
推荐系统不再瞎猜!IEDR首创多情境对比解耦学习,精准拆解用户偏好动因

在推荐系统中,本文提出了一种名为 Intrinsic-Extrinsic Disentangled Recommendation (IEDR) 的通用框架,能够在多种复杂交互情境下区分用户内在偏好与外在动机。
在推荐系统中,本文提出了一种名为 Intrinsic-Extrinsic Disentangled Recommendation (IEDR) 的通用框架,能够在多种复杂交互情境下区分用户内在偏好与外在动机。
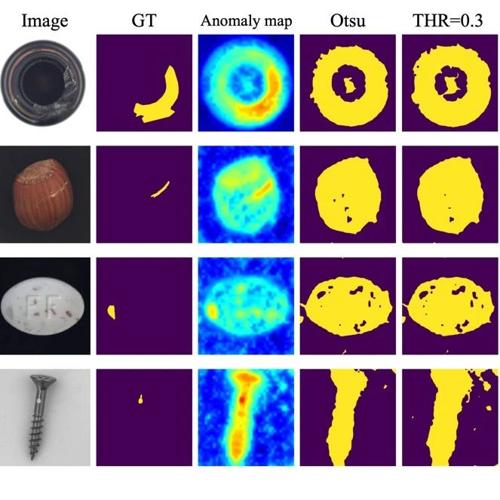
华科&精测提出AnomalyNCD,采用自监督学习和掩膜引导策略实现工业缺陷多类别自主分类,性能优于现有方法,具备数据集开放能力。

华中科技大学联合金山办公推出文档解析模型MonkeyOCR,在处理包含公式和表格的复杂文档时表现出色,提升了15.0%和8.6%的性能。

华中科技大学开发的MonkeyOCR文档解析模型在OmniDocBench数据集上取得显著成果,相比MinerU、Qwen2.5-VL等开源和闭源大模型,在中文内容识别方面表现出色。该模型采用结构-识别-关系(SRR)三元组方法,并基于大规模标注数据集MonkeyDoc进行训练。
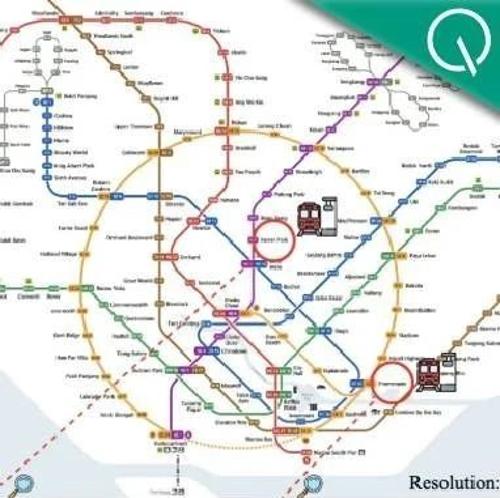
近年来多模态大模型在理解和复杂推理任务中取得进展,但其对高分辨率图像(如地铁图)的理解能力仍存争议。为此,西湖大学、新加坡国立大学等团队提出ReasonMap评测基准,聚焦于高分辨率交通图的多模态推理,发现当前开源模型存在性能瓶颈,并指出强化学习后训练模型在某些维度上优于现有模型。

本文提出了一种新的端到端自动驾驶框架ORION,通过引入QT-Former聚合历史场景信息、VLM进行场景理解与指令生成以及生成模型对齐推理空间和动作空间,实现在闭环评测数据集Bench2Drive上的优异性能。
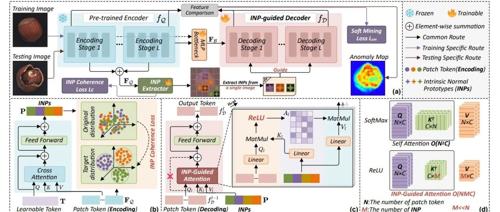
清华大学和华中科技大学的研究团队提出了一种新型异常检测方法INP-Former,通过从单张测试图像中动态提取内在正常原型(INPs),并利用这些INPs指导图像重建,实现了卓越的性能和强大的泛化能力。
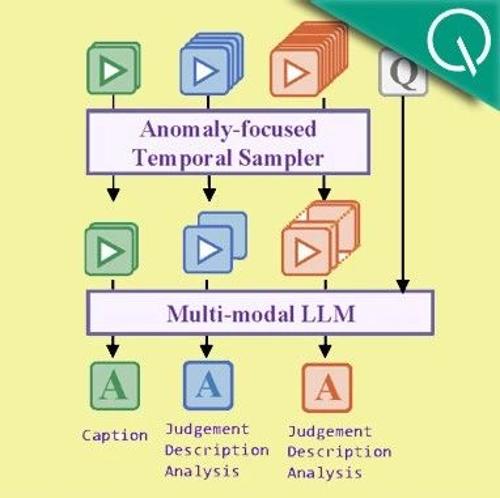
华中科大等机构提出Holmes-VAU模型及HIVAU-70k数据集,显著提升视频异常理解能力。该模型在长视频中采用动态稀疏采样策略,结合多层级指令数据实现准确的异常检测和分析。

可灵视频生成产品接入R1后,通过调用AI助手设计提示词,即使输入单个字也能精准生成相关视频。DeepSeek帮助设计的提示词不仅扩充细节,还能将复杂抽象的内容具体化。新成果ReCamMaster则是镜头可控的生成式视频再渲染框架,支持多种镜头操作重现复杂场景。
