
ICML2025|多模态理解与生成最新进展:港科联合SnapResearch发布ThinkDiff,为扩散模型装上大脑

多模态理解与生成新方法ThinkDiff在ICML2025上提出,仅需少量数据和计算资源,让扩散模型具备推理能力,并通过视觉-语言训练和掩码策略传递VLM的多模态推理能力,大幅提高图像生成质量。
多模态理解与生成新方法ThinkDiff在ICML2025上提出,仅需少量数据和计算资源,让扩散模型具备推理能力,并通过视觉-语言训练和掩码策略传递VLM的多模态推理能力,大幅提高图像生成质量。

香港科技大学联合Snap Research提出ThinkDiff方法,仅需少量图文对和数小时训练让扩散模型具备多模态推理与生成能力。
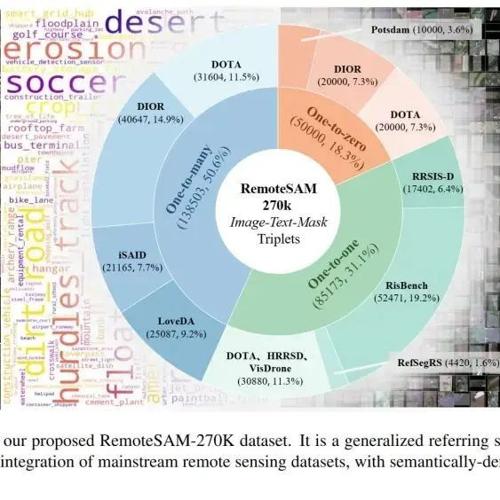
提出了一种轻量级的遥感视觉模型RemoteSAM,通过大规模数据集RemoteSAM-270K和统一架构实现了多种视觉任务。显著提升了效率和性能。

专注AIGC领域的专业社区介绍SpatialLM模型,该模型通过结合点云数据的特征提取、对齐和语言生成,实现了高效的空间三维场景理解与生成。

香港科技大学推出MATP-BENCH基准测试集,评估多模态大模型在处理包含图像和文本的几何定理证明中的能力。实验发现尽管模型在将图文信息转化为形式化定理方面有一定能力,在构建完整证明时面临复杂逻辑推理和辅助线构造等重大挑战。

香港科技大学联合快手可灵团队提出EvoSearch方法,通过演化搜索提升视觉生成模型的性能。该方法无需训练参数,仅需计算资源即可在多个任务上取得显著最优效果,并且具有良好的扩展性和泛化性。
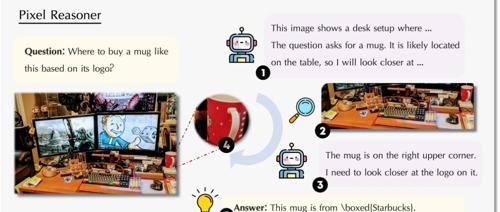
Pixel Reasoner 是一款基于像素空间推理增强的视觉语言模型,通过直接操作视觉输入提升对视觉细节的捕捉能力。它结合指令调优和好奇心驱动的强化学习,在多个视觉推理基准测试中表现出色。

港中文和微软联合团队推出OpenThinkIMG开源框架,旨在提升AI视觉工具使用和推理能力。该框架包含模块化视觉工具部署、高效的智能体训练框架及高质量数据生成技术,支持自主学习的V-ToolRL算法显著提升了AI在图表推理任务上的表现。

