


作者:昭昭
编辑:李宝珠,yudi
转载请联系本公众号获得授权,并标明来源
MonkeyOCR 在处理复杂文档(如包含公式和表格的文档)时表现出色,在公式和表格解析任务上的表现分别提升 15.0% 和 8.6%。
如今,OCR(光学字符识别)技术早已不再局限于文字识别,而正逐步演化为更复杂的文档解析系统。从最初的简单字符提取,到近年来兴起的多模态大模型,OCR 已融入了版面理解、语义识别与结构还原等任务,在文档识别、字幕识别、物流分拣、文献资料检索等领域广泛落地,而丰富的应用场景之下也对模型提出了更加严苛的要求。
例如,传统 OCR 模型大多采用模块化设计,需要将文档解析工作分解为多个细粒度子任务,效率低下且难以统一优化;端到端大模型虽强,但对资源要求极高,难以普适化落地;由文本、表格、数学表达式、嵌入式图形等多元素所构成复杂文档仍是准确率的「硬伤」……
针对于此,华中科技大学联合金山办公推出了一款名为 MonkeyOCR 的文档解析模型,能够高效地将非结构化文档内容转换为结构化信息。在 SRR 范式下,文档解析被抽象为 3 个基本问题:在哪里(structure)?是什么(recognition)?如何组织(relation)?分别对应版面分析、内容识别和逻辑排序。这种明确的任务分解在精度与速度之间实现了平衡,支持高效且可扩展的处理能力,同时保证精度不打折。
为了给模型提供足够的数据支持,研究团队构建了一个名为 MonkeyDoc 的数据集,这是迄今为止最全面的文档解析数据集,包含 390 万个实例,涵盖多种文档类型(如笔记、PPT、杂志、试卷等),同时还详细标注了各种结构分块(表格、图像、文本、公式等)。
根据研究团队的实验结果,MonkeyOCR 在处理复杂文档(如包含公式和表格的文档)时表现出色,在公式和表格解析任务上的表现分别提升 15.0% 和 8.6%。在多页文档处理速度上也远超其他模型,达到每秒 0.84 页。
值得一提的是,在英文文档解析任务上,其 3B 参数模型超越了主流 72B 模型,平均性能达 SOTA 级别。如今,MonkeyOCR 发布仍不足 1 个月,其 GitHub stars 数量已达 2.6k。
