



TL;DR
我们提出了 STAG(Soft Tokenization for Text-attributed Graphs),一个创新的自监督框架,通过量化技术将图的结构信息直接转换为离散 token,实现图学习与大语言模型的无缝集成。该方法在多个节点分类基准上达到 SOTA 性能,支持真正的零样本迁移学习,无需任何标记数据!

论文标题:
Quantizing Text-attributed Graphs for Semantic-Structural Integration
论文链接:
https://arxiv.org/pdf/2507.19526
代码链接:
https://github.com/jybosg/STAG

引言
文本属性图(Text-attributed Graphs)在社交媒体网络分析,学术引用网络,知识图谱构建,电商推荐系统等领域广泛存在。这些图不仅包含丰富的拓扑结构信息,还蕴含大量文本语义信息,为深度理解复杂关系提供了独特机会。
随着 ChatGPT,GPT-4,LLaMA 等大语言模型的快速发展,GraphLLM 成为当前 AI 研究的前沿热点。如何让强大的 LLM 理解图结构,同时保持其卓越的语义理解能力,是实现真正“图-语言”智能的关键。
然而,现有方法仍面临根本性挑战:图的连续嵌入空间与 LLM 的离散 token 空间存在天然鸿沟,跨域迁移学习严重依赖昂贵的标记数据。

