理解GRPO,超越GRPO!GVPO算法详解
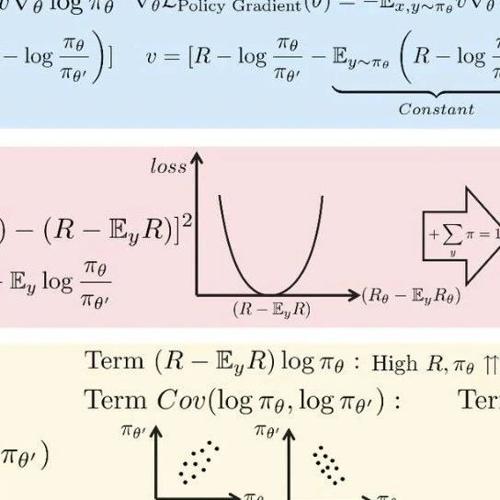
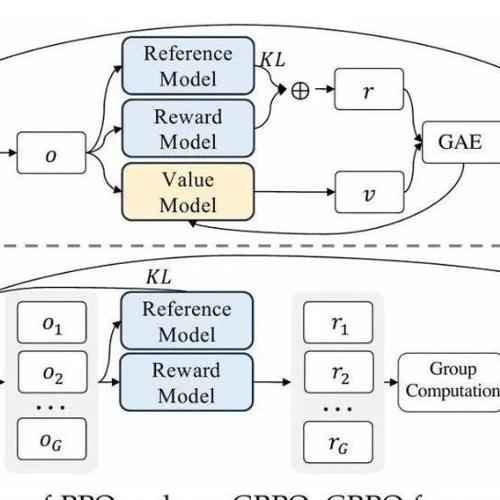
MLNLP社区致力于推动国内外自然语言处理和机器学习领域内的交流合作。文章提出GVPO算法,通过KL约束的奖励最大化解析解解决了GRPO中的训练不稳定问题,并支持多样化的采样分布,具有较好的稳定性和表现。
MLNLP社区致力于推动国内外自然语言处理和机器学习领域内的交流合作。文章提出GVPO算法,通过KL约束的奖励最大化解析解解决了GRPO中的训练不稳定问题,并支持多样化的采样分布,具有较好的稳定性和表现。