「MonkeyOCR:基于结构-识别-关系三元组范式的文档解析」已上线至 HyperAI超神经官网(hyper.ai)的「教程」板块,快来体验吧 ⬇️
教程链接:
https://go.hyper.ai/Llixk
Demo 运行
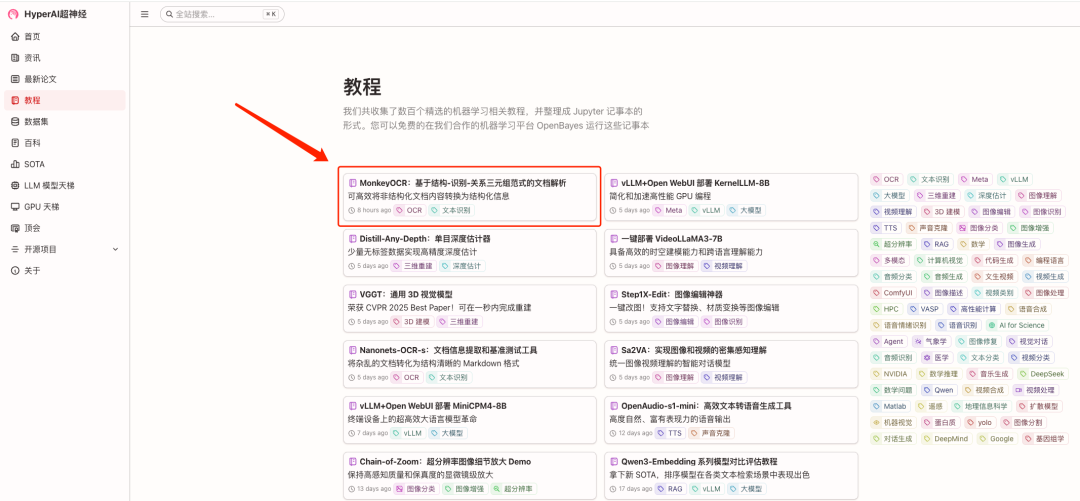
1.进入 hyper.ai 首页后,选择「教程」页面,并选择「MonkeyOCR:基于结构-识别-关系三元组范式的文档解析」,点击「在线运行此教程」。
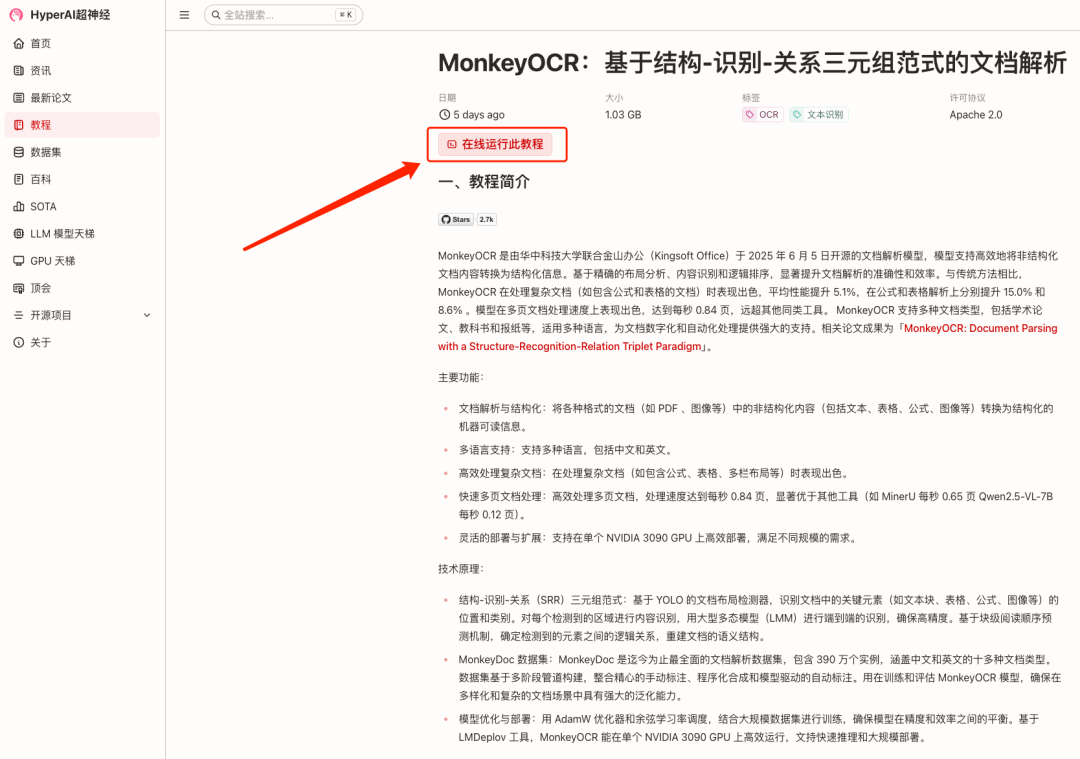
2.页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
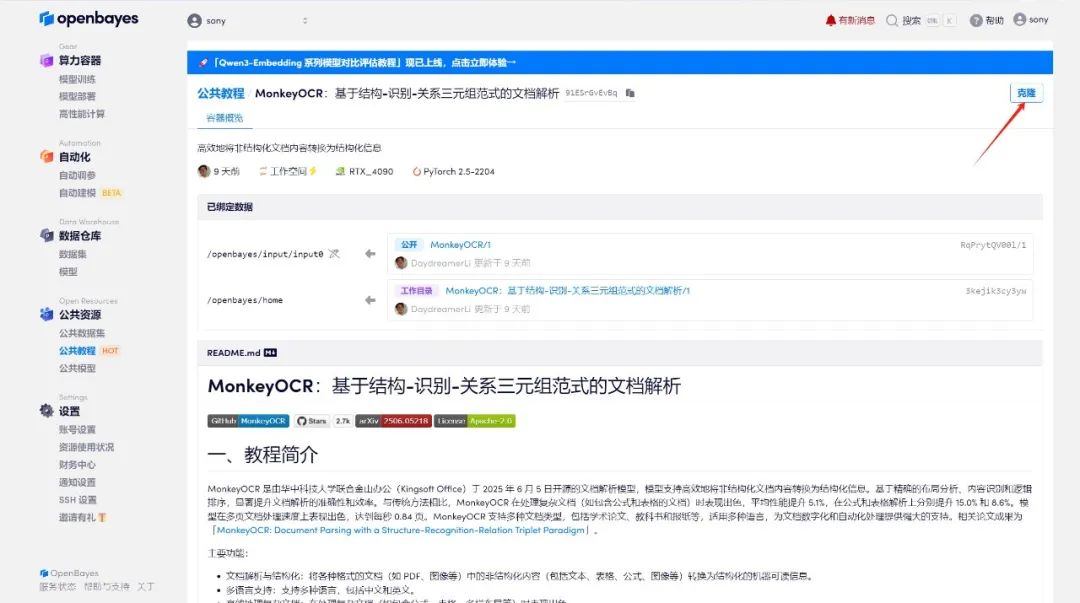
3.选择「NVIDIA GeForce RTX 4090」以及「PyTorch」镜像,OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
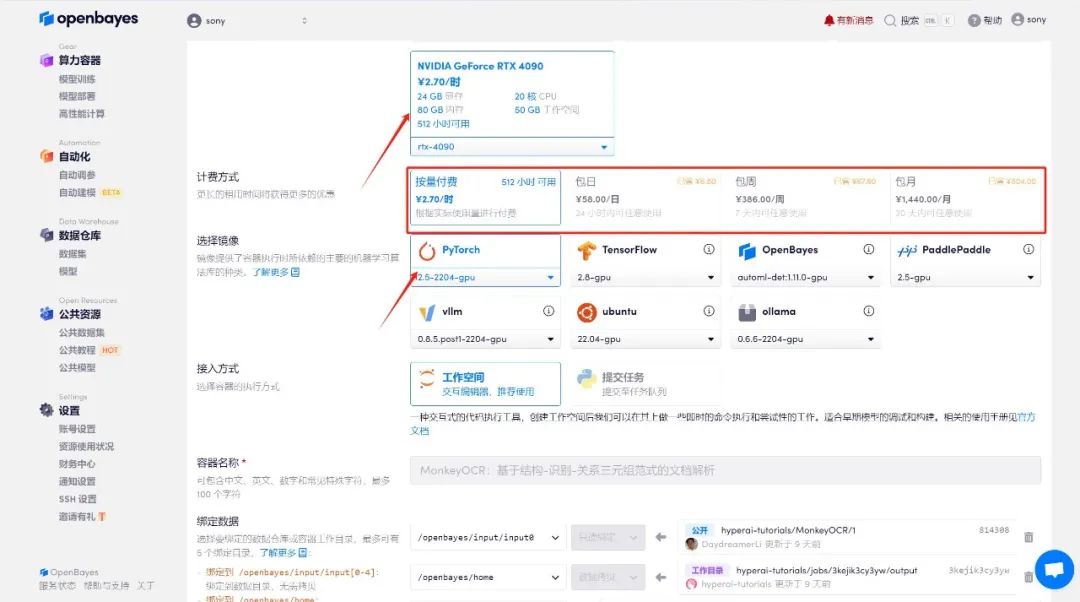
