
95后北大校友挑起ChatGPT Agent大梁!今年刚博士毕业,曾获陶哲轩支持的AIMO第二名

OpenAI发布会C位被华人占据,孙之庆、马丁(MengTian)李和张熙堃等华人员工参与重要项目。小扎挖角多名OpenAI研究员后引起关注,首席研究官Mark Chen离职加入Meta,Alexandr Wang成为全球最年轻的亿万富豪之一。
OpenAI发布会C位被华人占据,孙之庆、马丁(MengTian)李和张熙堃等华人员工参与重要项目。小扎挖角多名OpenAI研究员后引起关注,首席研究官Mark Chen离职加入Meta,Alexandr Wang成为全球最年轻的亿万富豪之一。
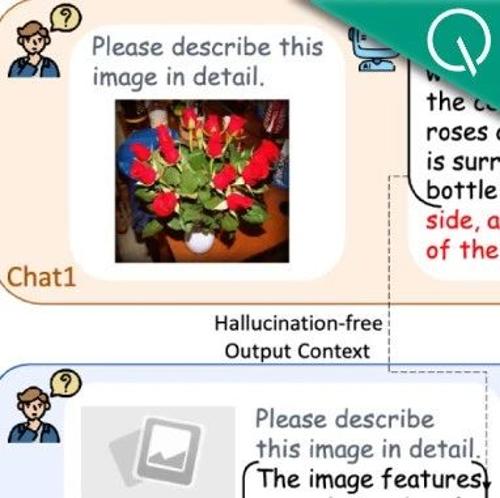
通过识别并增强视觉敏感的注意力头,中科院自动化所联合新加坡国立大学、东南大学提出了一种高效解决大模型幻觉问题的新方法VHR。该技术量化注意力头对视觉信息的敏感度,并动态强化这些视觉感知头,显著降低模型基于语言先验而产生的幻觉现象。

大语言模型驱动的多智能体系统在构建时面临手动设计和调试的瓶颈。新加坡国立大学等团队推出MaAS框架,利用智能体超网技术实现按需定制的动态智能体服务,提高效率并降低成本。

新晋图灵奖得主Richard Sutton预测大模型主导是暂时的,未来五年甚至十年内AI和强化学习将转向通过Agent与世界的第一人称交互获取‘体验数据’的学习。他强调AI需要新的数据来源,并且要随着增强而改进。他认为真正的突破还是来自规模计算。
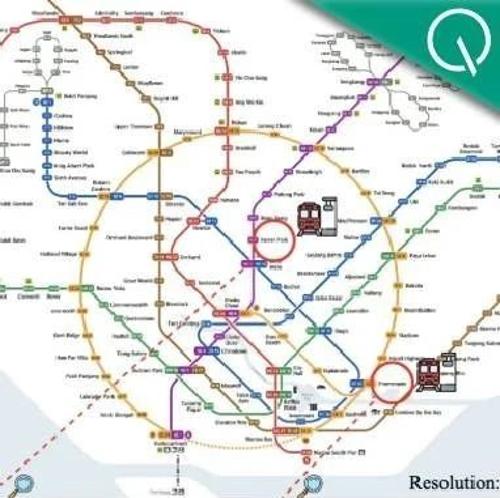
近年来多模态大模型在理解和复杂推理任务中取得进展,但其对高分辨率图像(如地铁图)的理解能力仍存争议。为此,西湖大学、新加坡国立大学等团队提出ReasonMap评测基准,聚焦于高分辨率交通图的多模态推理,发现当前开源模型存在性能瓶颈,并指出强化学习后训练模型在某些维度上优于现有模型。

新加坡国立大学发布OmniConsistency,利用大规模扩散Transformer实现图像风格化的一致性插件,显著提升视觉连贯性和美学质量,填补开源与商业模型在风格一致性上的性能差距。

本文提出了一种全新的隐式知识提取攻击IKEA方法,通过自然、常规查询引导RAG系统暴露其内部知识库中的私有信息,实验证明其具有高效率和成功率。

研究人员提出TokenShuffle方法显著减少多模态大语言模型中的视觉token数量,提高效率并促进高质量图像生成,超越同类自回归和强扩散模型。

本文首次系统性地研究并提出了高效建模长上下文视频生成的方法,通过重构视频生成任务为逐帧预测,并引入长短时上下文的非对称patchify策略和多层KV Cache机制,实现了高效的长视频训练与长上下文视频生成。
