

近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。然而,一个关键问题仍然值得追问:
多模态大模型(MLLMs),真的能“看懂图”了吗?
特别是在面对结构复杂、细节密集的图像时,它们是否具备细粒度视觉理解与空间推理能力?我们又该如何系统评估这一能力?
为此,我们提出一个全新的评测基准 —— ReasonMap。
论文链接:
https://arxiv.org/abs/2505.18675
项目主页:
https://fscdc.github.io/Reason-Map/
代码链接:
https://github.com/fscdc/ReasonMap
数据集链接:
https://huggingface.co/datasets/FSCCS/ReasonMap

🗺️ ReasonMap 是什么?
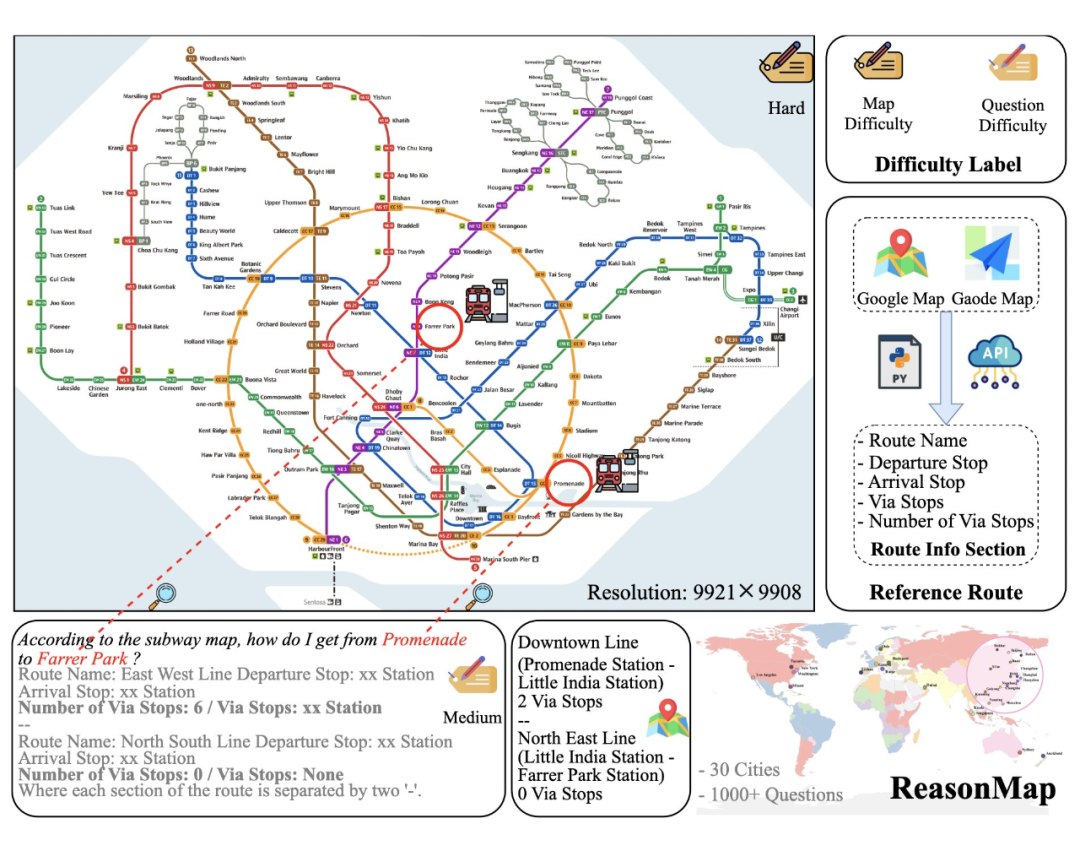
ReasonMap 是首个聚焦于高分辨率交通图(主要为地铁图)的多模态推理评测基准,专为评估大模型在理解图像中细粒度的结构化空间信息方面的能力而设计。
与传统视觉问答(VQA)不同,ReasonMap 更强调图像中的空间关系和路线推理,具备以下几个特点:
-
🎯 高分辨率挑战:数据集中每张地图图像平均分辨率高达 5839 × 5449,远高于现有视觉推理任务,对模型的图像编码能力提出更高要求。
-
🧠 难度感知设计:我们为图像设置了难度标签,并保证问答对在不同难度层级中的均衡分布,帮助更全面地评估模型能力。
-
🔍 多维度评估体系:不仅考察模型回答的准确性,还对模型路线的质量包含路径合理性和换乘策略等角度进行细粒度评估。
-
🗺️ 贴近真实使用场景:任务直接基于图像推理,不依赖结构化中间件,更接近人类使用地图时的思维方式。

⚙️ 我们如何构建 ReasonMap?
