开源复现DeepSeek R1的文本到图谱抽取训练open-r1-text2graph
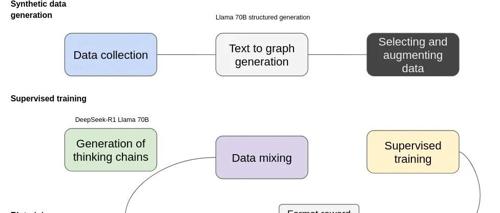
该项目基于Hugging Face Open-R1和trl构建,并重现了DeepSeek R1训练方案。通过合成数据生成、监督训练和强化学习(使用GRPO策略优化)等步骤,旨在提高模型进行文本到图信息提取的能力。
该项目基于Hugging Face Open-R1和trl构建,并重现了DeepSeek R1训练方案。通过合成数据生成、监督训练和强化学习(使用GRPO策略优化)等步骤,旨在提高模型进行文本到图信息提取的能力。

Unsloth AI 提供了 GRPO 训练算法,使用户能够在仅 7GB VRAM 上重现 DeepSeek R1-Zero 的‘顿悟时刻’,相比传统方法减少约80%的 VRAM 使用量。

DeepSeek R1 模型利用 GRPO 算法实现自主学习能力,仅需 7GB 显存即可训练出具备推理能力的模型,大幅降低训练门槛和成本。

DeepSeek R1-Zero无需人类标注即可实现准确推理,通过强化学习自主发展自我验证和搜索能力。TinyZero展示了其在CountDown游戏中的复现成果,成本不到30美元。
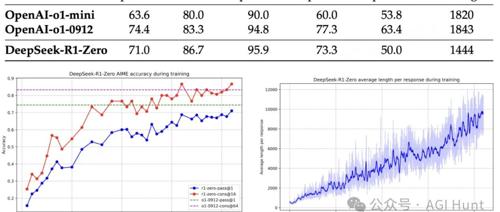
DeepSeek AI 推出 DeepSeek-R1 模型,引入群体相对策略优化(GRPO)和多阶段训练方法。通过强化学习提升大语言模型推理能力,并在监督微调和拒绝采样后形成最终模型。