


CVPR’25|一步推理高质量图像!用于蒸馏单步文生图扩散模型的时间无关统一编码器架构

本文提出时间无关统一编码器Loopfree,通过1步Encoder和4步Decoder实现单步推理的多步生成性能。克服了扩散模型所需几十步推理的问题,提高效率的同时保持高质量结果。

华为开源7180亿参数大模型!
华为近日宣布CANN全面开源开放,并发布了三款大型预训练语言模型。其中718亿参数规模的盘古Ultra MoE模型首次公开发布。华为还开源了包括1B、7B和718B大小的模型,提升其AI生态系统的发展。
ICCV 2025 打造首个多模态视觉匹配数据集与评测基准,填补MLLM多模态视频匹配能力评测的空白

推出首个多模态视觉匹配基准 MMVMBench,系统揭示现有大模型在“识别同一个物体”任务中的能力短

尝试终结Attention Sink起因的讨论
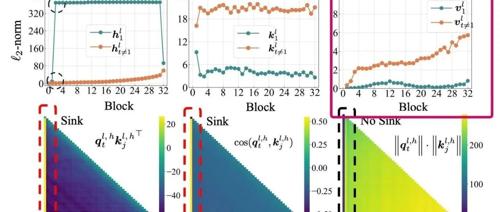
文章提出Transformer中的Attention Sink现象源于模型需要Context Aware的Identity Layer,即注意力块需在某些情况下保持恒等变换。该假设通过首个token的value接近0、深层解码更明显、非归一化注意力和门控机制消除sink等多个实验证据支持,并解释了这一现象的原因。