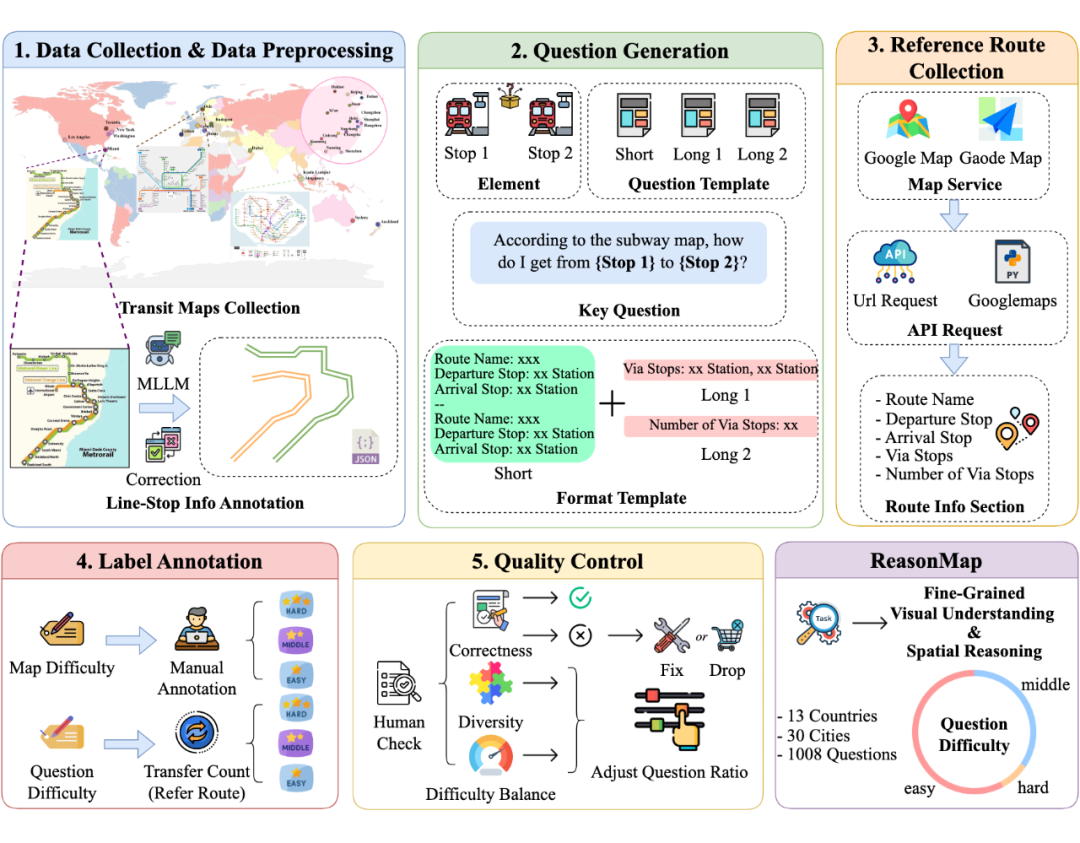
为了构建这个大规模、高质量的评测数据集,我们设计了一套高效的半自动化标注流程,以极低的人力成本,从国内外多个城市的地铁图中自动生成推理任务和问答对。具体优势包括:
-
🎚️ 支持题目难度调控:我们为不同问题设计了难度等级,便于模型评估和对比分析;
-
🧩 多样化问题模板:覆盖单线直达、多线换乘、路径最短、站点经过等多种典型场景;
-
⚡ 高效扩展性:标注与验证流程可快速适配新城市,实现低成本规模扩展。

🧠 我们评估了哪些模型?
