
英伟达GPU被曝严重漏洞,致模型准确率暴跌99.9%

英伟达GPU被白帽黑客发现严重漏洞,通过Rowhammer攻击使大模型准确率直接降至0.02%,影响自动驾驶和医疗AI等应用。英伟达建议开启ECC防护措施但会导致12%内存带宽损失。
英伟达GPU被白帽黑客发现严重漏洞,通过Rowhammer攻击使大模型准确率直接降至0.02%,影响自动驾驶和医疗AI等应用。英伟达建议开启ECC防护措施但会导致12%内存带宽损失。

昂立教育同意收购上海育伦教育科技发展有限公司20%股权,由全资子公司上海新南洋教育科技有限公司以1336万元的价格收购。此次收购完成后,昂立教育将持有育伦教育100%股权。

一款名为Shortcut的AI工具能够一键分析Excel表格,处理复杂的金融建模任务。它不仅限于基础操作,还具备隐藏功能,如生成尤达图像等。不过,该工具在处理复杂数据和大型PDF时存在局限性。

2025年6月10日,OpenAI发布o3-pro模型并下调o3基础模型API价格。文章分析了o3-pro的技术优势、价格调整背后的动机以及如何理解OpenAI的产品线分化和竞争态势,强调技术优化与市场策略的重要性。

ZIP Lab和Monash团队提出ZPressor模块,通过信息瓶颈原理解决了前馈3D高斯泼溅模型的信息过载问题。该方法显著提升了实时渲染能力、推理时间和显存占用,并在多种基准数据集上提高了模型的鲁棒性和性能表现。
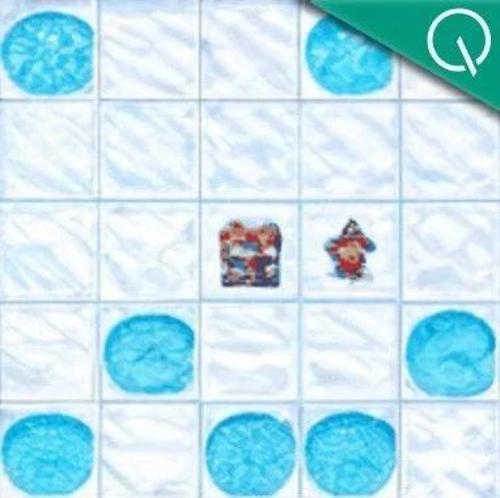
研究团队提出基于强化学习的视觉规划(VPRL)新范式,实现图像直接驱动推理,显著优于文本规划方法,未来有望推动多模态推理向更直观方向发展。

微软聘请前Meta首席创意官马克·达西担任Copilot创意总监,以强化品牌建设与产品设计,应对OpenAI、谷歌等对手的营销竞争。

4月10日,阿里巴巴创始人马云现身杭州阿里云谷园区。2009年成立的阿里云近期宣布收入达317.42亿元,并发布新模型聚焦推理和全模态融合。阿里的AI赛道持续加码,未来三年将投入超过3800亿元用于基础设施建设,同时加大对AI人才招聘力度。

