
监督学习未死,一题训练五小时起飞!华人学者新方法20倍训练效率释放大模型推理能力

加拿大滑铁卢大学TIGER Lab华人学者团队提出One-Shot Critique Fine-Tuning (One-Shot CFT) 新方法,通过生成多个不同版本的解答和多个点评者模型进行点评,让目标模型从“批判答案”中学习推理规律。该方法在计算资源消耗、效果稳定性方面表现优异,比传统的监督式微调和强化学习有明显优势。
加拿大滑铁卢大学TIGER Lab华人学者团队提出One-Shot Critique Fine-Tuning (One-Shot CFT) 新方法,通过生成多个不同版本的解答和多个点评者模型进行点评,让目标模型从“批判答案”中学习推理规律。该方法在计算资源消耗、效果稳定性方面表现优异,比传统的监督式微调和强化学习有明显优势。
研究人员提出NeuralOS,通过循环神经网络和基于扩散的神经渲染器模拟Windows界面,成功实现了逼真、响应迅速的操作系统演示。
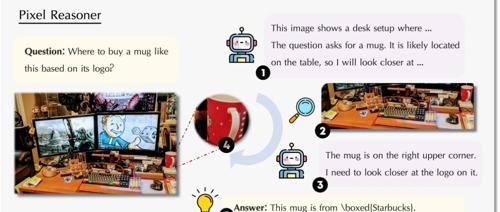
Pixel Reasoner 是一款基于像素空间推理增强的视觉语言模型,通过直接操作视觉输入提升对视觉细节的捕捉能力。它结合指令调优和好奇心驱动的强化学习,在多个视觉推理基准测试中表现出色。

研究团队提出VL-Rethinker模型,通过优势样本回放和强制反思技术解决多模态推理中的优势消失和反思惰性问题。该模型在多个数学和科学任务上超过GPT-o1,并显著提升Qwen2.5-VL-72B在MathVista和MathVerse上的性能。

Laser团队提出的新方法提升了大模型的推理效率与准确性,通过统一视角看待不同奖励设计、基于目标长度和阶跃函数的奖励机制以及动态且带有难度感知的目标调整,实现了在减少Tokens使用量的同时保持或提升准确率。

最近Meta与滑铁卢大学联合开发的MoCha模型在对话角色视频生成方面取得了重大突破,能够根据文本或语音输入生成带有同步语音和自然动作的完整角色动画。其创新的技术架构和训练策略使得角色的嘴型能够更加精准地匹配语音内容,增强了动画的真实感和自然度。
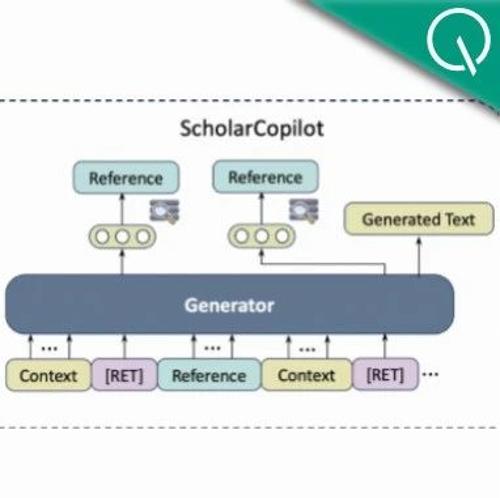
学术研究团队提出了一种名为 ScholarCopilot 的智能大模型框架,专门用于精准生成带有准确引用的学术文本。ScholarCopilot 采用动态机制,在生成过程中实时检索并插入文献引用,提高了引用准确性与相关性。

本文由加拿大滑铁卢大学魏聪、陈文虎教授团队与 Meta GenAI 共同完成,首次提出面向Talking Characters任务的视频生成方法MoCha,实现仅基于语音和文本输入生成完整角色对话视频。
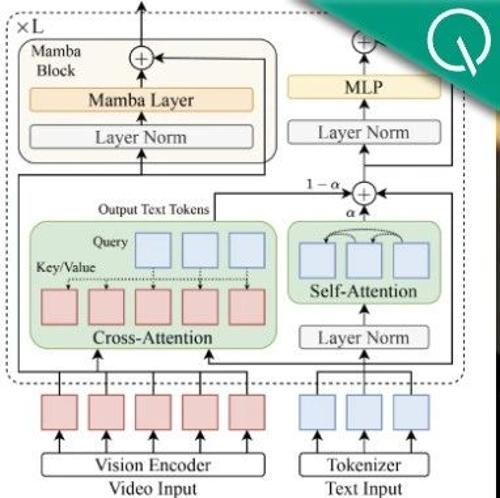
滑铁卢大学陈文虎团队提出Mamba-Transformer混合模型Vamba,通过改进模型架构设计提升视频理解效率。相比传统方法,Vamba在同等硬件条件下可处理的视频帧数提升4倍,内存消耗降低50%以上,并实现单步训练速度翻倍。

微软研究院团队提出Transformer递归式自我提升方法,可在不修改基础架构的情况下解决长度泛化问题。通过多数投票和长度过滤,在10位数以内的乘法上实现近乎完美表现。