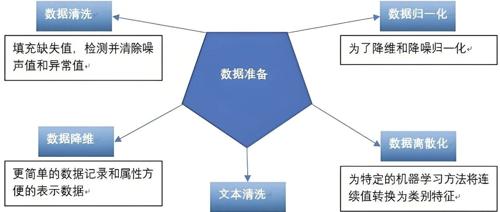
公开数据集
刚刚,小米又开源一大模型,22个公开测评SOTA

小米公司正式开源声音理解大模型MiDashengLM-7B,其在22个公开评测集上刷新多模态大模型最好成绩,并在推理效率和数据利用率方面表现突出。该模型基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B作为自回归解码器训练而成。
MonkeyOCR:华科开源高效文档解析模型,精度超越闭源大模型、速度还更快!

华中科技大学开发的MonkeyOCR文档解析模型在OmniDocBench数据集上取得显著成果,相比MinerU、Qwen2.5-VL等开源和闭源大模型,在中文内容识别方面表现出色。该模型采用结构-识别-关系(SRR)三元组方法,并基于大规模标注数据集MonkeyDoc进行训练。