目DeepEP发布两天后已获3900颗星星。支持低精度计算、优化NVLink和RDMA数据转发等特性,专为混合专家(MoE)和专家并行(EP)设计的高效通信库。
今天是DeepSeek开源周的第二天,Alibaba的QwQ-Max预览版引起了关注。DeepEP项目在GPU上实现了显著性能提升,并且已获1000+ GitHub星。DeepSeek强调硬件效率和低延迟通信,其新开源技术让数据传输和计算实现重叠。

DeepSeek发布FlashMLA开源库,支持英伟达Hopper GPU。FlashMLA针对变长序列进行优化,显著提高推理速度和性能。
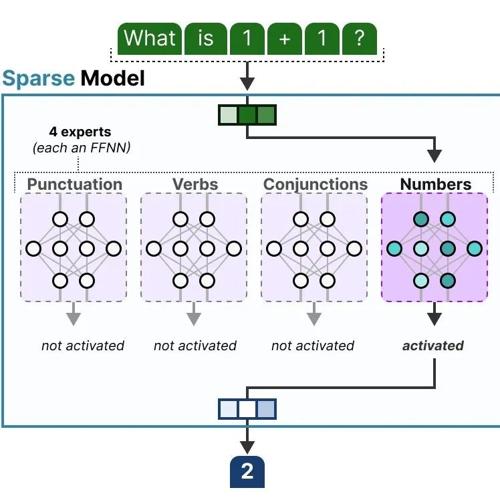
混合专家模型(MoE)通过动态选择子模型处理不同输入,显著降低计算成本并提升表现,核心组件包括专家网络、路由机制和稀疏激活。

字节跳动豆包团队提出UltraMem架构,通过分层动态内存结构、Tucker分解检索和隐式参数扩展三项创新突破MoE架构的瓶颈,推理成本降幅最高83%,速度提升6倍,入选ICLR 2025。