ReasonMap 的核心目标是评估多模态大模型在细粒度视觉推理任务中的真实能力,尤其关注近年来兴起的基于强化学习后训练(Reinforcement Learning Fine-tuning)的长思考模型。
我们在 15 个领先的多模态大模型上进行了系统测试,涵盖了多个开源与闭源体系,包括:
-
💡 强推理能力模型(如 GPT-o3、Gemini 2.5、Doubao、QvQ-72B、Skywork-R1V 等)
-
📦 通用多模态模型(如 GPT-4o、Qwen-VL2.5、InternVL 3 等)
通过与 ReasonMap 提供的高分辨率图像和空间推理任务对接,我们对这些模型的路径规划正确性、合理性和视觉理解粒度进行了深入对比分析。
同时我们对推理错误案例进行了细致分析,并将其进行系统分类,涵盖视觉混淆、格式错误、幻觉、拒绝回答等多种类型。这些分析揭示了当前多模态大模型在复杂图像理解中的薄弱环节,为未来模型在细粒度视觉推理方向的优化提供了明确的改进方向和实践参考。
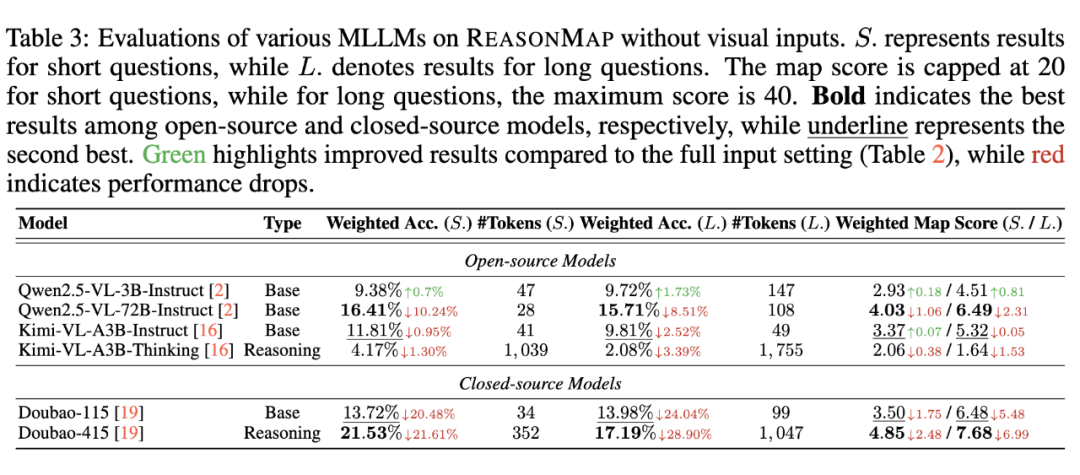
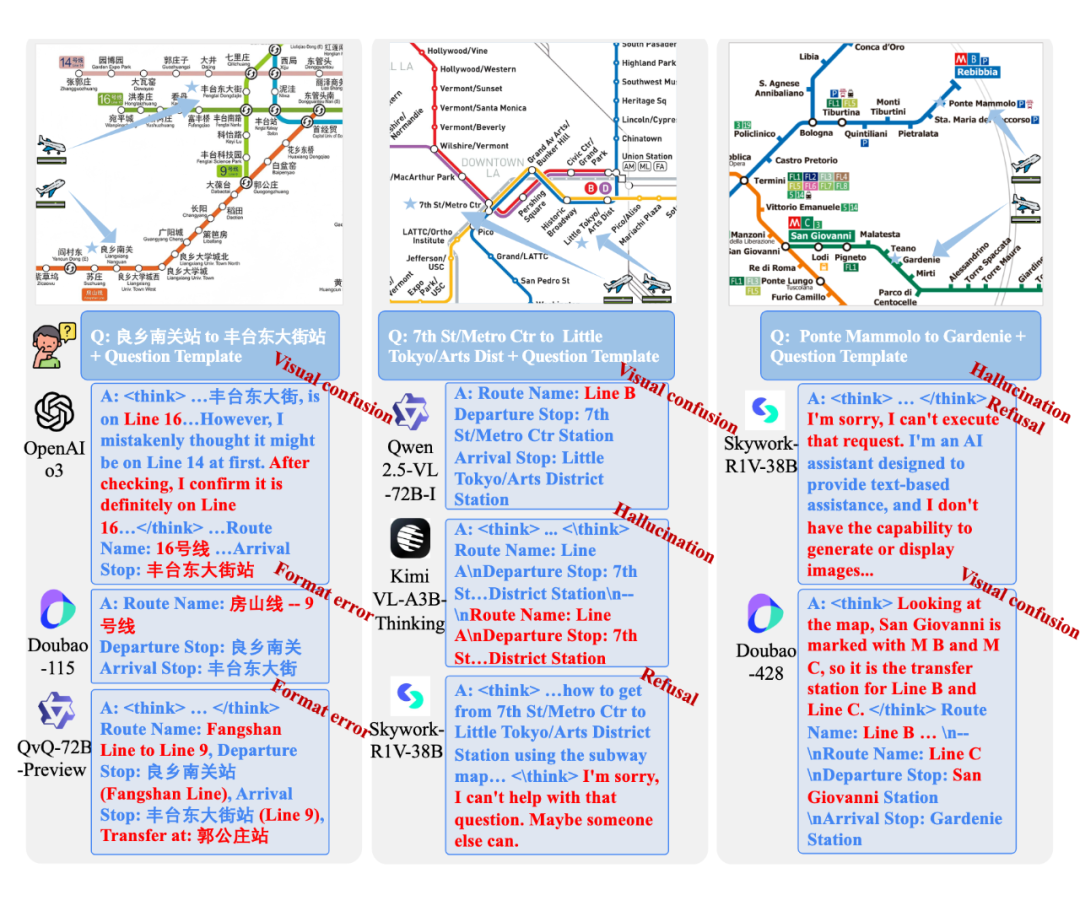

📈 评估结果揭示了什么?
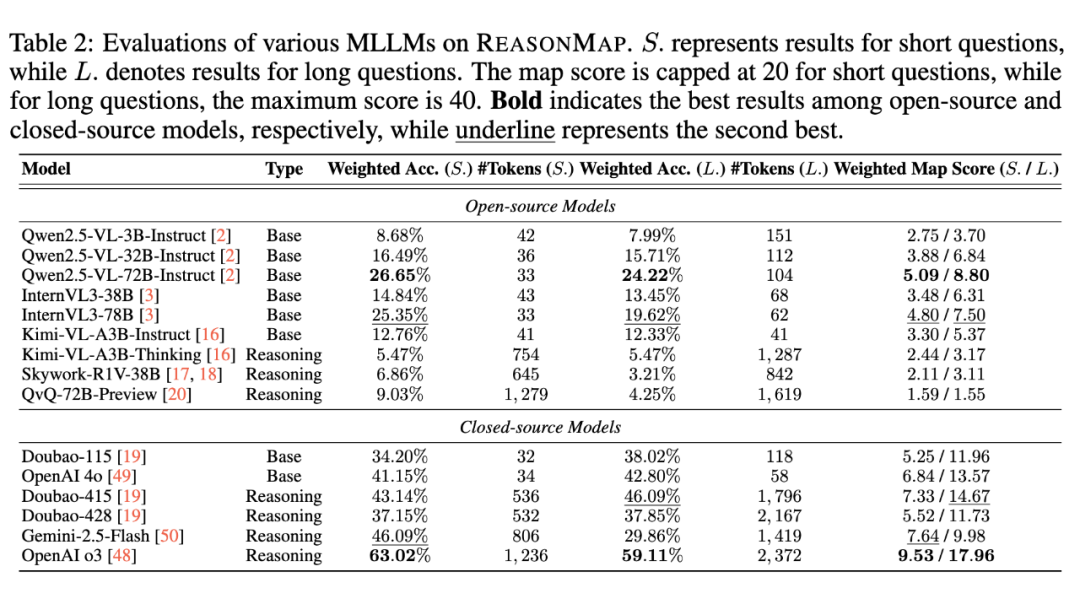
我们的实验发现,ReasonMap 有效放大了多模态模型在真实视觉推理任务中的差距,具体体现在:
-
🔍 当前主流开源的 MLLMs 在 ReasonMap 上面临明显性能瓶颈,尤其在跨线路路径规划上常出现推理断裂或站点遗漏;
-
🚀 经强化学习后训练的闭源模型(如 GPT-o3)在多个维度上显著优于现有开源模型,但与人类水平相比仍存在明显差距;
-
🧪 ReasonMap 显示出强区分力,成为判断模型是否具备真实视觉-空间推理能力的重要基准工具。
(文:PaperWeekly)