

刘宗凯 投稿
量子位 | 公众号 QbitAI
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
来自上海创智学院、上海AI Lab的MM-Eureka系列工作提出了新的强化学习算法CPGD(Clipped Policy Gradient Optimization with Policy Drift)——
相比于传统GRPO、RLOO等算法显著缓解了训练不稳定(甚至崩溃)的问题,并带来显著性能提升。
在多个基准测试上,使用GRPO训练的模型在QwenVL2.5-7B基础上平均提升了6%,而采用CPGD的MM-Eureka-CPGD-7B则进一步将整体提升幅度扩大到11%,验证了CPGD在稳定性与性能上的双重优势。
具体的,相较基础模型QwenVL2.5-7B,基于CPGD和15k多模态数学数据MMK12训练的模型MM-Eureka-CPGD-7B在MMK12测试集(包括数学,以及训练数据分布外领域的物理、化学、生物)上平均提升21.8%,在MathVista和MathVision等训练数据分布外领域上也分别提升8.5%与11.4%,展现了优异的泛化能力。
模型规模扩展到MM-Eureka-CPGD-32B上则进一步在MMK12测试集上超越了o1,值得注意的是,尽管MM-Eureka-CPGD-32B只在数学数据集上进行RL训练,但在物理、化学和生物等学科均超过了o1。
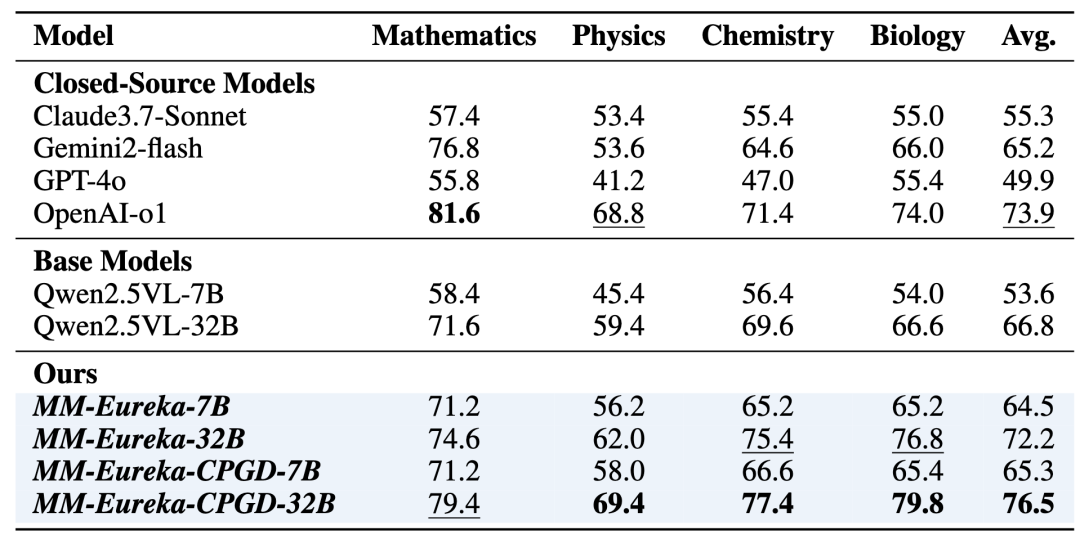
△不同模型在MMK12测试集中不同学科上的表现
今年2月,他们推出MM-Eureka系列是最早在多模态领域利用大规模Rule-based RL复现DeepSeek-R1关键能力(例如Visual aha-moment、稳定的回答长度增长)的工作之一,并将模型、代码、高质量多模态数据集MMK12、过程奖励模型MM-PRM全部开源,发布三个月以来获得了学术界和开源社区广泛关注——模型已被下载超10000次,相关代码库获得超1000 star,论文引用近100次。
近日,MM-Eureka系列工作在底层训练框架、高质量多模态推理数据、高效稳定的RL训练算法和过程奖励模型等方面持续耕耘,在近期取得重要进展。
多模态强化学习框架
基于OpenRLHF,团队构建了一个高效、可扩展的多模态强化学习框架,支持Qwen-VL、InternVL等多种模型与RL算法,包括GRPO、REINFORCE++、RLOO,以及提出的新型RL算法CPGD,并已成功训练出Qwen2.5VL-32B、InternVL2.5-38B等大型模型。
该框架相较于已有方案(如R1-V),具备更强的可扩展性与稳定性,为大规模多模态强化学习提供了基础设施支撑。
强化学习训练的稳定性突破:CPGD算法
在第一阶段的探索中,团队发现移除新策略与参考模型之间的KL散度项后,规则型强化学习训练在性能上限和资源效率方面表现更优。然而,这也极易导致训练过程不稳定甚至崩溃。
为此,团队在GRPO算法的基础上,提出了双边裁剪、online filter以及两阶段训练等应对方案,构建了MM-Eureka-7B与MM-Eureka-32B模型,并获得良好结果。
尽管上述方法在实践中有效,但仍存在繁琐且治标不治本的问题。团队在深入分析后发现,问题核心在于新旧策略比值的极端高值行为。
为此,他们提出新算法CPGD(Clipped Policy Gradient Optimization with Policy Drift),主要特性包括:
策略比值对数化处理:在原始PPO损失基础上,团队将策略比值取对数,以削弱异常高值的影响,使训练过程更稳定,解决了现有的规则型强化学习方法(如 GRPO、REINFORCE++、RLOO)常面临训练崩溃与梯度不稳定的问题。
引入策略漂移项(Policy Drift):在损失函数中引入新旧策略之间的KL散度项,有效约束策略变化幅度。团队证明了CPGD对策略漂移的控制能力优于PPO,并具有理论收敛性保障。
细粒度、可实现的损失函数形式:团队设计了按token粒度计算的损失函数,可拆分的裁剪项结合加权优势函数,既便于引入GRPO式归一化,也兼容online filter策略的等价加权方式。
新型KL估计器:在K3估计器基础上,团队构造了新的KL估计方式,以在保持梯度方向准确性的同时缓解高方差问题。
借助CPGD,团队成功训练出MM-Eureka-CPGD-7B/32B两个版本的推理模型,不仅显著提升了稳定性,还进一步提高了性能表现。
值得注意的是,近期Minimax发布的M1模型中提出的CISPO优化算法也提出了相应的训练不稳定瓶颈和基于policy gradient的改进方案,与在五月开源的CPGD算法有异曲同工之妙。
显著性能提升,泛化能力优越
在多个数据集上的测试表明,CPGD带来的性能提升显著:
-
相较基础模型QwenVL2.5-7B,MM-Eureka-CPGD-7B在 MMK12上提升21.8%,在MathVista和MathVision等训练数据分布外领域上也分别提升8.5%与11.4%,展现了较好的泛化能力;
-
对比主流强化学习算法(GRPO、REINFORCE++、RLOO等),CPGD在稳定性、性能和泛化能力上全面领先,;在多个基准测试上,使用GRPO训练的模型在QwenVL2.5-7B基础上平均提升了6%,而采用CPGD的MM-Eureka-CPGD-7B则进一步将整体提升幅度扩大到11%;
-
在与同规模开源模型对比中,MM-Eureka-CPGD-32B模型已接近闭源模型的表现。
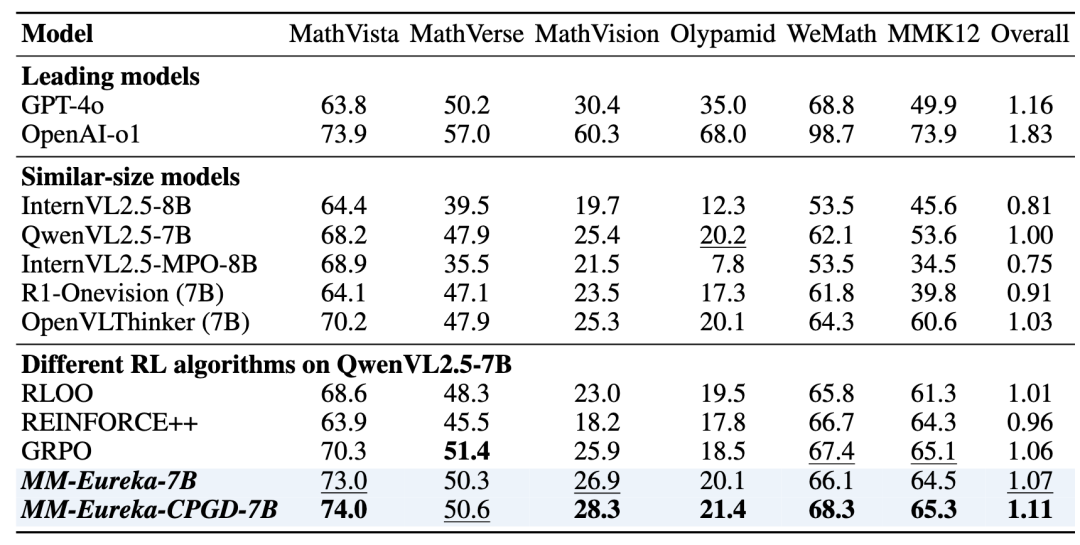
△不同模型的表现
其中Overall的计算是以QwenVL2.5-7B为基准。表现最佳的模型以粗体显示,第二好的模型以下划线显示(不包括OpenAI-o1/GPT-4o)
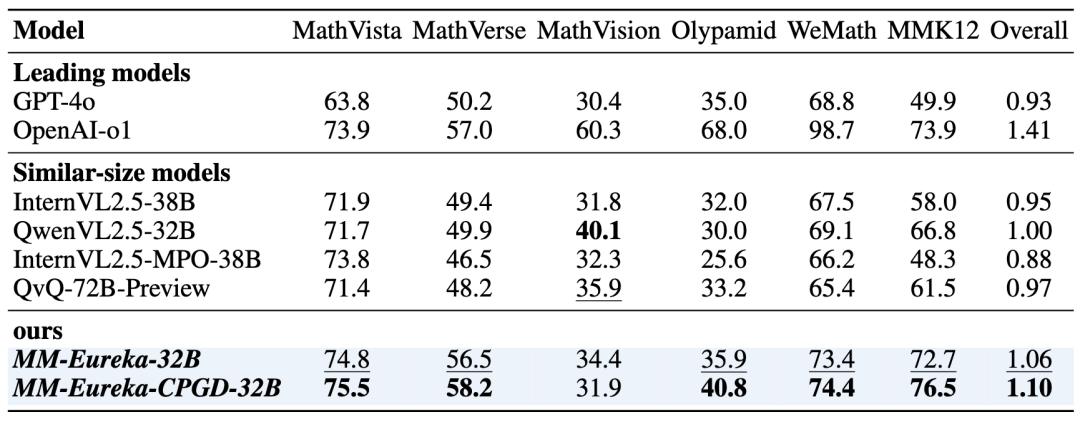
△不同模型的表现
其中Overall的计算是以QwenVL2.5-32B为基准。表现最佳的模型以粗体显示,第二好的模型以下划线显示(不包括OpenAI-o1/GPT-4o)
高质量多模态数学数据集MMK12
为解决现有数据集题型单一、答案不准的问题,团队推出了MMK12数据集,覆盖小学至高中阶段、总计超过15000道多模态数学推理题,涵盖几何、函数、图形推理等典型领域。
每道题都包含:
-
图文题干与配图; -
标准答案; -
结构化的思维链(Chain-of-Thought)解题过程。
评测集还额外提供了包含数学、物理、化学、生物等学科的2000道选择题,支持跨学科、多模态推理评测。目前,MMK12已被下载超1700 次,成为多模态推理任务中的重要基准。

MM-PRM:自动化过程监督,推理路径更可信
推理不应只关注最终答案,更重要的是每一步是否合理。为此,团队推出 MM-PRM(多模态过程奖励模型),关注模型“如何推理”的过程本身。
