QwenLong-L1:迈向具备长上下文推理能力的大型语言模型的强化学习方法 2025年5月28日8时 作者 NLP工程化 本文提出了一种强化学习框架QwenLong-L1,旨在提升大语言模型在长上下文中的泛化能力,并通过逐步扩展上下文长度、混合奖励函数等方法实现这一目标。
OpenAI没做到,DeepSeek搞定了!开源引爆推理革命 2025年5月24日16时 作者 新智元 名噪一时。而强化学习算法GRPO,是背后最大的功臣之一。然而,开源界对强化学习算法的探索并没有终结。
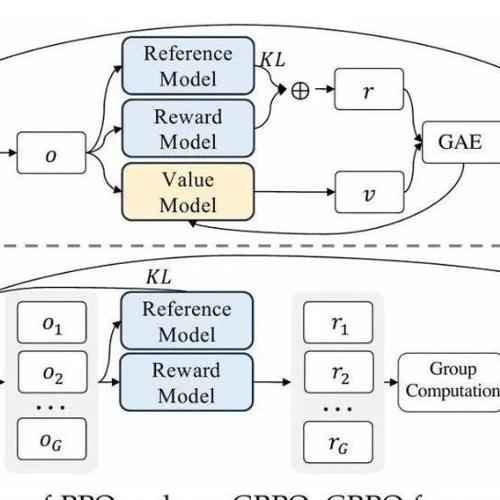
强化学习算法梳理:从 PPO 到 GRPO 再到 DAPO 2025年5月5日14时 作者 机器学习算法与自然语言处理 业研究人员。 社区的愿景 是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进