研究动机
当前方法存在显著局限:
-
对齐困难:传统方法需要昂贵的投影网络来对齐图嵌入与 LLM token 空间
-
手工设计:依赖人工设计的子图描述技术(如“节点 A 连接到 B 和 C”),难以扩展且不稳定
-
标签依赖:现有跨域方法需要源域标记数据,成本高昂且限制适应性
-
架构绑定:方法通常绑定特定 LLM 架构,缺乏灵活性

创新方法
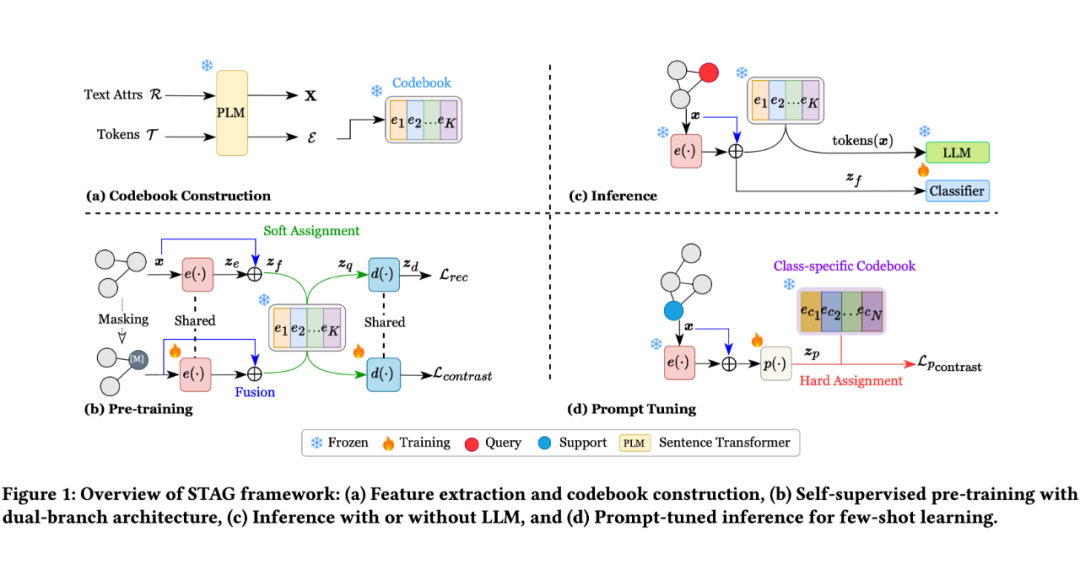
STAG 框架包含三个核心创新:
4.1 语义-结构融合模块
我们设计了参数高效的特征融合机制,巧妙整合 GNN 学习的结构表示与原始文本的语义表示:
-
双路径设计:分别处理结构信息(通过 GAT 编码器)和语义信息 (通过冻结的sentence transformer)
-
归一化融合:L2 归一化保持特征方向信息,避免不同模态特征的尺度差异
-
自适应权重:可学习参数 和 动态平衡结构与语义的贡献度
-
语义对齐:KL 散度损失确保融合后的表示保持与原始文本的语义一致性
核心公式-语义结构融合损失(Semantic-Structural Fusion):
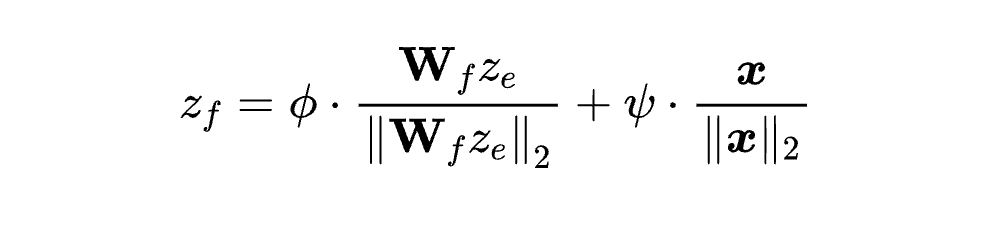
公式解析:
-
:GNN 编码器学习的结构表示(structural embedding)
-
:可学习的投影矩阵,将结构特征对齐到语义空间
