
GRPO


强化学习推理现状 — 理解 GRPO 以及从推理模型论文中获得的新见解

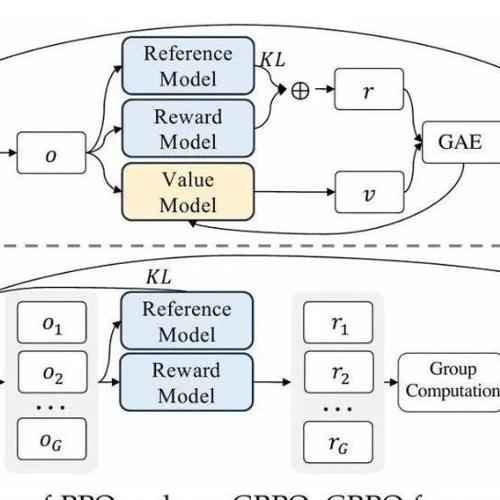
Sebastian Raschka 分享了关于强化学习推理现状的文章内容,包括理解推理模型、RLHF 基础知识、PPO 算法介绍及 GRPO 的应用等,并探讨了训练推理模型的经验和研究论文。



R1-GRPO用于多模态、ChatBI、Gemma3等前沿进展:兼看KTransformers技术分享回顾

enManus-RL增强Agent规划能力训练框架》,https://mp.weixin.qq.co

DeepSeek-R1 解读及技术报告中文版

MLNLP社区致力于促进国内外机器学习与自然语言处理领域的交流合作。最新研究成果《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》通过纯强化学习实现了模型推理能力的自主进化,并结合蒸馏技术实现高效迁移,显著提升了多项任务表现。