三阶段全自动过程监督流程:
使用500万条数据训练获得推理增强的MM-Policy模型;
结合MCTS自动生成超过70万条推理过程标注;
基于上述数据训练过程奖励模型MM-PRM,对每一步推理进行评估与引导。
它具备以下优势:
-
高效生成,无需人工标注:仅用1万道K12数学题,即可生成大规模过程监督数据;
-
显著提升推理路径质量:模型推理步骤更加严谨,而非仅靠“撞对”答案;
-
跨任务泛化性强:在MMK12准确率提升近9%,在MathVista、OlympiadBench等挑战集上同样表现优异;
-
全模型适用:适配从8B到78B的多种规模模型;
-
训练稳定性强:结合小学习率与软标签策略,有效降低训练崩溃风险。
对强化学习与推理能力的思考
推理能力能否脱离知识独立发展?
团队观察到:强化学习显著提高了模型在“曾经答对过”的问题上的表现,但对“始终无法答对”的问题,效果有限。这表明RL主要在优化已有知识调用和推理路径的组织上发挥作用,但无法替代知识本身的缺失。
RL比SFT泛化能力更强
通过实验,他们发现RL在跨学科任务(如物理、化学、生物)中的泛化能力远超SFT或CoT-SFT。以数学与物理为例,RL分别带来12.8和10.8 分的提升,而其他方法几乎无效。这进一步说明,强化学习可能是提升模型逻辑推理能力的关键路径。
PRM与RL的结合具备潜力,值得进一步探索
目前的强化学习训练多聚焦于最终答案的准确性,尚未充分利用推理过程中的中间监督信号。团队认为,PRM有望成为强化学习训练的重要补充。通过对模型每一步推理过程的打分与引导,PRM可以提供更细粒度的反馈,帮助模型在策略优化中更稳定地提升推理质量与可解释性。未来,团队计划探索将PRM与RL框架相结合,以构建“结果+过程”双重优化的多模态推理体系。这不仅有助于提升模型在复杂推理任务中的稳健性,也可能为构建可控、安全的通用推理能力奠定基础。
他们在策略优化与过程监督两个核心方向,分别推出MM-Eureka-CPGD 与MM-PRM,构建了一套高度自动化、可复现、训练稳定、效果显著的多模态推理方案。
该方案实现了准确率与推理长度的稳定提升;推理路径的可控化与解释性增强,以及在多个任务与模型规模上的广泛适配与泛化能力。
目前已开源所有模型、代码与数据,并提供完整技术报告,欢迎社区参与共建。未来,团队将持续推进更高水平的多模态推理训练与系统化优化,敬请关注!
开源代码:
https://github.com/ModalMinds/MM-EUREKA
https://github.com/ModalMinds/MM-EUREKA/tree/mm-prm
技术报告:
https://arxiv.org/abs/2503.07365
https://arxiv.org/abs/2505.12504
https://arxiv.org/abs/2505.13427
MMK12数据集:
https://huggingface.co/datasets/FanqingM/MMK12
模型权重:
https://huggingface.co/FanqingM/MM-Eureka-Qwen-7B
https://huggingface.co/FanqingM/MM-Eureka-Qwen-32B
https://huggingface.co/Zkkkai/CPGD-7B
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)