-
:原始文本的语义表示(semantic embedding)
-
:可学习的融合权重,控制结构信息与语义信息的相对重要性
-
:L2 范数归一化,确保不同模态特征具有相同的尺度
技术突破:通过单位球面上的加权组合,既保持了特征的方向性语义,又避免了尺度不匹配问题。相比传统 concatenation,该方法参数量更少且数值更稳定。
4.2 软分配量化策略
针对图数据缺乏自然 token 化结构的挑战, 我们创新性地设计了软分配机制:
-
基于语义相似度:采用余弦相似度而非 L2 距离,更好地处理高维语义空间的相似性
-
概率分布映射:将每个节点映射到整个 codebook 的概率分布,而非单一token
-
温度控制:可调节温度参数 τ 控制分配的“软硬程度”,平衡表达能力与泛化性
-
防过拟合设计:软分配天然避免了对特定 token 的过度依赖,增强跨域迁移能力
核心公式-软分配注意力机制(Soft Assignment Attention):
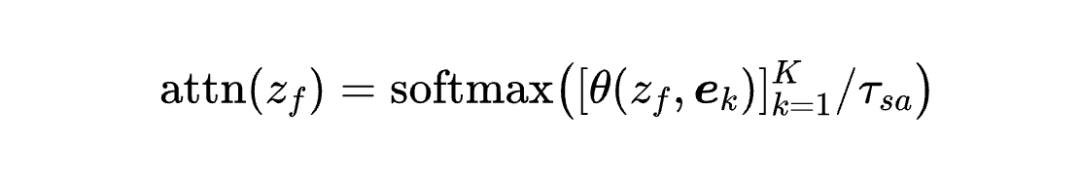
公式解析:
-
:融合后的节点表示 (来自上述语义-结构融合)
-
:第 个 codebook 向量,对应 LLaMA 词汇表中的 token 嵌入
-
:余弦相似度函数,计算表示向量与 codebook 的语义匹配度
-
:codebook 大小(15,062 个精选英文 token)
