狂揽2.6k stars,MonkeyOCR-3B在英文文档解析任务上超越72B模型,性能达SOTA

华中科技大学联合金山办公推出文档解析模型MonkeyOCR,在处理包含公式和表格的复杂文档时表现出色,提升了15.0%和8.6%的性能。
华中科技大学联合金山办公推出文档解析模型MonkeyOCR,在处理包含公式和表格的复杂文档时表现出色,提升了15.0%和8.6%的性能。

华中科技大学开发的MonkeyOCR文档解析模型在OmniDocBench数据集上取得显著成果,相比MinerU、Qwen2.5-VL等开源和闭源大模型,在中文内容识别方面表现出色。该模型采用结构-识别-关系(SRR)三元组方法,并基于大规模标注数据集MonkeyDoc进行训练。
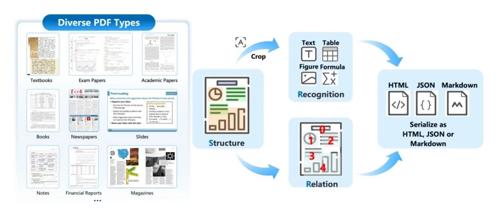
文章介绍了一种名为MonkeyOCR的新文档解析模型,采用Structure-Recognition-Relation (SRR)三元组范式分解文档解析任务为结构检测、内容识别和关系预测三个阶段。该模型在多个文档类型上表现出色,支持多语言和多种格式的文档处理,并且提供了高效的部署方案。
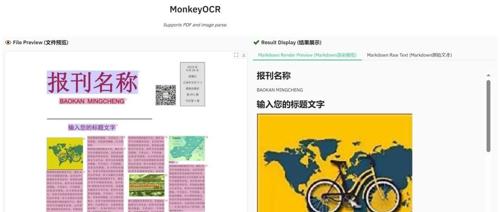
MonkeyOCR采用结构-识别-关系(SRR)范式提升文档解析性能,相比MinerU和端到端模型,在九种文档上的表现均有提升。它支持快速开始安装、推理等步骤,并提供了多种示例文档展示效果。