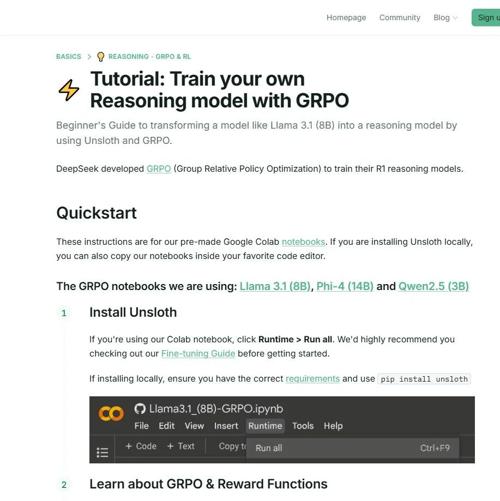
万亿参数模型Kimi-K2部署、微调需要多大配置及4个代表性的大模型训练框架

今天是2025年7月12日,星期六,北京有雨。文章介绍了四个代表性大模型训练框架,并使用资源计算器分析了最新万亿参数模型Kimi-K2的运行和微调需求。
今天是2025年7月12日,星期六,北京有雨。文章介绍了四个代表性大模型训练框架,并使用资源计算器分析了最新万亿参数模型Kimi-K2的运行和微调需求。

Unsloth在文档中提到DeepSeek-V3-0526模型,但随后删除。该模型性能强劲,被描述为世界上表现最好的开源模型之一。Daniel Han认为V3-0526可能基于传言和推测发布。社区对此表示关注和期待。
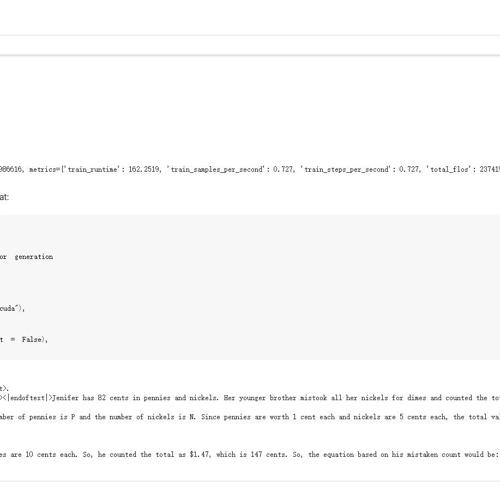
Unsloth 发布了GRPO的新互动教程,用户可以轻松微调Qwen3-Base并开启其思考模式,实现几乎无监督学习。

Unsloth发布Dynamic v2.0量化版本,在MMLU和KL Divergence上表现更好,并修复了Llama.cpp中的问题,同时推出了新量化版本DeepSeek-R1/DeepSeek-V3-0324。

对LLM进行微调可以定制其行为、增强知识并优化特定任务表现。通过在专业数据集上微调预训练模型(如Llama-3.1-8B),更新领域知识,调整语气和个性化回复,提高准确性和相关性。

enManus-RL增强Agent规划能力训练框架》,https://mp.weixin.qq.co
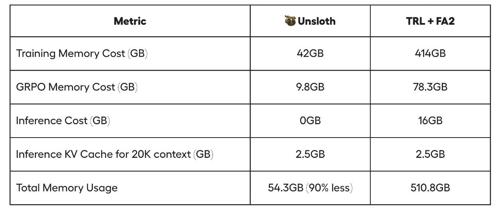
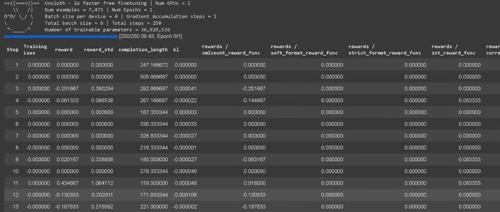
近日,Unsloth 团队升级了微调框架,使得使用其Qwen2.5-1.5B模型仅需5GB显存,相比之前减少了约29%。新的Efficient GRPO算法通过优化内存使用效率,使VRAM需求降至原本的54.3GB。