-
:软分配温度参数,控制注意力分布的“尖锐程度”
量化策略-加权组合(Weighted Combination):
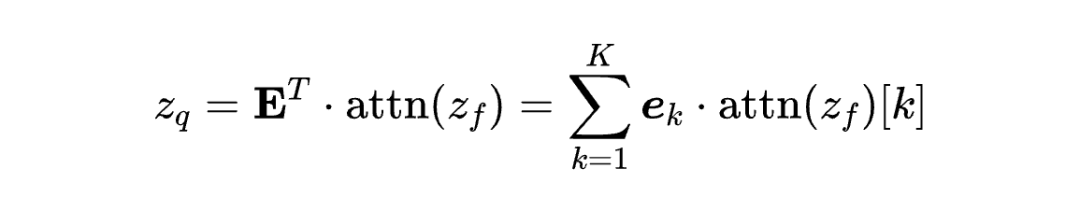
技术突破:相比 VQ-VAE 的硬分配(),我们的软分配策略特别适合处理图的不规则结构,同时保持了 token 空间的连续性和语义一致性。
4.3 双分支训练目标
STAG 采用双分支架构同时优化语义保持和结构感知两个目标:
-
重构分支:保持节点级语义信息,确保量化过程不损失文本语义
-
对比分支: 捕获邻域结构模式,利用图掩码策略学习拓扑关系
-
冻结 codebook 设计:确保跨 LLM 语义一致性,避免 codebook 漂移
重构损失-缩放余弦误差(Scaled Cosine Error, SCE):
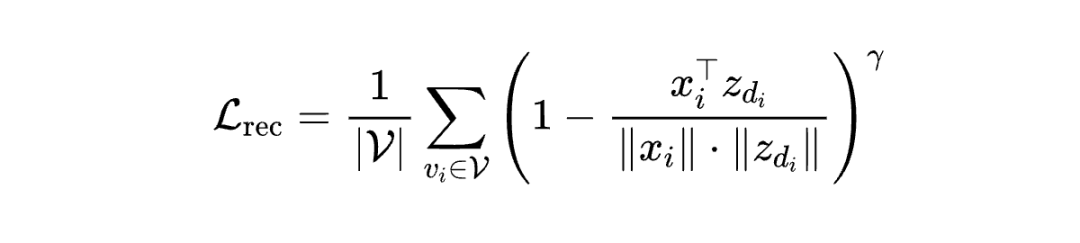
公式解析:
-
:节点 的原始语义特征
-
:经过量化-解码后的重构特征
-
:缩放因子,控制重构误差的惩罚强度
-
设计优势:相比 MSE 损失,SCE 避免了梯度消失问题,对语义特征更敏感
对比损失-InfoNCE(Contrastive Learning):
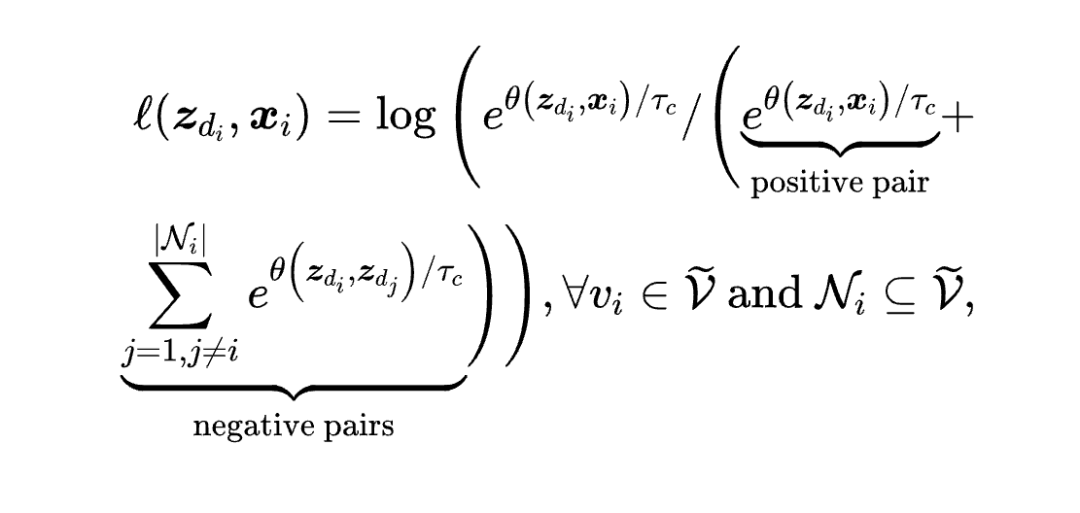
公式解析:
-
:掩码节点 的解码表示
-
:节点 的原始特征(正样本)
