
ACM MM2025 Oral RemoteSAM:轻量统一的遥感视觉模型
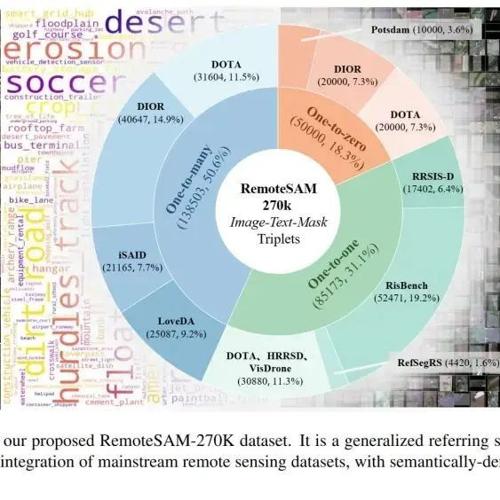
提出了一种轻量级的遥感视觉模型RemoteSAM,通过大规模数据集RemoteSAM-270K和统一架构实现了多种视觉任务。显著提升了效率和性能。
提出了一种轻量级的遥感视觉模型RemoteSAM,通过大规模数据集RemoteSAM-270K和统一架构实现了多种视觉任务。显著提升了效率和性能。
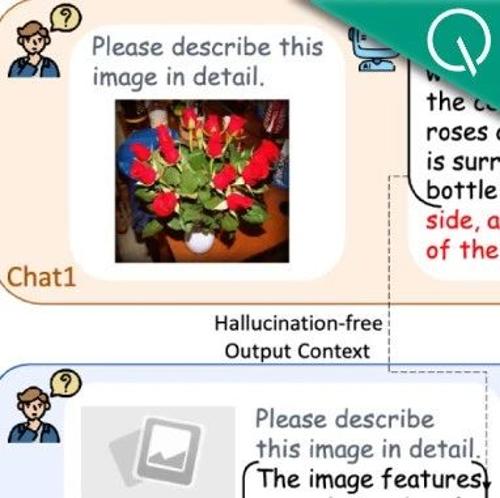
通过识别并增强视觉敏感的注意力头,中科院自动化所联合新加坡国立大学、东南大学提出了一种高效解决大模型幻觉问题的新方法VHR。该技术量化注意力头对视觉信息的敏感度,并动态强化这些视觉感知头,显著降低模型基于语言先验而产生的幻觉现象。

东南大学联合多所研究机构提出了KRIS-Bench,一个评估图像编辑模型知识结构的基准。该基准从事实性、概念性和程序性知识三个层面测试编辑能力,并包含1267对图像指令样本,覆盖初级到高级任务难度。

东南大学、香港中文大学和蚂蚁集团的研究团队提出了一种名为LMM-R1的两阶段多模态基于规则强化学习框架,显著提升了小型多模态大模型的数学推理能力。该框架在仅需240元GPU成本下训练出性能卓越且适用于工业级应用的多模态模型。

检索增强生成(RAG)在开放域问答任务中表现出色,但传统搜索引擎可能只进行横向网页搜索,限制了大型语言模型(LLM)对复杂信息的处理能力。为了解决这一问题,提出WebWalkerQA作为评估LLM执行网页遍历能力的新基准,并引入WebWalker多代理框架模拟人类网页导航过程。

NumPro通过为视频帧添加数字标识符的方式提升了视频大模型的时序定位能力。无需训练设置即可增强模型对事件发生时刻的理解,实验结果显示其显著优于现有方法,并且不影响模型通用视频理解能力。