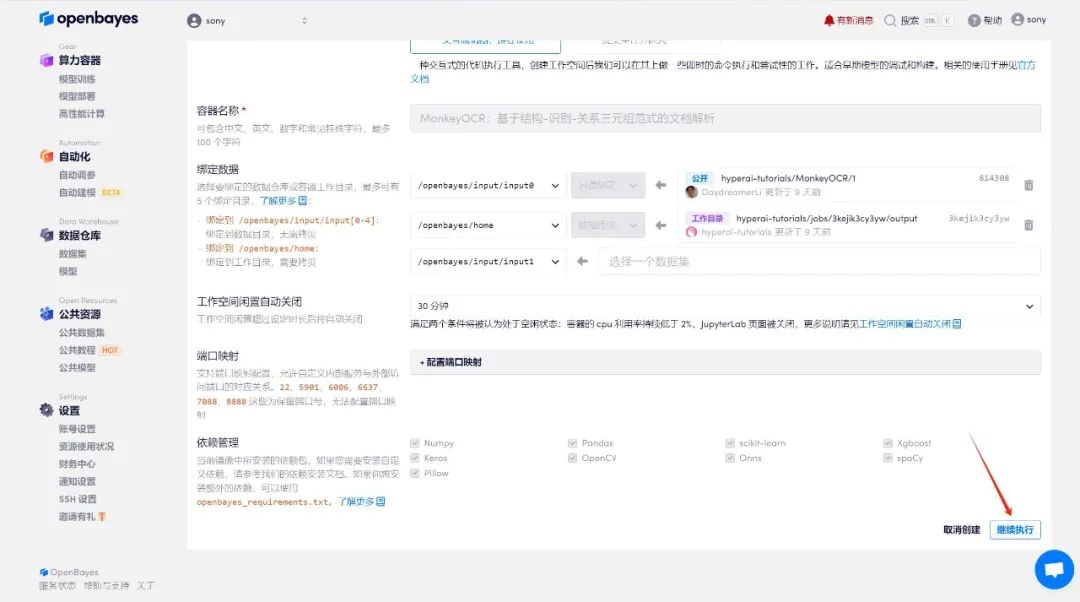
4.等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。
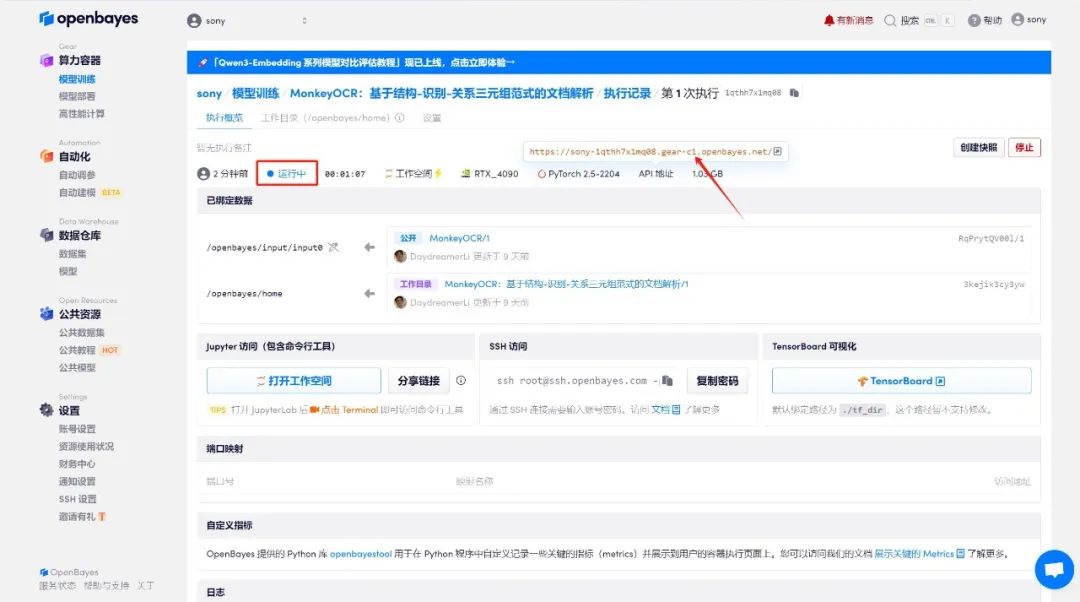
效果演示
上传 PDF 或图片,点击「Parse」解析。如果选择「Chat」模式,则需要在「Select Prompt」中选择 Prompt。
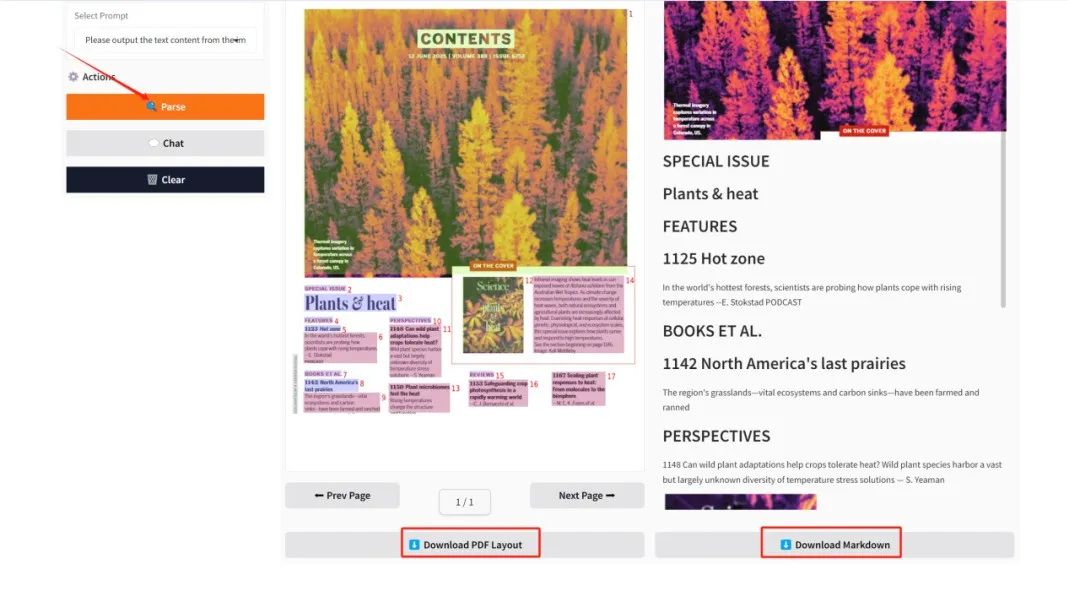
输出结果会显示在「Result Display」中,点击「Download PDF Layout/Download Markdown」即可将 PDF/Markdown 格式文档下载到本地。

以上便是本期推荐的教程了,欢迎大家体验 ⬇️
教程链接:
https://go.hyper.ai/Llixk



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)