-
:负样本集合(其他掩码节点)
-
:对比学习温度参数
-
核心思想:通过邻域结构预测掩码节点,迫使模型学习图的拓扑模式
联合优化目标:
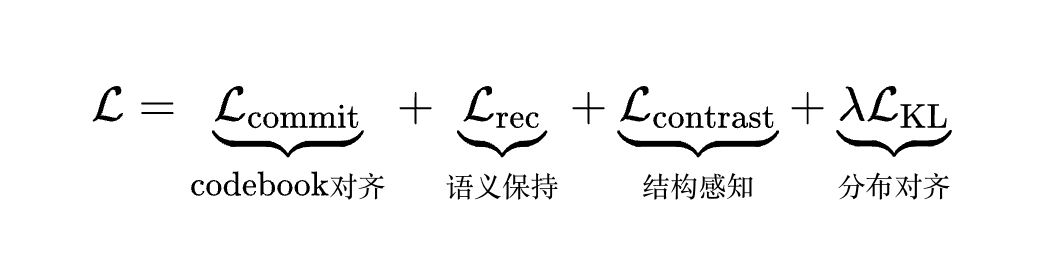
4.4 灵活推理机制
STAG 的一大优势是支持多种推理策略,可根据具体需求和资源约束灵活选择:
4.4.1 LLM 推理路径
将量化后的结构-语义信息直接转换为 LLM 可理解的 token 序列:
Step 1:Token 选择策略
-
计算融合表示 与 codebook 的注意力分布
-
选择 top-k 个最高权重的 token:
-
通常设置 – 平衡信息量与推理效率
Step 2:Prompt 构建
-
Few-shot 示例:“节点 tokens:[research,methodology,experiment] → 类别:Research Paper”
-
Zero-shot 查询:“节点 tokens:[algorithm,computation,optimization] → 预测类别:?”
-
系统提示:明确分类任务和候选类别列表

Step 3:LLM 分类
-
利用 LLM 的语义理解能力进行上下文学习
-
支持多种 LLM 架构:LLaMA2/3,Vicuna,GPT-4o 等
-
无需额外训练,即插即用
4.4.2 传统推理路径
