
4K-Agent:可将低分辨率图像提升至4K高清智能体
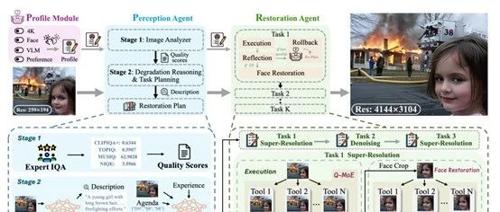
专注AIGC领域的专业社区介绍,强调图像超分辨率技术及多智能体系统4K Agent的研究与应用。它能够处理各种类型的退化图像,并通过高度可配置的模块进行灵活适应和优化。
专注AIGC领域的专业社区介绍,强调图像超分辨率技术及多智能体系统4K Agent的研究与应用。它能够处理各种类型的退化图像,并通过高度可配置的模块进行灵活适应和优化。
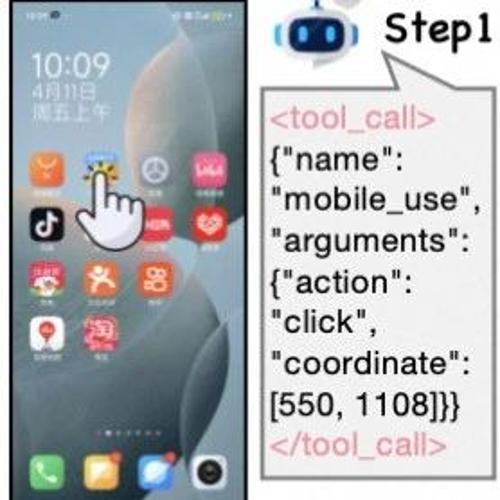
MLNLP社区介绍了采用多回合、任务导向的交互式强化学习框架Mobile-R1,旨在提高移动代理在复杂环境中的适应性和探索能力,并提出三阶段训练流程提升模型表现。团队通过高质量轨迹数据集进行格式微调、动作级和任务级训练,最终显著提升了模型在多种基准上的性能。

多模态理解与生成新方法ThinkDiff在ICML2025上提出,仅需少量数据和计算资源,让扩散模型具备推理能力,并通过视觉-语言训练和掩码策略传递VLM的多模态推理能力,大幅提高图像生成质量。
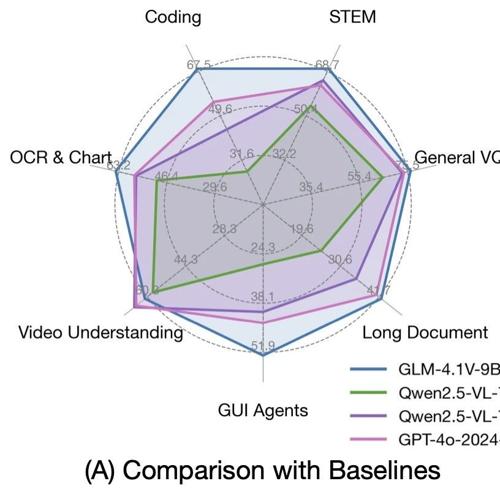
基于GLM-4.1V-9B-Thinking模型,引入强化学习技术提升视觉语言模型能力,在18个任务中与8倍参数量的Qwen-2.5-VL-72B相当或超越

基于强化学习训练的视觉语言模型成功在开放GUI环境中进行了自我探索,提升了智能体的交互能力。该研究展示了如何结合探索奖励、世界模型和GRPO强化学习来增强智能体的探索效率,并通过经验流蒸馏技术进一步提升了其自主性。

VRAG-RL 是一种基于强化学习的视觉检索增强生成方法,通过引入多模态智能体训练,实现了视觉语言模型在检索、推理和理解复杂视觉信息方面的显著提升。

香港中文大学与新加坡国立大学的研究者提出了一种名为TON的新颖选择性推理框架,让视觉语言模型可以自主判断是否需要显式推理。该方法显著减少了生成的思考链长度,提高了模型推理过程的效率,并且在不牺牲准确率的前提下提升了响应多样性。