直接使用学习到的连续表示进行分类,更高效且无需 LLM:
线性探测(Linear Probing):
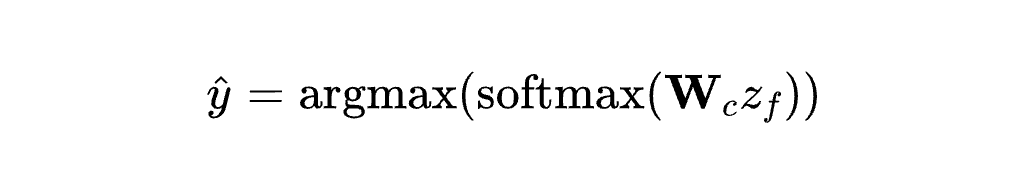
-
:可训练的分类器权重
-
:冻结的融合表示 (来自预训练模型)
-
仅训练分类器,保持表示学习的通用性
4.4.3 提示调优增强
轻量级适应机制,专门针对 few-shot 场景优化:
核心思想:引入小型 prompt 网络 微调融合表示
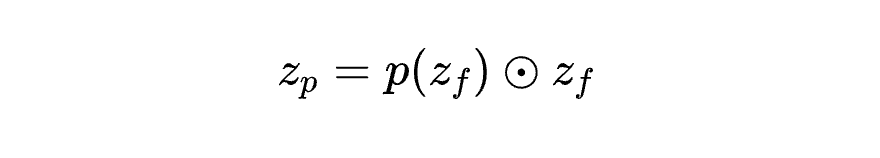
双重优化目标:
-
Commitment Loss:
-
Weighted Contrastive:利用类别语义相似度引导学习
推理方式:
-
有 LLM: → 量化 → tokens → LLM分类
-
无 LLM: → 类别相似度 → 直接预测
4.4.4 推理策略对比
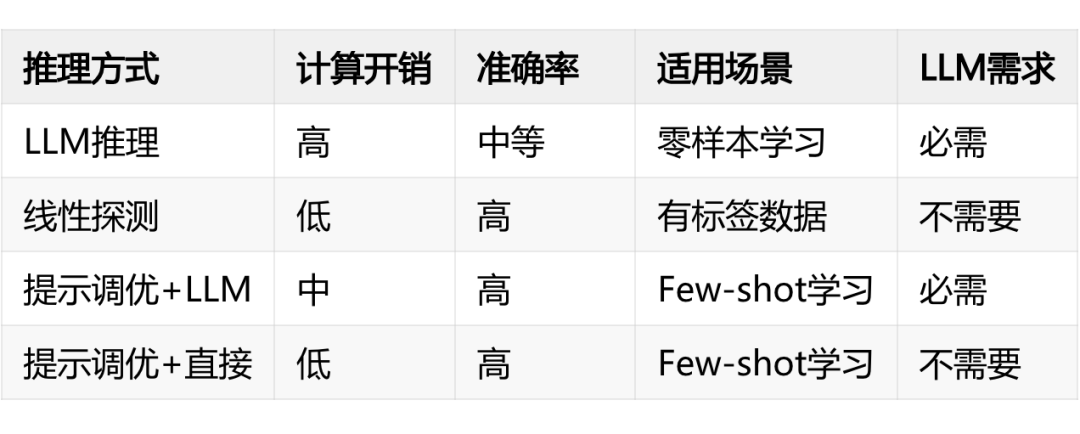
灵活性优势:
-
即时切换:同一预训练模型支持所有推理方式
-
渐进式部署:从零样本→few-shot→fully-supervised逐步优化
-
资源适配:根据计算资源选择最合适的推理策略

卓越性能
在 7 个文本属性图数据集上的全面评估显示:
5.1 Few-shot 学习(5-way 5-shot)
我们在多个具有挑战性的数据集上进行了广泛评估:
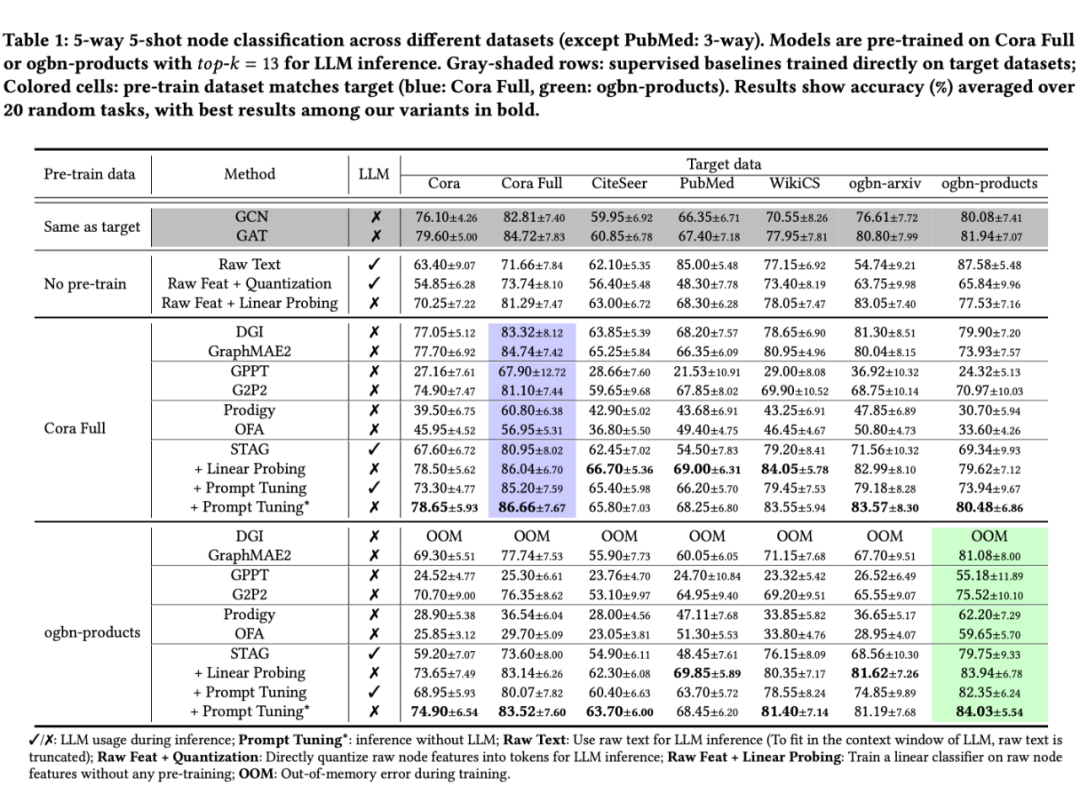
关键优势:
-
STAG+Prompt Tuning 在所有跨域任务中均显著优于需要源域标签的方法
-
即使在同域评估中也保持与最强 GraphMAE2 基线的竞争优势
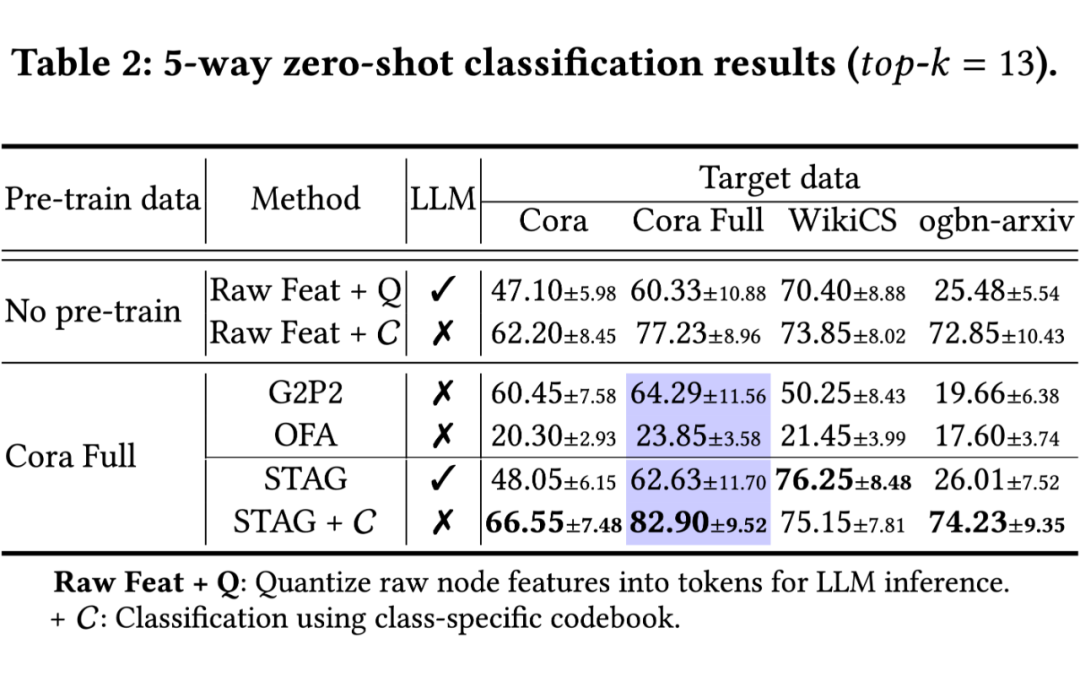
5.2 Zero-shot 学习
-
无需任何标记数据实现强性能
-
大幅超越需要源域标签的基线方法
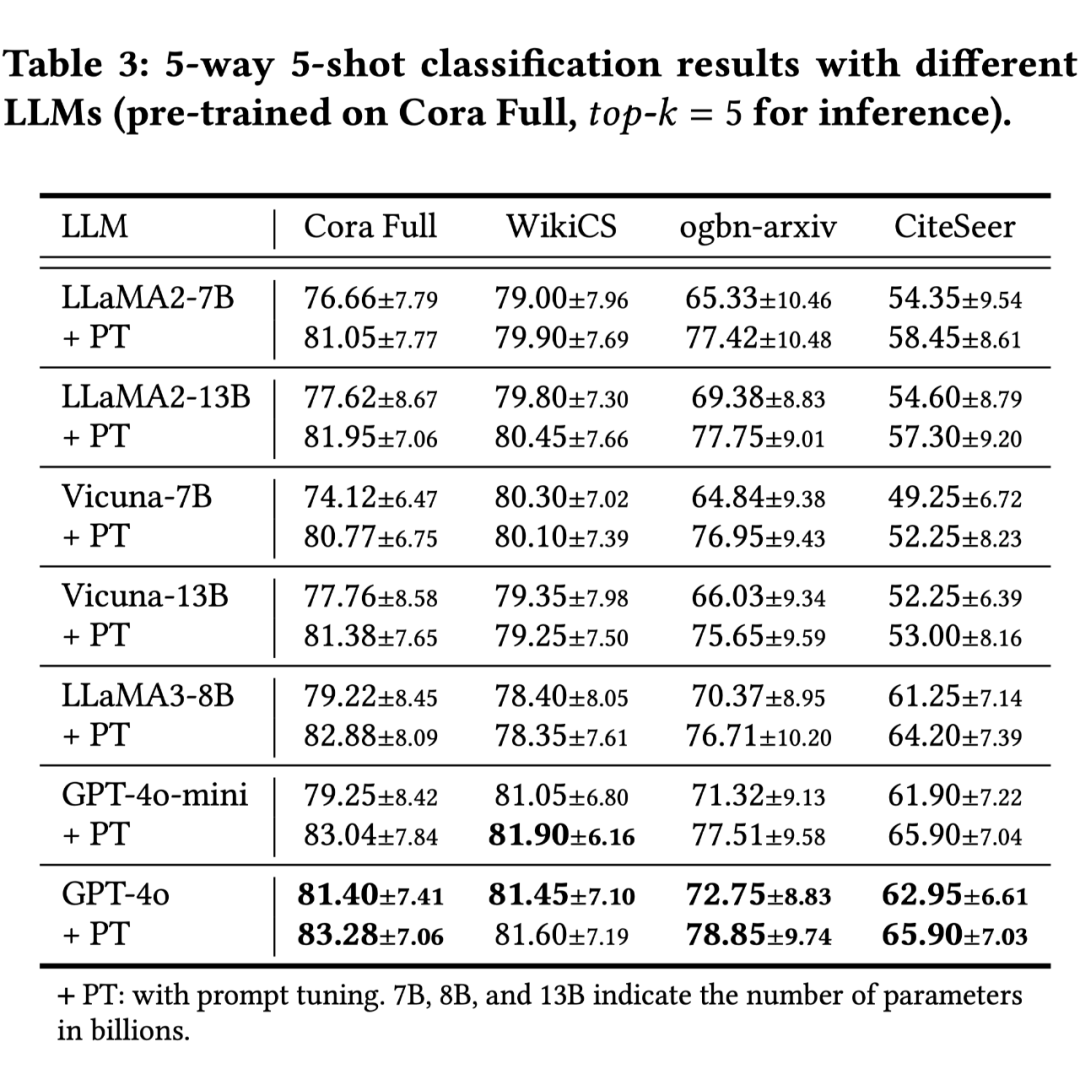
5.3 LLM 兼容性
-
支持 LLaMA2/3, Vicuna, GPT-4o 等多种架构
-
性能随模型规模一致提升
-
提示调优带来稳定性能增益
5.4 任务泛化能力
-
链路预测:在 ogbn-products 上达到 96.85%
-
边分类:FB15K237 上达到 74.80%
-
子图分类:多数据集均有提升

总结与展望
STAG 开创性地解决了图学习与大语言模型融合的核心难题:
✅ 首次实现图结构信息到离散 token 空间的直接映射
✅ 首次在跨域学习中实现真正的零样本迁移(无需源域标签)
✅ 首次提供统一框架支持有/无 LLM 的多种学习范式
✅ 首次展示跨 LLM 架构的一致性能表现
未来工作将扩展到图级任务和链式推理,进一步推动图学习与 LLM 的深度融合!
(文:PaperWeekly)